






10
Sep
曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果
By 苏剑林 | 2021-09-10 | 73514位读者 |在五花八门的预训练任务设计中,NSP通常认为是比较糟糕的一种,因为它难度较低,加入到预训练中并没有使下游任务微调时有明显受益,甚至RoBERTa的论文显示它会带来负面效果。所以,后续的预训练工作一般有两种选择:一是像RoBERTa一样干脆去掉NSP任务,二是像ALBERT一样想办法提高NSP的难度。也就是说,一直以来NSP都是比较“让人嫌弃”的。
不过,反转来了,NSP可能要“翻身”了。最近的一篇论文《NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction》(下面简称NSP-BERT)显示NSP居然也可以做到非常不错的Zero Shot效果!这又是一个基于模版(Prompt)的Few/Zero Shot的经典案例,只不过这一次的主角是NSP。
背景回顾 #
曾经我们认为预训练纯粹就是预训练,它只是为下游任务的训练提供更好的初始化,像BERT的预训练任务有MLM(Masked Language Model和NSP(Next Sentence Prediction),在相当长的一段时间内,大家都不关心这两个预训练任务本身,而只是专注于如何通过微调来使得下游任务获得更好的性能。哪怕是T5将模型参数训练到了110亿,走的依然是“预训练+微调”这一路线。
首先有力地打破我们这个思维定式的,当属去年发布的GPT3,它显示在足够大的预训练模型下,我们可以设计特定的模版,使得不进行微调就可以起到很好的Few/Zero Shot效果。有GPT的地方,BERT从来不会缺席,既然GPT可以,那么BERT应该也行,这就导致了后来的PET工作,它同样构建特别的模版,利用预训练的MLM模型来做Few/Zero Shot,还不了解的读者可以参考《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》。
自此,“预训练+模版”的工作逐渐增多,现在甚至有“爆发”之势,这系列工作现在大致都统称“Prompt-based Language Models”,随便搜搜就可以找到很多。如今,大家已经形成了一个共识:构建适当的Prompt,使得下游任务的形式跟预训练任务更贴近,通常能获得更好的效果。所以如何构建Prompt,便是这系列工作的重点之一,比如P-tuning就是其中的经典工作(参考《P-tuning:自动构建模版,释放语言模型潜能》)。
NSP入场 #
