






26
Feb
非对抗式生成模型GLANN的简单介绍
By 苏剑林 | 2019-02-26 | 57599位读者 | 引用前段时间看到facebook发表了一个非对抗的生成模型GLANN(去年12月挂在arxiv上),号称用非对抗的方式也能生成1024的高清人脸,于是饶有兴致地阅读了一番,确实有点收获,但也有点失望。至于为啥失望,大家阅读下去就明白了。
原论文:《Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors》
机器之心介绍:《为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN》
效果图:

GLANN效果图
10
May
能量视角下的GAN模型(三):生成模型=能量模型
By 苏剑林 | 2019-05-10 | 44732位读者 | 引用
本文的模型在ImageNet(128x128)上的条件生成效果
今天要介绍的结果还是跟能量模型相关,来自论文《Implicit Generation and Generalization in Energy-Based Models》。当然,它已经跟GAN没有什么关系了,但是跟本系列第二篇所介绍的能量模型关系较大,所以还是把它放到这个系列好了。
我当初留意到这篇论文,是因为机器之心的报导《MIT本科学神重启基于能量的生成模型,新框架堪比GAN》,但是说实在的,这篇文章没什么意思,说句不中听的,就是炒冷饭系列,媒体的标题也算中肯,是“重启”。这篇文章就是指出能量模型实际上就是某个特定的Langevin方程的静态解,然后就用这个Langevin方程来实现采样,有了采样过程也就可以完成能量模型的训练,这些理论都是现成的,所以这个过程我在学习随机微分方程的时候都想过,我相信很多人也都想过。因此,我觉得作者的贡献就是把这个直白的想法通过一系列炼丹技巧实现了。
但不管怎样,能训练出来也是一件很不错的事情,另外对于之前没了解过相关内容的读者来说,这确实也算是一个不错的能量模型案例,所以我论文的整体思路整理一下,让读者能够更全面地理解能量模型。
27
Oct
什么时候多进程的加速比可以大于1?
By 苏剑林 | 2019-10-27 | 49504位读者 | 引用多进程或者多线程等并行加速目前已经不是什么难事了,相信很多读者都体验过。一般来说,我们会有这样的结论:多进程的加速比很难达到1。换句话说,当你用10进程去并行跑一个任务时,一般只能获得不到10倍的加速,而且进程越多,这个加速比往往就越低。
要注意,我们刚才说“很难达到1”,说明我们的潜意识里就觉得加速比最多也就是1。理论上确实是的,难不成用10进程还能获得20倍的加速?这不是天上掉馅饼吗?不过我前几天确实碰到了一个加速比远大于1的例子,所以在这里跟大家分享一下。
词频统计
我的原始任务是统计词频:我有很多文章,然后我们要对这些文章进行分词,最后汇总出一个词频表出来。一般的写法是这样的:
tokens = {}
for text in read_texts():
for token in tokenize(text):
tokens[token] = tokens.get(token, 0) + 1这种写法在我统计THUCNews全部文章的词频时,大概花了20分钟。
13
Apr
突破瓶颈,打造更强大的Transformer
By 苏剑林 | 2020-04-13 | 102877位读者 | 引用自《Attention is All You Need》一文发布后,基于Multi-Head Attention的Transformer模型开始流行起来,而去年发布的BERT模型更是将Transformer模型的热度推上了又一个高峰。当然,技术的探索是无止境的,改进的工作也相继涌现:有改进预训练任务的,比如XLNET的PLM、ALBERT的SOP等;有改进归一化的,比如Post-Norm向Pre-Norm的改变,以及T5中去掉了Layer Norm里边的beta参数等;也有改进模型结构的,比如Transformer-XL等;有改进训练方式的,比如ALBERT的参数共享等;...
