






21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 112322位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
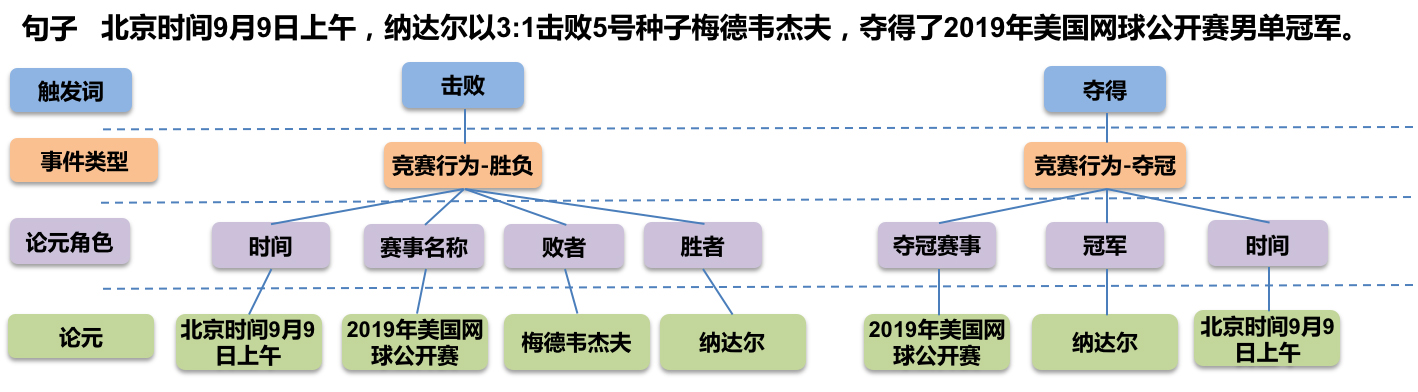
标准的事件抽取样本(图片来自百度DuEE的GitHub)
30
Jan
GPLinker:基于GlobalPointer的实体关系联合抽取
By 苏剑林 | 2022-01-30 | 185031位读者 | 引用在将近三年前的百度“2019语言与智能技术竞赛”(下称LIC2019)中,笔者提出了一个新的关系抽取模型(参考《基于DGCNN和概率图的轻量级信息抽取模型》),后被进一步发表和命名为“CasRel”,算是当时关系抽取的SOTA。然而,CasRel提出时笔者其实也是首次接触该领域,所以现在看来CasRel仍有诸多不完善之处,笔者后面也有想过要进一步完善它,但也没想到特别好的设计。
后来,笔者提出了GlobalPointer以及近日的Efficient GlobalPointer,感觉有足够的“材料”来构建新的关系抽取模型了。于是笔者从概率图思想出发,参考了CasRel之后的一些SOTA设计,最终得到了一版类似TPLinker的模型。
基础思路
关系抽取乍看之下是三元组$(s,p,o)$(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”$(s_h,s_t,p,o_h,o_t)$的抽取,其中$s_h,s_t$分别是$s$的首、尾位置,而$o_h,o_t$则分别是$o$的首、尾位置。
25
Jan
Efficient GlobalPointer:少点参数,多点效果
By 苏剑林 | 2022-01-25 | 193398位读者 | 引用在《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》中,我们提出了名为“GlobalPointer”的token-pair识别模块,当它用于NER时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比CRF更快的速度和不逊色于CRF的效果。换言之,就目前的实验结果来看,至少在NER场景,我们可以放心地将CRF替换为GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出GlobalPointer的一个改进版——Efficient GlobalPointer,它主要针对原GlobalPointer参数利用率不高的问题进行改进,明显降低了GlobalPointer的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的Efficient GlobalPointer反而还取得更好的效果。
