






17
Apr
生成扩散模型漫谈(二十三):信噪比与大图生成(下)
By 苏剑林 | 2024-04-17 | 20646位读者 | 引用上一篇文章《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》中,我们介绍了通过对齐低分辨率的信噪比来改进noise schedule,从而改善直接在像素空间训练的高分辨率图像生成(大图生成)的扩散模型效果。而这篇文章的主角同样是信噪比和大图生成,但做到了更加让人惊叹的事情——直接将训练好低分辨率图像的扩散模型用于高分辨率图像生成,不用额外的训练,并且效果和推理成本都媲美直接训练的大图模型!
这个工作出自最近的论文《Upsample Guidance: Scale Up Diffusion Models without Training》,它巧妙地将低分辨率模型上采样作为引导信号,并结合了CNN对纹理细节的平移不变性,成功实现了免训练高分辨率图像生成。
思想探讨
我们知道,扩散模型的训练目标是去噪(Denoise,也是DDPM的第一个D)。按我们的直觉,去噪这个任务应该是分辨率无关的,换句话说,理想情况下低分辨率图像训练的去噪模型应该也能用于高分辨率图像去噪,从而低分辨率的扩散模型应该也能直接用于高分辨率图像生成。
31
Oct
简单得令人尴尬的FSQ:“四舍五入”超越了VQ-VAE
By 苏剑林 | 2023-10-31 | 58034位读者 | 引用正如“XXX is all you need”一样,有不少论文都以“简单得令人尴尬”命名(An Embarrassingly Simple XXX),但在笔者看来,这些论文大多数都是噱头多于实力。不过,笔者最近阅读到的一篇论文,真的让人不由得发出“简单得令人尴尬”的感叹~
论文的标题是《Finite Scalar Quantization: VQ-VAE Made Simple》,顾名思义,这是一篇旨在用FSQ(Finite Scalar Quantization)简化VQ-VAE的工作。随着生成模型、多模态LLM的逐渐流行,VQ-VAE及其后续工作也作为“图像的Tokenizer”而“水涨船高”。然而,VQ-VAE的训练本身也存在一些问题,而FSQ这篇论文则声称通过更简单的“四舍五入”就可以达到同样的目的,并且有着效果更好、收敛更快、训练更稳的优点。
FSQ真有这么神奇?接下来我们一起学习一下。
VQ
首先,我们来了解一下“VQ”。VQ全称是“Vector Quantize”,可以翻译为“向量量子化”或者“向量量化”,是指将无限、连续的编码向量映射为有限、离散的整数数字的一种技术。如果我们将VQ应用在自编码器的中间层,那么可以在压缩输入大小的同时,让编码结果成为一个离散的整数序列。
7
Sep
BytePiece:更纯粹、更高压缩率的Tokenizer
By 苏剑林 | 2023-09-07 | 40780位读者 | 引用目前在LLM中最流行的Tokenizer(分词器)应该是Google的SentencePiece了,因为它符合Tokenizer的一些理想特性,比如语言无关、数据驱动等,并且由于它是C++写的,所以Tokenize(分词)的速度很快,非常适合追求效率的场景。然而,它也有一些明显的缺点,比如训练速度慢(BPE算法)、占用内存大等,同时也正因为它是C++写的,对于多数用户来说它就是黑箱,也不方便研究和二次开发。
事实上,Tokenizer的训练就相当于以往的“新词发现”,而笔者之前也写过中文分词和最小熵系列文章,对新词发现也有一定的积累,所以很早之前就有自己写一版Tokenizer的想法。这几天总算腾出了时间初步完成了这件事情,东施效颦SentencePiece,命名为“BytePiece”。
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 22798位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
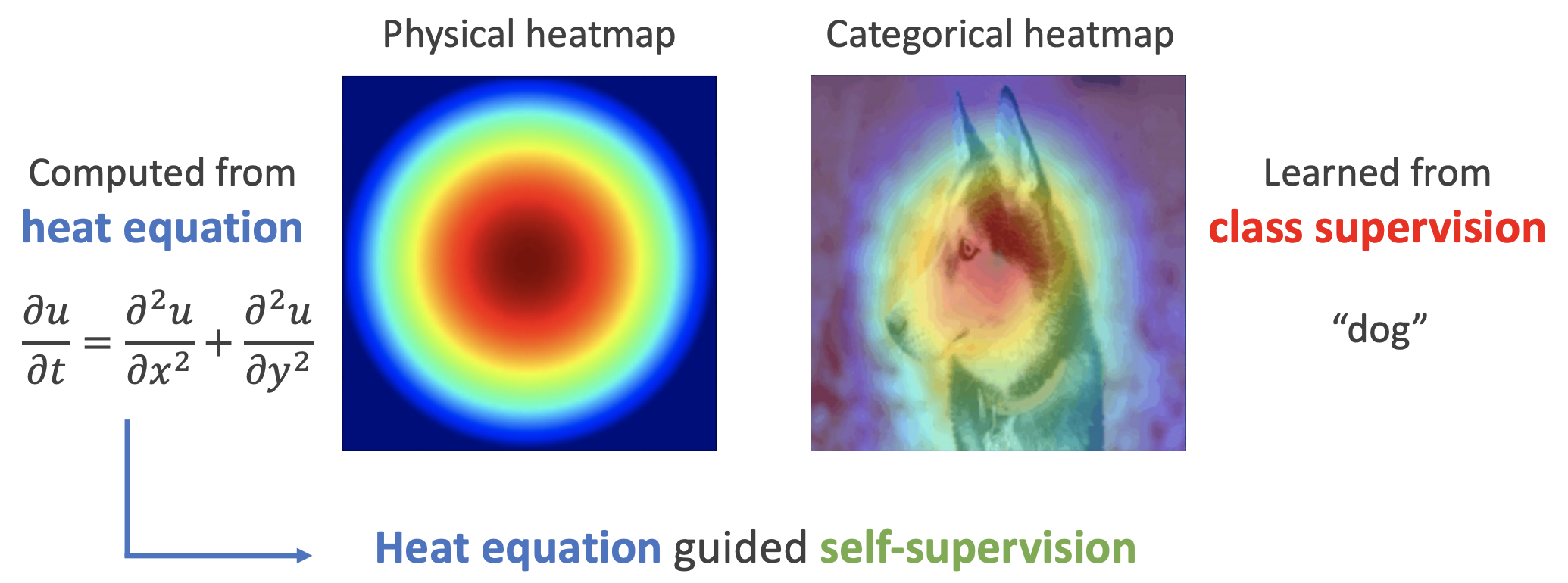
热方程的热力图(左)和视觉模型的热力图(右)
15
Nov
WGAN新方案:通过梯度归一化来实现L约束
