






19
Mar
Attention Residuals 回忆录
By 苏剑林 | 2026-03-19 | 21620位读者 | 引用这篇文章介绍我们的一个最新作品Attention Residuals(AttnRes),顾名思义,这是用Attention的思路去改进Residuals。
不少读者应该都听说过Pre Norm/Post Norm之争,但这说到底只是Residuals本身的“内斗”,包括后来很多Normalization的变化都是如此。比较有意思的变化是HC,它开始走扩大残差流的路线,但也许是效果上的不稳定,并没有引起太多反响。后来的故事大家可能都知道了,去年底DeepSeek的mHC改进了HC,并在更大规模实验上验证了它的有效性。
相比于进一步扩大残差流,我们选择了另一条激进的路线:直接在层间做Attention来替代Residuals。当然,全流程走通还是有很多细节和工作的,这里就简单回忆一下相关的心路历程。

AttnRes示意图
26
Jan
DeltaNet的核心逆矩阵的元素总是在[-1, 1]内
By 苏剑林 | 2026-01-26 | 4045位读者 | 引用从《线性注意力简史:从模仿、创新到反哺》中我们可以看到,DeltaNet的并行形式涉及到了形如$(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}$的逆矩阵。近日读者 @Arch123 提出,通过实验可观察到该逆矩阵的元素总是在$[-1, 1]$内,问是否可以从数学上证实或证伪它。
在这篇文章中,我们将通过两种不同的方式证明这个结论是严格成立的。
问题描述
首先,我们准确地重述一下问题。设有矩阵$\boldsymbol{K}=[\boldsymbol{k}_1,\boldsymbol{k}_2,\cdots,\boldsymbol{k}_n]^{\top}\in\mathbb{R}^{n\times d}$,其中每个$\boldsymbol{k}_i\in\mathbb{R}^{d\times 1}$是模长不超过1的列向量,$\boldsymbol{M}\in\mathbb{R}^{n\times n}$是一个下三角的掩码矩阵,定义为
\begin{equation}M_{i,j} = \left\{\begin{aligned} &1, &i \geq j \\ &0, &i < j\end{aligned}\right.\end{equation}
$\boldsymbol{I}$是单位阵,$\boldsymbol{M}^- = \boldsymbol{M} - \boldsymbol{I}$。我们要证明的是:
\begin{equation}(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot \boldsymbol{M}^-)^{-1}\quad\in\quad [-1, 1]^{n\times n}\end{equation}
23
Dec
为什么DeltaNet要加L2 Normalize?
By 苏剑林 | 2025-12-23 | 9846位读者 | 引用在文章《线性注意力简史:从模仿、创新到反哺》中,我们介绍了DeltaNet,它把Delta Rule带进了线性注意力中,成为其强有力的工具之一,并构成GDN、KDA等后续工作的基础。不过,那篇文章我们主要着重于DeltaNet的整体思想,并未涉及到太多技术细节——这篇文章我们来讨论其中之一:DeltaNet及其后续工作都给$\boldsymbol{Q}、\boldsymbol{K}$加上了L2 Normalize,这是为什么呢?
当然,直接从特征值的角度解释这一操作并不困难,但个人总感觉还差点意思。前几天笔者在论文《Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics》学习到了一个新理解,感觉也有可取之处,特来分享一波。
27
Oct
低精度Attention可能存在有偏的舍入误差
By 苏剑林 | 2025-10-27 | 35897位读者 | 引用前段时间笔者在arXiv上刷到了论文《Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention》,里面描述的实验现象跟我们在训练Kimi K2时出现的一些现象很吻合,比如都是第二层Attention开始出现问题。论文将其归因为低精度Attention固有的有偏误差,这个分析角度是比较出乎笔者意料的,所以饶有兴致地阅读了一番。