以上的这些改动,都是在Attention外部进行改动的,也就是说它们都默认了Attention的合理性,没有对Attention本身进行改动。而本文我们则介绍关于两个新结果:它们针对Multi-Head Attention中可能存在建模瓶颈,提出了不同的方案来改进Multi-Head Attention。两篇论文都来自Google,并且做了相当充分的实验,因此结果应该是相当有说服力的了。
再小也不能小key_size
第一个结果来自文章《Low-Rank Bottleneck in Multi-head Attention Models》,它明确地指出了Multi-Head Attention里边的表达能力瓶颈,并提出通过增大key_size的方法来缓解这个瓶颈。
5
Jun
为什么梯度裁剪能加速训练过程?一个简明的分析
By 苏剑林 | 2020-06-05 | 28441位读者 | 引用本文介绍来自MIT的一篇ICLR 2020满分论文《Why gradient clipping accelerates training: A theoretical justification for adaptivity》,顾名思义,这篇论文就是分析为什么梯度裁剪能加速深度学习的训练过程。原文很长,公式很多,还有不少研究复杂性的概念,说实话对笔者来说里边的大部分内容也是懵的,不过大概能捕捉到它的核心思想:引入了比常用的L约束更宽松的约束条件,从新的条件出发论证了梯度裁剪的必要性。本文就是来简明分析一下这个过程,供读者参考。
梯度裁剪
假设需要最小化的函数为$f(\theta)$,$\theta$就是优化参数,那么梯度下降的更新公式就是
\begin{equation}\theta \leftarrow \theta-\eta \nabla_{\theta} f(\theta)\end{equation}
其中$\eta$就是学习率。而所谓梯度裁剪(gradient clipping),就是根据梯度的模长来对更新量做一个缩放,比如
\begin{equation}\theta \leftarrow \theta- \eta \nabla_{\theta} f(\theta)\times \min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\label{eq:clip-1}\end{equation}
或者
\begin{equation}\theta \leftarrow \theta- \eta \nabla_{\theta} f(\theta)\times \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert+\gamma}\label{eq:clip-2}\end{equation}
其中$\gamma > 0$是一个常数。这两种方式都被视为梯度裁剪,总的来说就是控制更新量的模长不超过一个常数,第二种形式也跟RMSProp等自适应学习率优化器相关。此外,更精确地,我们有下面的不等式
