






13
Apr
突破瓶颈,打造更强大的Transformer
By 苏剑林 | 2020-04-13 | 144860位读者 | 引用自《Attention is All You Need》一文发布后,基于Multi-Head Attention的Transformer模型开始流行起来,而去年发布的BERT模型更是将Transformer模型的热度推上了又一个高峰。当然,技术的探索是无止境的,改进的工作也相继涌现:有改进预训练任务的,比如XLNET的PLM、ALBERT的SOP等;有改进归一化的,比如Post-Norm向Pre-Norm的改变,以及T5中去掉了Layer Norm里边的beta参数等;也有改进模型结构的,比如Transformer-XL等;有改进训练方式的,比如ALBERT的参数共享等;...
以上的这些改动,都是在Attention外部进行改动的,也就是说它们都默认了Attention的合理性,没有对Attention本身进行改动。而本文我们则介绍关于两个新结果:它们针对Multi-Head Attention中可能存在建模瓶颈,提出了不同的方案来改进Multi-Head Attention。两篇论文都来自Google,并且做了相当充分的实验,因此结果应该是相当有说服力的了。
再小也不能小key_size
第一个结果来自文章《Low-Rank Bottleneck in Multi-head Attention Models》,它明确地指出了Multi-Head Attention里边的表达能力瓶颈,并提出通过增大key_size的方法来缓解这个瓶颈。
5
Jun
为什么梯度裁剪能加速训练过程?一个简明的分析
By 苏剑林 | 2020-06-05 | 35496位读者 | 引用本文介绍来自MIT的一篇ICLR 2020满分论文《Why gradient clipping accelerates training: A theoretical justification for adaptivity》,顾名思义,这篇论文就是分析为什么梯度裁剪能加速深度学习的训练过程。原文很长,公式很多,还有不少研究复杂性的概念,说实话对笔者来说里边的大部分内容也是懵的,不过大概能捕捉到它的核心思想:引入了比常用的L约束更宽松的约束条件,从新的条件出发论证了梯度裁剪的必要性。本文就是来简明分析一下这个过程,供读者参考。
梯度裁剪
假设需要最小化的函数为$f(\theta)$,$\theta$就是优化参数,那么梯度下降的更新公式就是
\begin{equation}\theta \leftarrow \theta-\eta \nabla_{\theta} f(\theta)\end{equation}