仔细观察一下Prompt-based的相关工作就会发现,当前主要的内容都是研究如何更好地利用预训练好的GPT、MLM或者Encoder-Decoder模型,鲜有关注其余预训练任务的。而NSP-BERT这个工作,则充分挖掘了NSP任务的潜力,并且启发我们哪怕局限在Prompt-based,其研究思路还有很大的发散空间。
所谓NSP任务,并不是真的去预测下一句,而是给定两个句子,判断这两个句子是否相邻。相应地,NSP-BERT的思路其实很简单,以分类问题为例,就是把输入视为第一句,然后将每个候选类别添加特定的Prompt作为第二句,逐一判断第一句与哪个第二句更加连贯。可以发现NSP-BERT思路跟PET很相似,其实Prompt-based的工作都很容易理解,难的是如何首先想到这样做。
下图演示了NSP-BERT做常见的一些NLU任务的参考Prompt方案,可以看到NSP-BERT能做到任务还是不少的:
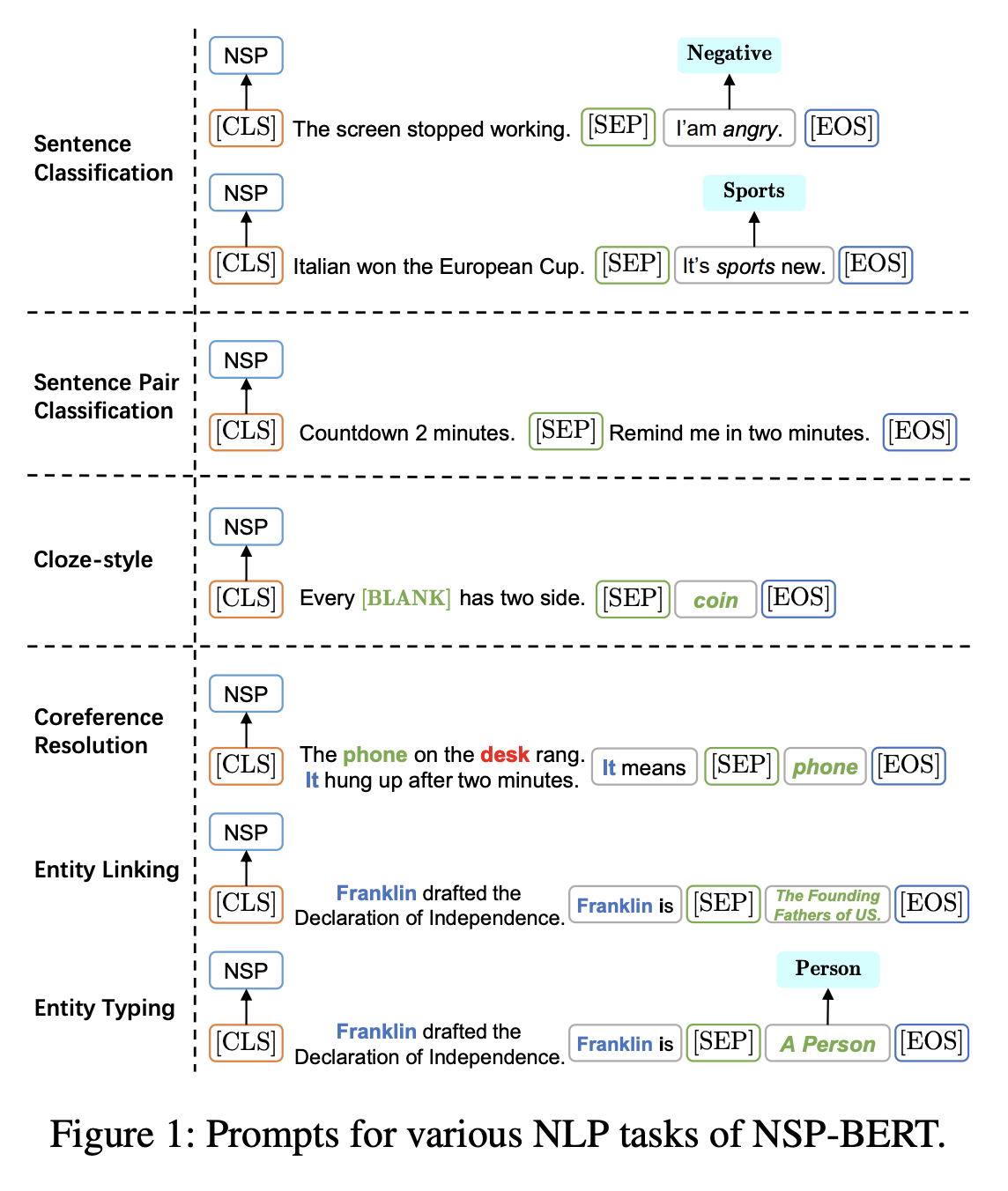
NSP-BERT做常见NLU任务的一些Prompt
其实看完这张图,就已经了解了NSP-BERT的大部分思想了,论文的其他部分,只不过是对这张图的细节进行展开描述而已。想要深入了解的同学,自行仔细阅读原论文即可。
如果说NSP-BERT这个模式,倒不是第一次出现,早前就有人提出用NLI模型来做Zero Shot的(参考《NLI Models as Zero-Shot Classifiers》),它的格式跟NSP是基本一致的,但需要标签语料有监督地微调,而纯无监督的NSP的利用,这还是第一次尝试。
实验效果 #
有意思的是,对于我们来说,NSP-BERT是非常“接地气”的良心工作。比如,它是中国人写的,它的实验任务都是中文的(FewCLUE和DuEL2.0),并且开源了代码。下面是作者开源地址:
最重要的是,NSP-BERT的效果真的不错:

NSP-BERT的Zero Shot效果
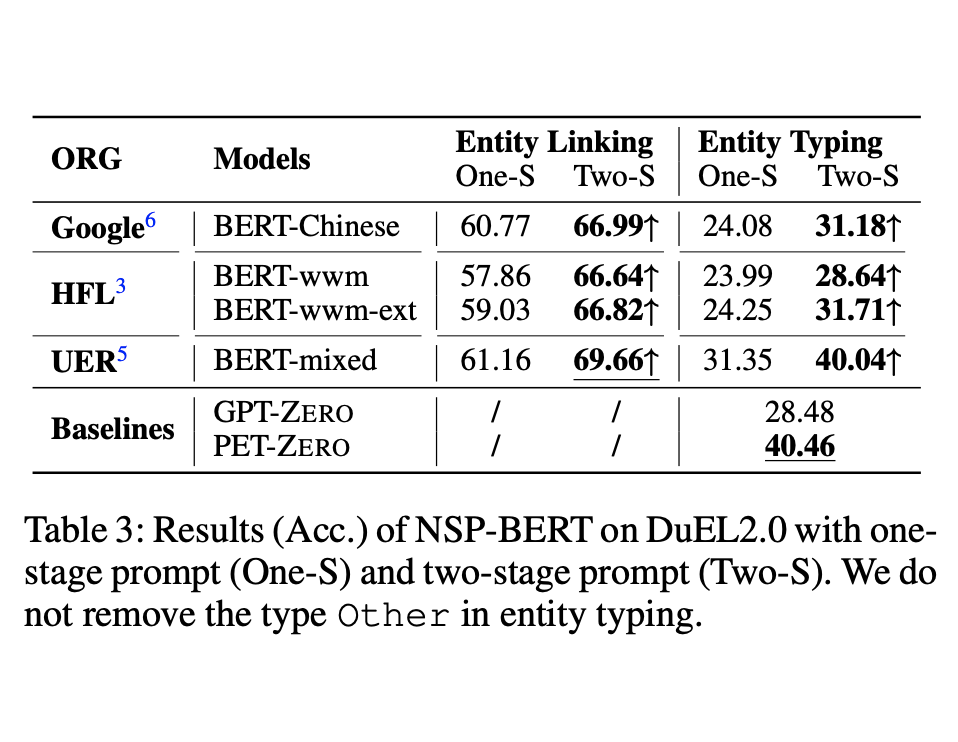
在实体链接任务上的效果
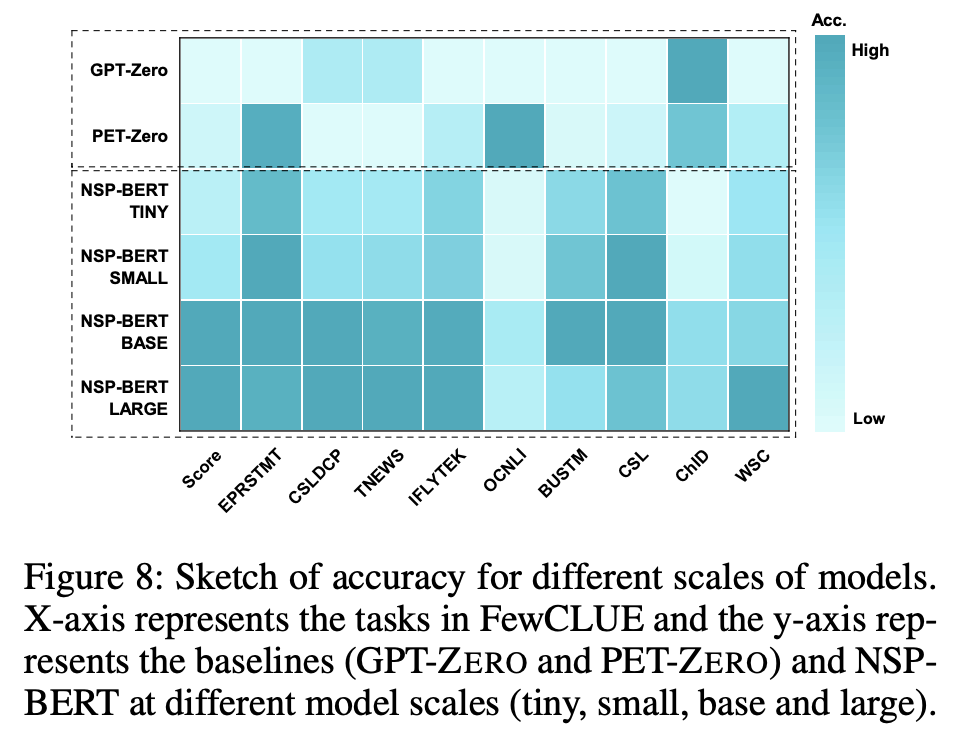
模型规模对效果的影响
总的来说,看完这些实验结果后,笔者只向对NSP说一句“失敬失敬”,这么一位模型界的大佬在面前,但却一直没有意识到,这必须得为NSP-BERT的作者的观察力点赞了。
文章小结 #
本文分享了用BERT的预训练任务NSP来做Zero Shot的一篇论文,论文结果显示用NSP来做Zero Shot也能做到非常优秀的效果,也许假以时日,NSP要“崛起”了。
转载到请包括本文地址:https://kexue.fm/archives/8671