\begin{equation}\frac{1}{2}\min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\leq \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert+\gamma}\leq \min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\end{equation}
也就是说两者是可以相互控制的,所以其实两者基本是等价的。
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 56737位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
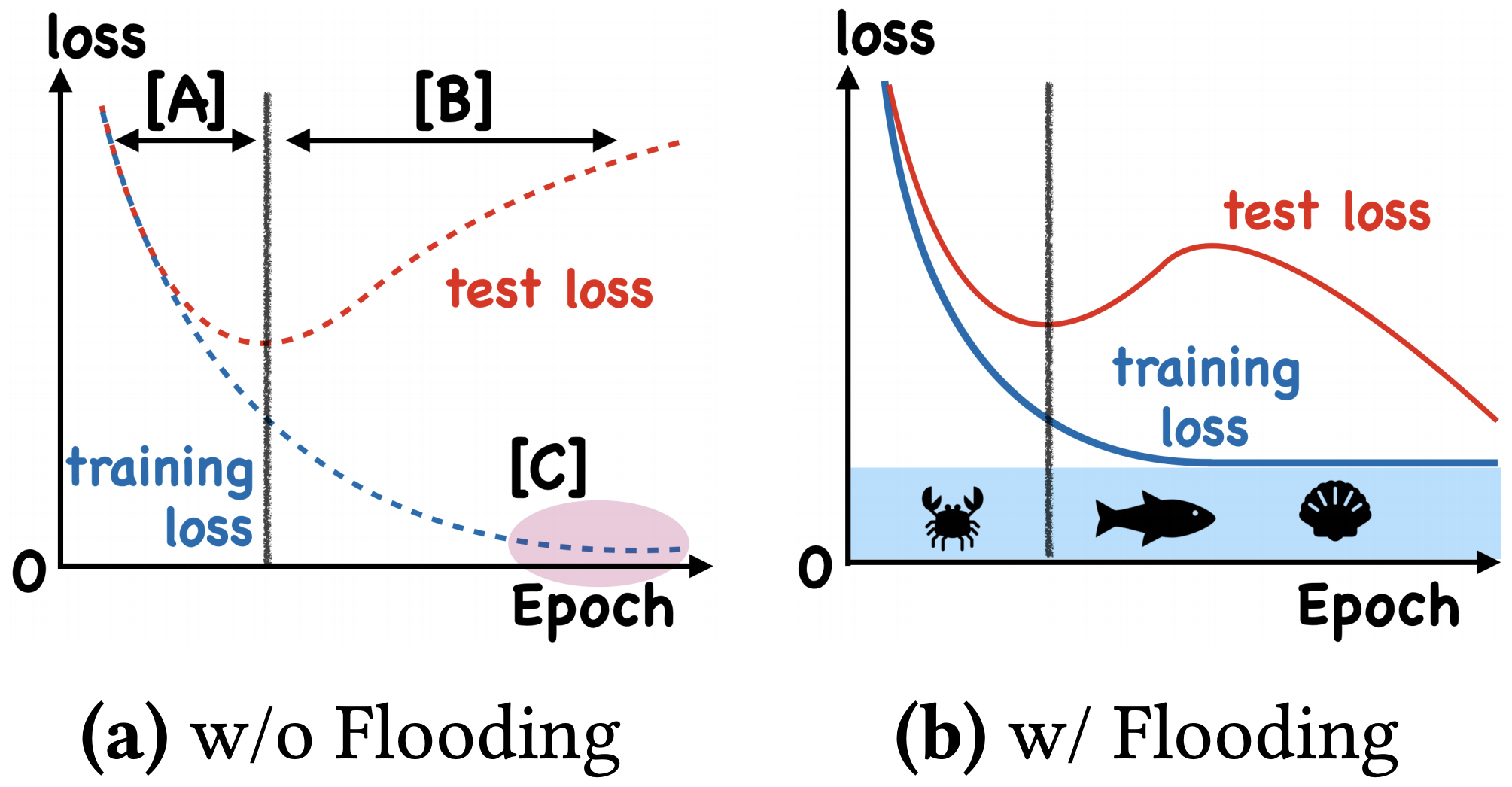
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图
后台提示,本文是科学空间的第1000篇文章。
本想写下一篇文章的,但是看到这个提示,就先瞎写个水文纪念一下。都说人老了就喜欢各种感叹,这话还真不假。看到别人高考来个感想,博客十周年了来个感想,现在第1000篇文章了也来个感想,似乎总想找点理由感叹一下一样。那今天又能扯些啥犊子呢?

1000
首先,自恋一下。1000篇文章,如果要印刷下来,就算每篇文章印一页,那也能印个1000页了,相信不少人都没捧起过1000页的书吧(我还真读过,有文章为证:《哈哈,我的“〈圣经〉”到了》),我居然能写个1000篇,也是挺佩服自己的。当然,早期的文章有部分是转载的,不是全部都自己写的,不过还是坚持了不少原创内容,而且就算是转载的也是经过自己编辑整理的,不算纯Copy,所以也勉强能说的过去吧。
然后,庆幸一下。博客开始的主题是天文和科普,后来慢慢偏向了理论物理和数学,现在则偏向了机器学习,但不管怎样,总算很庆幸地在科学这条路坚持了下来。虽然没有像幼时设想的那样成为一名真正的自然科学家/数学家,但终究有点相关,闲时依然可以做做科学计算,勉强也对得起当初的梦想。
15
Mar
WGAN的成功,可能跟Wasserstein距离没啥关系
By 苏剑林 | 2021-03-15 | 42950位读者 | 引用WGAN,即Wasserstein GAN,算是GAN史上一个比较重要的理论突破结果,它将GAN中两个概率分布的度量从f散度改为了Wasserstein距离,从而使得WGAN的训练过程更加稳定,而且生成质量通常也更好。Wasserstein距离跟最优传输相关,属于Integral Probability Metric(IPM)的一种,这类概率度量通常有着更优良的理论性质,因此WGAN的出现也吸引了很多人从最优传输和IPMs的角度来理解和研究GAN模型。
然而,最近Arxiv上的论文《Wasserstein GANs Work Because They Fail (to Approximate the Wasserstein Distance)》则指出,尽管WGAN是从Wasserstein GAN推导出来的,但是现在成功的WGAN并没有很好地近似Wasserstein距离,相反如果我们对Wasserstein距离做更好的近似,效果反而会变差。事实上,笔者一直以来也有这个疑惑,即Wasserstein距离本身并没有体现出它能提升GAN效果的必然性,该论文的结论则肯定了该疑惑,所以GAN能成功的原因依然很迷~

最近评论