






29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 75192位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
2
Dec
最小熵原理(四):“物以类聚”之从图书馆到词向量
By 苏剑林 | 2018-12-02 | 95174位读者 | 引用从第一篇看下来到这里,我们知道所谓“最小熵原理”就是致力于降低学习成本,试图用最小的成本完成同样的事情。所以整个系列就是一个“偷懒攻略”。那偷懒的秘诀是什么呢?答案是“套路”,所以本系列又称为“套路宝典”。
本篇我们介绍图书馆里边的套路。
先抛出一个问题:词向量出现在什么时候?是2013年Mikolov的Word2Vec?还是是2003年Bengio大神的神经语言模型?都不是,其实词向量可以追溯到千年以前,在那古老的图书馆中...

图书馆一角(图片来源于百度搜索)
走进图书馆
图书馆里有词向量?还是千年以前?在哪本书?我去借来看看。
放书的套路
其实不是哪本书,而是放书的套路。
很明显,图书馆中书的摆放是有“套路”的:它们不是随机摆放的,而是分门别类地放置的,比如数学类放一个区,文学类放一个区,计算机类也放一个区;同一个类也有很多子类,比如数学类中,数学分析放一个子区,代数放一个子区,几何放一个子区,等等。读者是否思考过,为什么要这么分类放置?分类放置有什么好处?跟最小熵又有什么关系?
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 100950位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 85583位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
6
Nov
Keras:Tensorflow的黄金标准
By 苏剑林 | 2019-11-06 | 76709位读者 | 引用这两周投入了比较多的精力去做bert4keras的开发,除了一些API的规范化工作外,其余的主要工作量是构建预训练部分的代码。在昨天,预训练代码基本构建完毕,并同时在TPU/多GPU环境下测试通过,从而有志(有算力)改进预训练模型的同学多了一个选择。——这可能是目前最为清晰易懂的bert及其预训练代码。
预训练代码链接: https://github.com/bojone/bert4keras/tree/master/pretraining
经过这两周的开发(填坑),笔者的最大感想就是:Keras已经成为了tensorflow的黄金标准了。只要你的代码按照Keras的标准规范写,那可以轻松迁移到tf.keras中去,继而可以非常轻松地在TPU或多GPU环境下训练,真正的几乎是一劳永逸。相反,如果你的写法过于灵活,包括像笔者之前介绍的很多“移花接木”式的Keras技巧,就可能会有不少问题,甚至可能出现的一种情况是:就算你已经在多GPU上跑通了,在TPU上你也死活调不通。