By 苏剑林 | 2021-11-15 | 46992位读者 | 引用当前,WGAN主流的实现方式包括参数裁剪(Weight Clipping)、谱归一化(Spectral Normalization)、梯度惩罚(Gradient Penalty),本来则来介绍一种新的实现方案:梯度归一化(Gradient Normalization),该方案出自两篇有意思的论文,分别是《Gradient Normalization for Generative Adversarial Networks》和《GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks》。
有意思在什么地方呢?从标题可以看到,这两篇论文应该是高度重合的,甚至应该是同一作者的。但事实上,这是两篇不同团队的、大致是同一时期的论文,一篇中了ICCV,一篇中了WACV,它们基于同样的假设推出了几乎一样的解决方案,内容重合度之高让我一直以为是同一篇论文。果然是巧合无处不在啊~
10
Sep
曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果
By 苏剑林 | 2021-09-10 | 48700位读者 | 引用在五花八门的预训练任务设计中,NSP通常认为是比较糟糕的一种,因为它难度较低,加入到预训练中并没有使下游任务微调时有明显受益,甚至RoBERTa的论文显示它会带来负面效果。所以,后续的预训练工作一般有两种选择:一是像RoBERTa一样干脆去掉NSP任务,二是像ALBERT一样想办法提高NSP的难度。也就是说,一直以来NSP都是比较“让人嫌弃”的。
不过,反转来了,NSP可能要“翻身”了。最近的一篇论文《NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction》(下面简称NSP-BERT)显示NSP居然也可以做到非常不错的Zero Shot效果!这又是一个基于模版(Prompt)的Few/Zero Shot的经典案例,只不过这一次的主角是NSP。
背景回顾
曾经我们认为预训练纯粹就是预训练,它只是为下游任务的训练提供更好的初始化,像BERT的预训练任务有MLM(Masked Language Model和NSP(Next Sentence Prediction),在相当长的一段时间内,大家都不关心这两个预训练任务本身,而只是专注于如何通过微调来使得下游任务获得更好的性能。哪怕是T5将模型参数训练到了110亿,走的依然是“预训练+微调”这一路线。
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 61493位读者 | 引用
17
May
变分自编码器(七):球面上的VAE(vMF-VAE)
By 苏剑林 | 2021-05-17 | 108453位读者 | 引用在《变分自编码器(五):VAE + BN = 更好的VAE》中,我们讲到了NLP中训练VAE时常见的KL散度消失现象,并且提到了通过BN来使得KL散度项有一个正的下界,从而保证KL散度项不会消失。事实上,早在2018年的时候,就有类似思想的工作就被提出了,它们是通过在VAE中改用新的先验分布和后验分布,来使得KL散度项有一个正的下界。
该思路出现在2018年的两篇相近的论文中,分别是《Hyperspherical Variational Auto-Encoders》和《Spherical Latent Spaces for Stable Variational Autoencoders》,它们都是用定义在超球面的von Mises–Fisher(vMF)分布来构建先后验分布。某种程度上来说,该分布比我们常用的高斯分布还更简单和有趣~
KL散度消失
我们知道,VAE的训练目标是
\begin{equation}\mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \Big[\mathbb{E}_{z\sim p(z|x)}\big[-\log q(x|z)\big]+KL\big(p(z|x)\big\Vert q(z)\big)\Big]
\end{equation}

最近评论