大量的参数
这里简单回顾一下GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。简单来说,GlobalPointer是基于内积的token-pair识别模块,它可以用于NER场景,因为对于NER来说我们只需要把每一类实体的“(首, 尾)”这样的token-pair识别出来就行了。
10
Sep
曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果
By 苏剑林 | 2021-09-10 | 73511位读者 | 引用在五花八门的预训练任务设计中,NSP通常认为是比较糟糕的一种,因为它难度较低,加入到预训练中并没有使下游任务微调时有明显受益,甚至RoBERTa的论文显示它会带来负面效果。所以,后续的预训练工作一般有两种选择:一是像RoBERTa一样干脆去掉NSP任务,二是像ALBERT一样想办法提高NSP的难度。也就是说,一直以来NSP都是比较“让人嫌弃”的。
不过,反转来了,NSP可能要“翻身”了。最近的一篇论文《NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction》(下面简称NSP-BERT)显示NSP居然也可以做到非常不错的Zero Shot效果!这又是一个基于模版(Prompt)的Few/Zero Shot的经典案例,只不过这一次的主角是NSP。
背景回顾
曾经我们认为预训练纯粹就是预训练,它只是为下游任务的训练提供更好的初始化,像BERT的预训练任务有MLM(Masked Language Model和NSP(Next Sentence Prediction),在相当长的一段时间内,大家都不关心这两个预训练任务本身,而只是专注于如何通过微调来使得下游任务获得更好的性能。哪怕是T5将模型参数训练到了110亿,走的依然是“预训练+微调”这一路线。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 528964位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
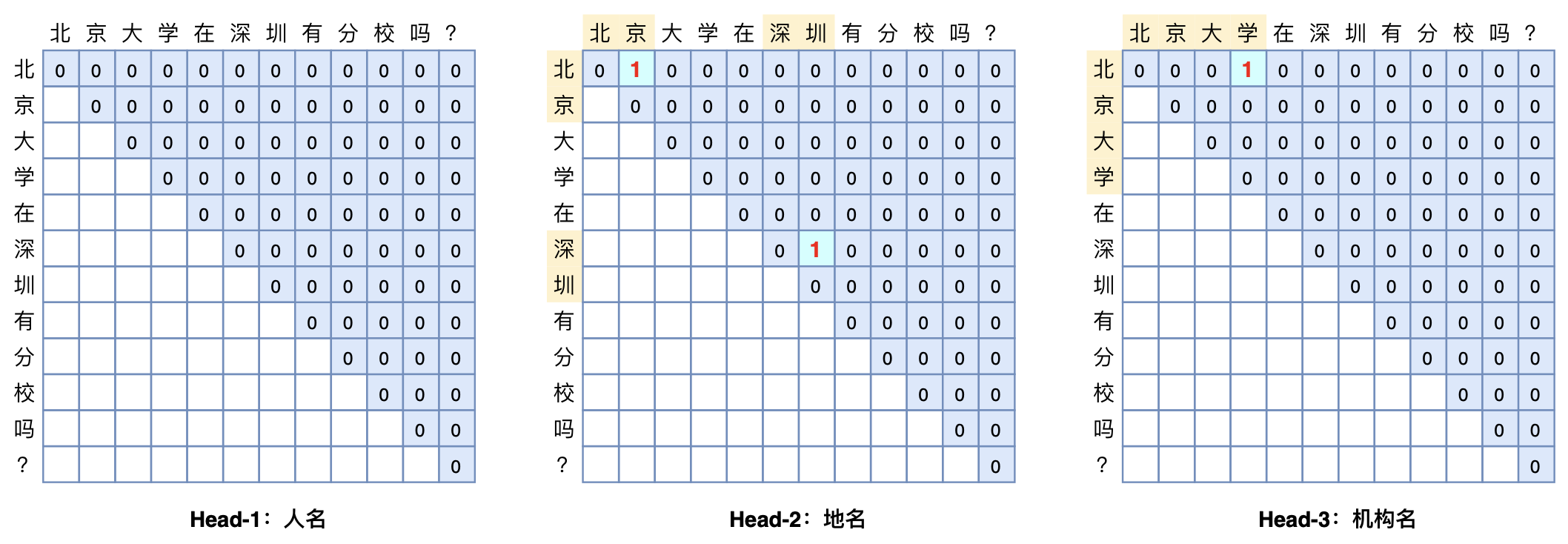
GlobalPointer多头识别嵌套实体示意图
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 236627位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
9
Feb
一个二值化词向量模型,是怎么跟果蝇搭上关系的?
