






12
Apr
【语料】百度的中文问答数据集WebQA
By 苏剑林 | 2017-04-12 | 275118位读者 |信息抽取 #
众所周知,百度知道上有大量的人提了大量的问题,并且得到大量的回复。然而,百度知道上的回复者貌似懒人居多,他们往往喜欢直接在网上复制粘贴一大片来作为回答内容,而且这些内容可能跟问题相关,也可能跟问题不相关,比如
https://zhidao.baidu.com/question/557785746.html
问:广州白云山海拨多高
答:广州白云山(Guangzhou Baiyun Mountain),是新 “羊城八景”之首、国家4A级景区和国家重点风景名胜区。它位于广州市的东北部,为南粤名山之一,自古就有“羊城第一秀”之称。山体相当宽阔,由30多座山峰组成,为广东最高峰九连山的支脉。面积20.98平方公里,主峰摩星岭高382米(注:最新测绘高度为372.6米——国家测绘局,2008年),峰峦重叠,溪涧纵横,登高可俯览全市,遥望珠江。每当雨后天晴或暮春时节,山间白云缭绕,蔚为奇观,白云山之名由此得来
事实上,对于这个问题来说,只有“主峰摩星岭高382米”这一句才是有意义的,如果更精炼些,那么只有“382米”是有意义的,其他基本上是废话。事实上,如何从大片相关文本中,为给定问题提取正确的、简明的答案,不论是对于人还是机器来说,都是一个难题。这不仅需要好的算法,还需要好的数据集进行训练。
WebQA #
为此,百度利用百度知道和其他资源,构建了一个这样的一个数据集,称为WebQA,目前是v1.0版:
http://idl.baidu.com/WebQA.html
百度利用这个数据集所做的论文:
Peng Li, Wei Li, Zhengyan He, Xuguang Wang, Ying Cao, Jie Zhou, and Wei Xu. 2016. Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering. arXiv:1607.06275 .
感谢百度!开源数据集是难能可贵的!
数据概览 #
这部分内容均转载自http://idl.baidu.com/WebQA.html
$$\begin{array}{c|c|lc|c}
\hline
& & \rlap{\text{Annotated Evidence}}\\
& \text{Question} & Positive & Negative & \text{Retrieved Evidence}\\
\hline
Training & 36,181 & 140,897 & 125,886 & 181,661\\
Validation & 3,018 & \,\,5,305 & / & 60,351\\
Training & 3,024 & \,\,5,315 & / & 60,465\\
\hline
\end{array}$$
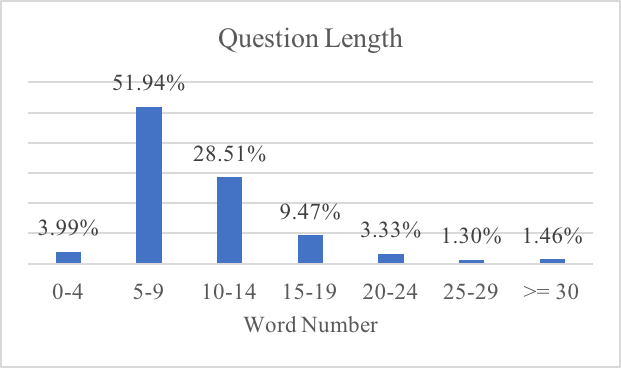
问题长度
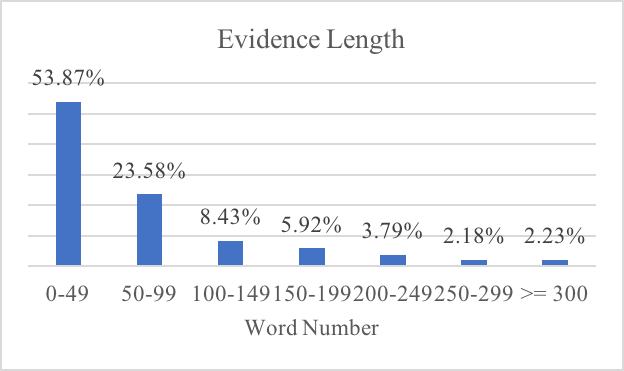
材料长度
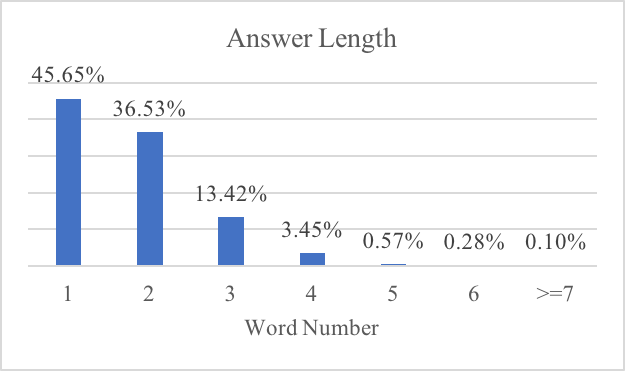
答案长度
发布的文件有267MB,但对于我们来说,里边的东西貌似有点过多了,因为里边包含了分词结果、序列标注结果、词向量结果,貌似是内部研究小组直接用来做的实验。对于我们来说,显然只需要纯粹的问答语料就行了。因此,我做了精简,仅保留了最基本的语料内容:
纯净版 #
链接: https://pan.baidu.com/s/1pLXEYtd 密码: 6fbf