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 10, 2021). 《曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果 》[Blog post]. Retrieved from https://kexue.fm/archives/8671
@online{kexuefm-8671,
title={曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果},
author={苏剑林},
year={2021},
month={Sep},
url={\url{https://kexue.fm/archives/8671}},
}

September 11th, 2021
苏神教师节也不休息呀!
September 17th, 2021
苏神好,我好奇的是,该模型训练的过程只需要将input改成相应的pattern,然后让对应的NSP概率越大越好就OK吗?也不需要做MLM任务了吗?而 inference阶段,只需要将对应的所有的可能的label都试一遍,然后看那个NSP概率大就可以吗?嗯~~~
基本对。但需不需要做mlm,这个还得测测,我也不确定。感觉就算不需要做mlm,可能还需要混合一些普通的NSP语料对,不能只靠标注语料构建出来的吧
好的,感谢,得扣扣源码了感觉
October 29th, 2021
思路感觉很赞,但是实施起来感觉稍有问题。因为NSP毕竟是一个二分类任务,如果要用它做ZSL的多分类,那不是要一堆模板不停推断么,如果是100分类,那至少要推断100次?
而MLM做ZSL就方便多了,因为对masked位置的推断是token size的分类,向量空间明显更宽广更容易玩儿出各种花样
NSP看似成本大,但相比之下,你finetune一个large模型成本更大(可能要large才能达到同样的效果);而且就算是PET的原始论文,都是多个不同的prompt然后模型融合来提升效果的,同样是一条样本要预测多次。
事实上,这类prompt-based方法直接上线都是不现实的,理想情况下就是用它来构建伪标签数据,然后训练一个简单模型。
November 20th, 2022
[...]前段时间看到苏神介绍一篇文章:《曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果》,介绍的这个工作是叫NSP-BERT,可是在我看来,其结论并不能为NSP正名,NSP-BERT有效,是因为prompt有效,这与NSP有效是两码事,NSP是sequence pair的一种,但是不能代表整个sequence pair类的任务。[...]