其中$\eta$就是学习率。而所谓梯度裁剪(gradient clipping),就是根据梯度的模长来对更新量做一个缩放,比如
\begin{equation}\theta \leftarrow \theta- \eta \nabla_{\theta} f(\theta)\times \min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\label{eq:clip-1}\end{equation}
或者
\begin{equation}\theta \leftarrow \theta- \eta \nabla_{\theta} f(\theta)\times \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert+\gamma}\label{eq:clip-2}\end{equation}
其中$\gamma > 0$是一个常数。这两种方式都被视为梯度裁剪,总的来说就是控制更新量的模长不超过一个常数,第二种形式也跟RMSProp等自适应学习率优化器相关。此外,更精确地,我们有下面的不等式
\begin{equation}\frac{1}{2}\min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\leq \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert+\gamma}\leq \min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\end{equation}
也就是说两者是可以相互控制的,所以其实两者基本是等价的。
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 77096位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
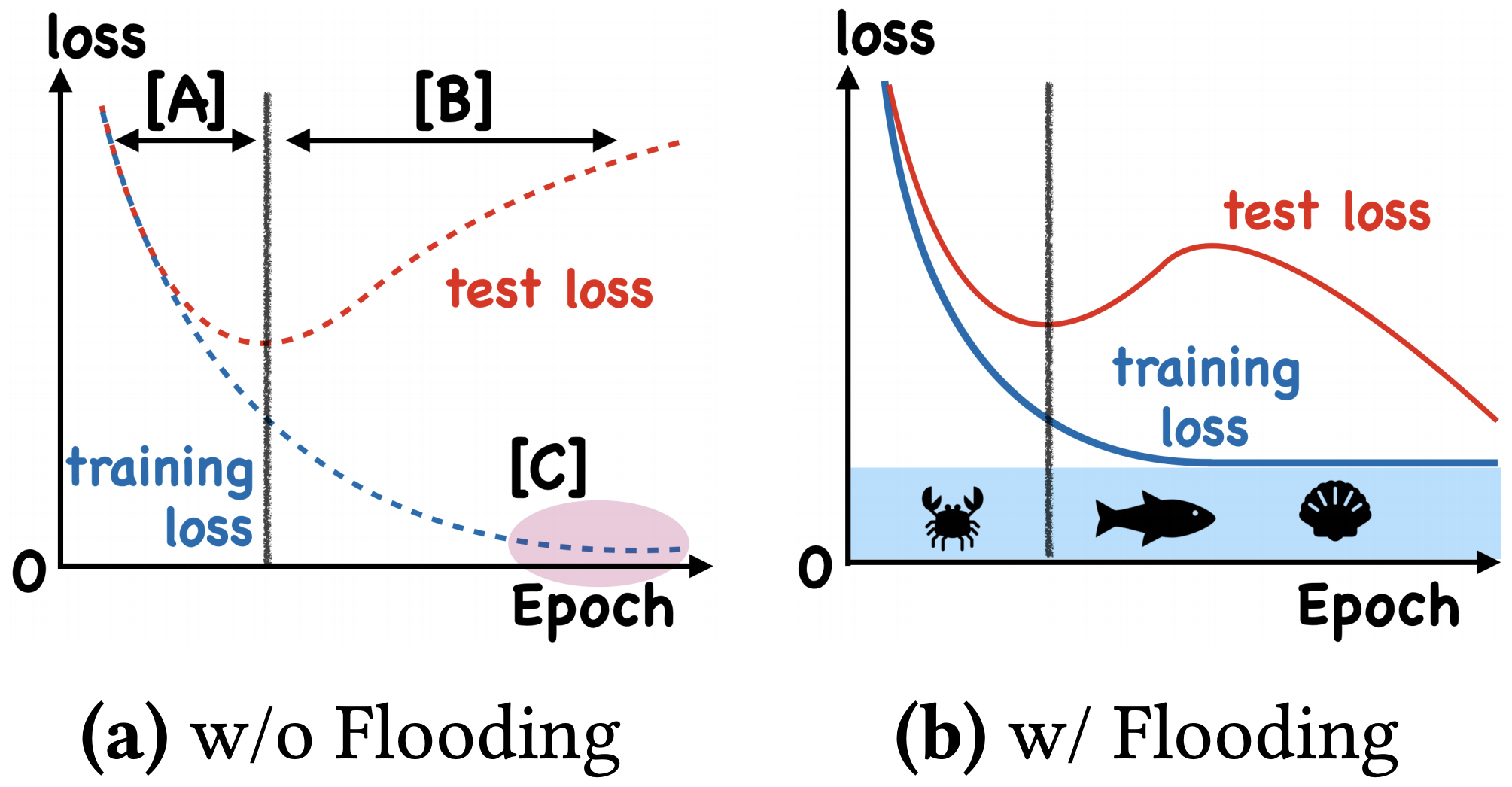
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图
后台提示,本文是科学空间的第1000篇文章。
本想写下一篇文章的,但是看到这个提示,就先瞎写个水文纪念一下。都说人老了就喜欢各种感叹,这话还真不假。看到别人高考来个感想,博客十周年了来个感想,现在第1000篇文章了也来个感想,似乎总想找点理由感叹一下一样。那今天又能扯些啥犊子呢?