文件列表:
WebQA.v1.0/readme.txt
WebQA.v1.0/me_test.ann.json (一个问题只配一段材料,材料中有答案)
WebQA.v1.0/me_test.ir.json (一个问题配多段材料,材料可能有也可能没有答案)
WebQA.v1.0/me_train.json (混合的训练语料)
WebQA.v1.0/me_validation.ann.json (一个问题只配一段材料,材料中有答案)
WebQA.v1.0/me_validation.ir.json (一个问题配多段材料,材料可能有也可能没有答案)test跟validation的区别是,理论上来说,validation的分布跟train的分布更加接近。一般而言,validation用来验证模型的精确度,test用来验证模型的迁移能力。ann与ir的区别是,因为ir给每个问题配置了多段材料,可以通过各段材料投票来得到更加可靠的答案;而ann则是一问一材料的形式,是真正考验阅读理解能力的测试集。
整理后的数据格式如下,以me_train.json为例:
1、如果用Python的json库读取后,得到一个字典me_train,字典的键是Q_TRN_010878这样的问题标号;
2、通过me_train['Q_TRN_010878']获得单条记录,每条记录也是一个字典,字典下有两个键:question和evidences;
3、me_train['Q_TRN_010878']['question']就可以获得问题的文本内容,如“勇敢的心霍笑林的父亲是谁出演的”;
4、evidences是问题的材料和对应答案,也是一个字典,字典的键是Q_TRN_010878#06这样的标号;
5、me_train['Q_TRN_010878']['evidences']['Q_TRN_010878#05']获得单条记录,也是一个字典,字典有两个键:evidence和answer;
6、evidence为对应的材料,如“答:《勇敢的心》霍绍昌与华夫人的儿子杨志刚饰霍啸林简介男主角,霍家少爷,领衔主演寇振海饰霍绍昌简介霍啸林的父亲‘举人’,主演史可饰华夫人简介霍啸林和赵舒城的母亲,主演”,answer是一个答案列表(因为答案可能有多个),如[u'寇振海'],如果材料中并没有答案,那么答案是[u'no_answer']。
这些都是跟原数据集一一对应的。
转载到请包括本文地址:https://kexue.fm/archives/4338
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 12, 2017). 《【语料】百度的中文问答数据集WebQA 》[Blog post]. Retrieved from https://kexue.fm/archives/4338
@online{kexuefm-4338,
title={【语料】百度的中文问答数据集WebQA},
author={苏剑林},
year={2017},
month={Apr},
url={\url{https://kexue.fm/archives/4338}},
}

November 7th, 2022
[...]WebQA: A Chinese Open-Domain Factoid Question Answering Dataset 发布的文件有267MB,但对于我们来说,里边的东西貌似有点过多了,因为里边包含了分词结果、序列标注结果、词向量结果,貌似是内部研究小组直接用来做的实验。对于我们来说,显然只需要纯粹的问答语料就行了。 相关介绍可见: 百度的中文问答数据集WebQA[...]