然而,论文的表述似乎比较让人费解——当然也有笔者本就不大熟悉低精度运算的原因。总之,经过多次向作者请教后,笔者才勉强看懂论文,遂将自己的理解记录在此,供大家参考。
结论简述
要指出的是,论文标题虽然点名了“Flash Attention”,但按照论文的描述,即便block_size取到训练长度那么大,相同的问题依然会出现,所以Flash Attention的分块计算并不是引起问题的原因,因此我们可以按照朴素的低精度Attention实现来简化分析。
5
Oct
为什么线性注意力要加Short Conv?
By 苏剑林 | 2025-10-05 | 47861位读者 | 引用如果读者有关注模型架构方面的进展,那么就会发现,比较新的线性Attention(参考《线性注意力简史:从模仿、创新到反哺》)模型都给$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$加上了Short Conv,比如下图所示的DeltaNet:
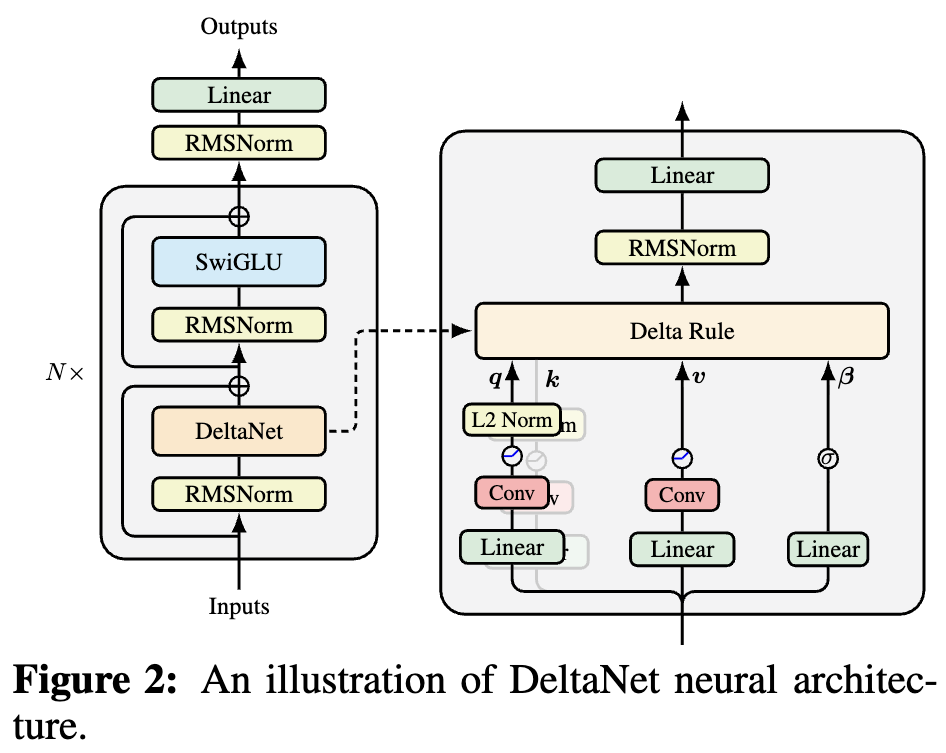
DeltaNet中的Short Conv
为什么要加这个Short Conv呢?直观理解可能是增加模型深度、增强模型的Token-Mixing能力等,说白了就是补偿线性化导致的表达能力下降。这个说法当然是大差不差,但它属于“万能模版”式的回答,我们更想对它的生效机制有更准确的认知。
接下来,笔者将给出自己的一个理解(更准确说应该是猜测)。
12
Jul
QK-Clip:让Muon在Scaleup之路上更进一步
By 苏剑林 | 2025-07-12 | 99772位读者 | 引用四个月前,我们发布了Moonlight,在16B的MoE模型上验证了Muon优化器的有效性。在Moonlight中,我们确认了给Muon添加Weight Decay的必要性,同时提出了通过Update RMS对齐来迁移Adam超参的技巧,这使得Muon可以快速应用于LLM的训练。然而,当我们尝试将Muon进一步拓展到千亿参数以上的模型时,遇到了新的“拦路虎”——MaxLogit爆炸。
为了解决这个问题,我们提出了一种简单但极其有效的新方法,我们称之为“QK-Clip”。该方法从一个非常本质的角度去看待和解决MaxLogit现象,并且无损模型效果,这成为我们最新发布的万亿参数模型“Kimi K2”的关键训练技术之一。
问题描述
我们先来简单介绍一下MaxLogit爆炸现象。回顾Attention的定义
\begin{equation}\boldsymbol{O} = softmax(\boldsymbol{Q}\boldsymbol{K}^{\top})\boldsymbol{V}\end{equation}
10
Jul
Transformer升级之路:21、MLA好在哪里?(下)
By 苏剑林 | 2025-07-10 | 86002位读者 | 引用
1
Jul
“对角+低秩”三角阵的高效求逆方法
By 苏剑林 | 2025-07-01 | 32268位读者 | 引用从文章《线性注意力简史:从模仿、创新到反哺》我们可以发现,DeltaNet及其后的线性Attention模型,基本上都关联到了逆矩阵$(\boldsymbol{I} + \boldsymbol{K}\boldsymbol{K}^{\top}\odot\boldsymbol{M}^-)^{-1}$。本文就专门来探讨一下这类具有“对角+低秩”特点的三角矩阵的逆矩阵计算。
基本结果
我们将问题一般地定义如下:
给定矩阵$\boldsymbol{Q},\boldsymbol{K}\in\mathbb{R}^{n\times d}$和对角矩阵$\boldsymbol{\Lambda}\in\mathbb{R}^{n\times n}$,满足$n\gg d$,定义 \begin{equation}\boldsymbol{T} = \boldsymbol{\Lambda} + \boldsymbol{Q}\boldsymbol{K}^{\top}\odot\boldsymbol{M}^-\end{equation} 其中$\boldsymbol{M}^-=\boldsymbol{M} - \boldsymbol{I}$,矩阵$\boldsymbol{M}$定义为 \begin{equation}M_{i,j} = \left\{\begin{aligned} &1, &i \geq j \\ &0, &i < j\end{aligned}\right.\end{equation} 现在要求逆矩阵$\boldsymbol{T}^{-1}$,并且证明其复杂度是$\mathcal{O}(n^2)$。

最近评论