1000
首先,自恋一下。1000篇文章,如果要印刷下来,就算每篇文章印一页,那也能印个1000页了,相信不少人都没捧起过1000页的书吧(我还真读过,有文章为证:《哈哈,我的“〈圣经〉”到了》),我居然能写个1000篇,也是挺佩服自己的。当然,早期的文章有部分是转载的,不是全部都自己写的,不过还是坚持了不少原创内容,而且就算是转载的也是经过自己编辑整理的,不算纯Copy,所以也勉强能说的过去吧。
然后,庆幸一下。博客开始的主题是天文和科普,后来慢慢偏向了理论物理和数学,现在则偏向了机器学习,但不管怎样,总算很庆幸地在科学这条路坚持了下来。虽然没有像幼时设想的那样成为一名真正的自然科学家/数学家,但终究有点相关,闲时依然可以做做科学计算,勉强也对得起当初的梦想。
15
Mar
WGAN的成功,可能跟Wasserstein距离没啥关系
By 苏剑林 | 2021-03-15 | 60872位读者 | 引用WGAN,即Wasserstein GAN,算是GAN史上一个比较重要的理论突破结果,它将GAN中两个概率分布的度量从f散度改为了Wasserstein距离,从而使得WGAN的训练过程更加稳定,而且生成质量通常也更好。Wasserstein距离跟最优传输相关,属于Integral Probability Metric(IPM)的一种,这类概率度量通常有着更优良的理论性质,因此WGAN的出现也吸引了很多人从最优传输和IPMs的角度来理解和研究GAN模型。
然而,最近Arxiv上的论文《Wasserstein GANs Work Because They Fail (to Approximate the Wasserstein Distance)》则指出,尽管WGAN是从Wasserstein GAN推导出来的,但是现在成功的WGAN并没有很好地近似Wasserstein距离,相反如果我们对Wasserstein距离做更好的近似,效果反而会变差。事实上,笔者一直以来也有这个疑惑,即Wasserstein距离本身并没有体现出它能提升GAN效果的必然性,该论文的结论则肯定了该疑惑,所以GAN能成功的原因依然很迷~
10
May
Transformer升级之路:4、二维位置的旋转式位置编码
By 苏剑林 | 2021-05-10 | 129312位读者 | 引用在之前的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中我们提出了旋转式位置编码RoPE以及对应的Transformer模型RoFormer。由于笔者主要研究的领域还是NLP,所以本来这个事情对于笔者来说已经完了。但是最近一段时间,Transformer模型在视觉领域也大火,各种Vision Transformer(ViT)层出不穷,于是就有了问题:二维情形的RoPE应该是怎样的呢?
咋看上去,这个似乎应该只是一维情形的简单推广,但其中涉及到的推导和理解却远比我们想象中复杂,本文就对此做一个分析,从而深化我们对RoPE的理解。
二维RoPE
什么是二维位置?对应的二维RoPE又是怎样的?它的难度在哪里?在这一节中,我们先简单介绍二维位置,然后直接给出二维RoPE的结果和推导思路,在随后的几节中,我们再详细给出推导过程。
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 85253位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
26
Jul
FlatNCE:小批次对比学习效果差的原因竟是浮点误差?
By 苏剑林 | 2021-07-26 | 51164位读者 | 引用自SimCLR在视觉无监督学习大放异彩以来,对比学习逐渐在CV乃至NLP中流行了起来,相关研究和工作越来越多。标准的对比学习的一个广为人知的缺点是需要比较大的batch_size(SimCLR在batch_size=4096时效果最佳),小batch_size的时候效果会明显降低,为此,后续工作的改进方向之一就是降低对大batch_size的依赖。那么,一个很自然的问题是:标准的对比学习在小batch_size时效果差的原因究竟是什么呢?
近日,一篇名为《Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE》对此问题作出了回答:因为浮点误差。看起来真的很让人难以置信,但论文的分析确实颇有道理,并且所提出的改进FlatNCE确实也工作得更好,让人不得不信服。
细微之处
接下来,笔者将按照自己的理解和记号来介绍原论文的主要内容。对比学习(Contrastive Learning)就不帮大家详细复习了,大体上来说,对于某个样本$x$,我们需要构建$K$个配对样本$y_1,y_2,\cdots,y_K$,其中$y_t$是正样本而其余都是负样本,然后分别给每个样本对$(x, y_i)$打分,分别记为$s_1,s_2,\cdots,s_K$,对比学习希望拉大正负样本对的得分差,通常直接用交叉熵作为损失:
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_i e^{s_i}} = \log \left(\sum_i e^{s_i}\right) - s_t = \log \left(1 + \sum_{i\neq t} e^{s_i - s_t}\right)\end{equation}

最近评论