Keras和Tensorflow
11
Nov
JoSE:球面上的词向量和句向量
By 苏剑林 | 2019-11-11 | 69117位读者 | 引用这篇文章介绍一个发表在NeurIPS 2019的做词向量和句向量的模型JoSE(Joint Spherical Embedding),论文名字是《Spherical Text Embedding》。JoSE模型思想上和方法上传承自Doc2Vec,评测结果更加漂亮,但写作有点故弄玄虚之感。不过笔者决定写这篇文章,是因为觉得里边的某些分析过程有点意思,可能会对一般的优化问题都有些参考价值。
优化目标
在思想上,这篇文章基本上跟Doc2Vec是一致的:为了训练句向量,把句子用一个id表示,然后把它也当作一个词,跟句内所有的词都共现,最后训练一个Skip Gram模型,训练的方式都是基于负采样的。跟Doc2Vec不一样的是,JoSE将全体向量的模长都归一化了(也就是只考虑单位球面上的向量),然后训练目标没有用交叉熵,而是用hinge loss:
\begin{equation}\max(0, m - \cos(\boldsymbol{u}, \boldsymbol{v}) - \cos(\boldsymbol{u}, \boldsymbol{d}) + \cos(\boldsymbol{u}', \boldsymbol{v}) + \cos(\boldsymbol{u}', \boldsymbol{d})\label{eq:loss}\end{equation}
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 258090位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
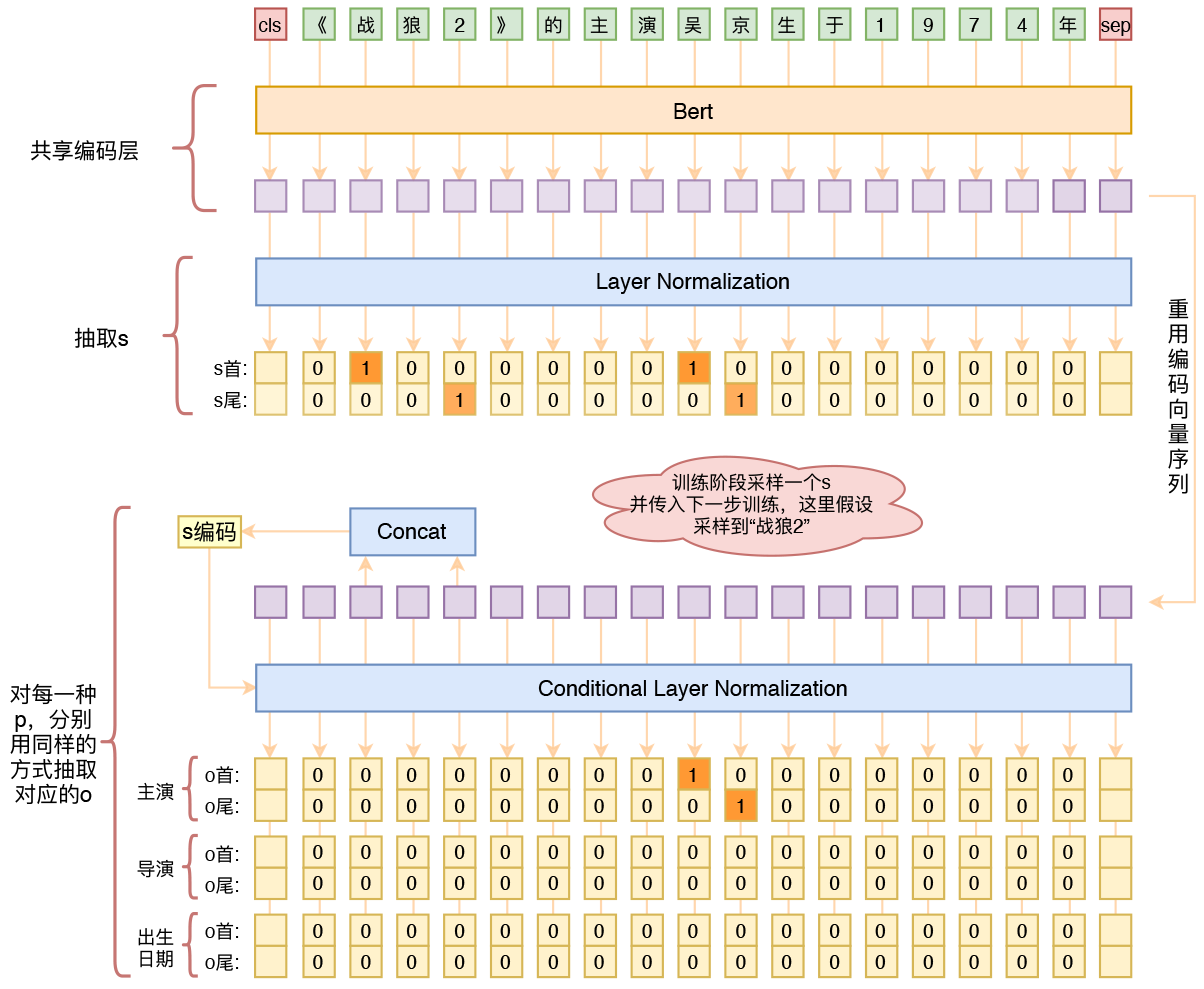
基于Bert的三元组抽取模型结构示意图
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 425916位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
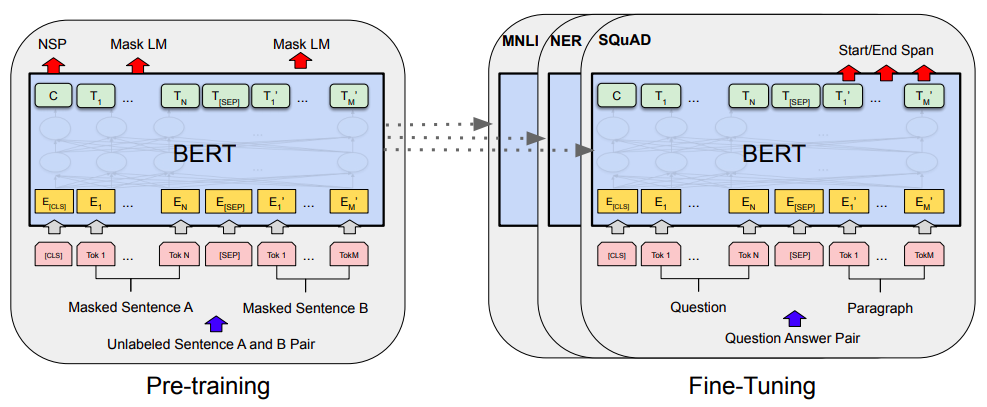
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。

最近评论