By 苏剑林 | 2021-02-09 | 38558位读者 | 引用
果蝇(图片来自Google搜索)
可能有些读者最近会留意到ICLR 2021的论文《Can a Fruit Fly Learn Word Embeddings?》,文中写到它是基于仿生思想(仿果蝇的嗅觉回路)做出来的一个二值化词向量模型。其实论文的算法部分并不算难读,可能整篇论文读下来大家的最主要疑惑就是“这东西跟果蝇有什么关系?”、“作者真是从果蝇里边受到启发的?”等等。本文就让我们来追寻一下该算法的来龙去脉,试图回答一下这个词向量模型是怎么跟果蝇搭上关系的。
BioWord
原论文并没有给该词向量模型起个名字,为了称呼上的方便,这里笔者就自作主张将其称为“BioWord”了。总的来说,论文内容大体上有三部分:
1、给每个n-gram构建了一个词袋表示向量;
2、对这些n-gram向量执行BioHash算法,得到所谓的(二值化的)静态/动态词向量;
3、“拼命”讲了一个故事。
27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 234230位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
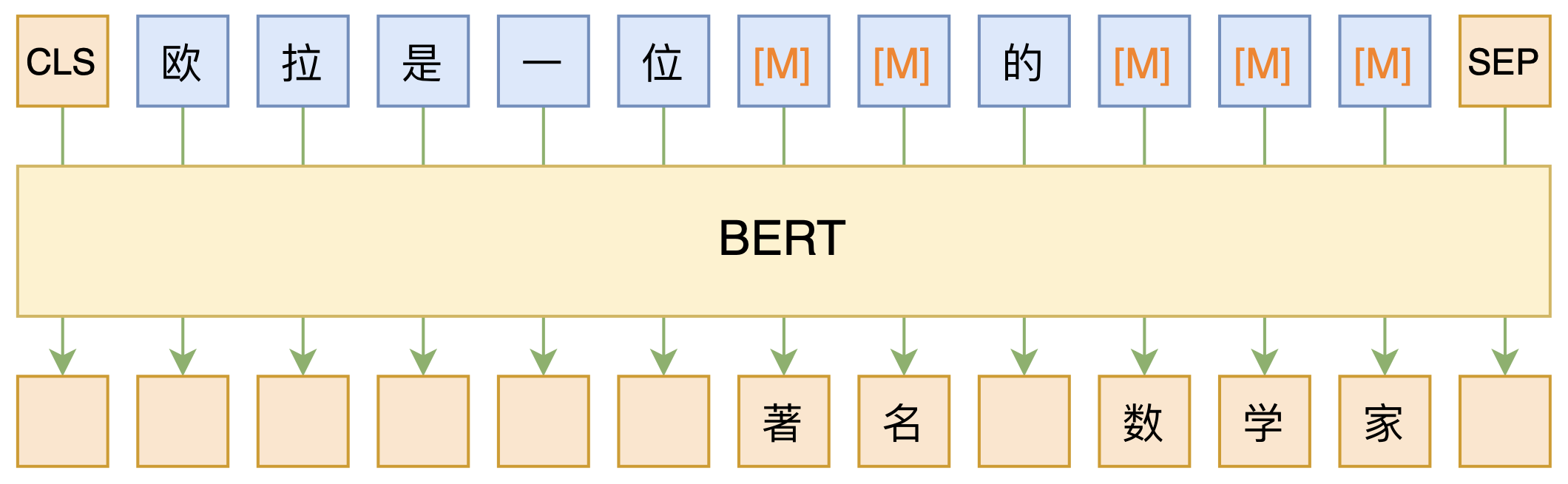
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。

最近评论