






18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 598025位读者 |Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
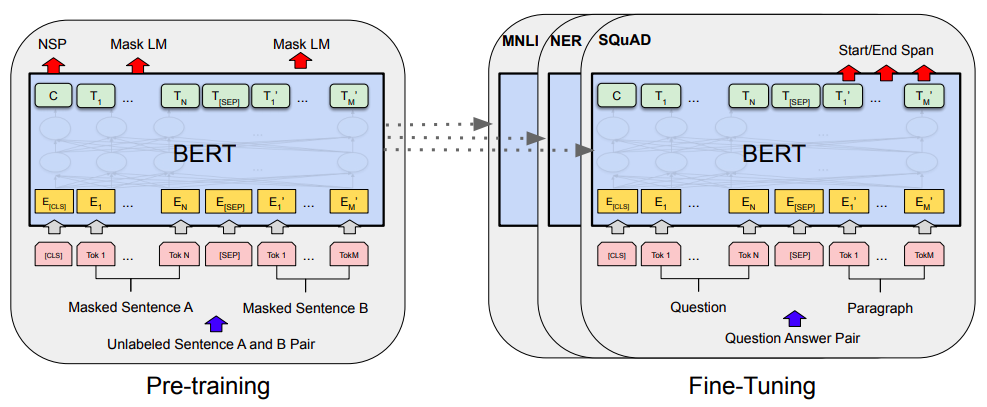
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
当Bert遇上Keras #
很幸运的是,已经有大佬封装好了Keras版的Bert,可以直接调用官方发布的预训练权重,对于已经有一定Keras基础的读者来说,这可能是最简单的调用Bert的方式了。所谓“站在巨人的肩膀上”,就是形容我们这些Keras爱好者此刻的心情了。
keras-bert #
个人认为,目前在Keras下对Bert最好的封装是:
keras-bert:https://github.com/CyberZHG/keras-bert
本文也是以此为基础的。
顺便一提的是,除了keras-bert之外,CyberZHG大佬还封装了很多有价值的keras模块,比如keras-gpt-2(你可以用像用bert一样用gpt2模型了)、keras-lr-multiplier(分层设置学习率)、keras-ordered-neurons(就是前不久介绍的ON-LSTM)等等,汇总可以看这里。看来也是一位Keras铁杆粉丝啊~致敬大佬。
事实上,有了keras-bert之后,再加上一点点keras基础知识,而且keras-bert所给的demo已经足够完善,调用、微调Bert都已经变成了意见没有什么技术含量的事情了。所以后面笔者只是给出几个中文的例子,来让读者上手keras-bert的基本用法。
Tokenizer #
正式讲例子之前,还有必要先讲一下Tokenizer相关内容。我们导入Bert的Tokenizer并重构一下它:
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
import codecs
config_path = '../bert/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '../bert/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '../bert/chinese_L-12_H-768_A-12/vocab.txt'
token_dict = {}
with codecs.open(dict_path, 'r', 'utf8') as reader:
for line in reader:
token = line.strip()
token_dict[token] = len(token_dict)
class OurTokenizer(Tokenizer):
def _tokenize(self, text):
R = []
for c in text:
if c in self._token_dict:
R.append(c)
elif self._is_space(c):
R.append('[unused1]') # space类用未经训练的[unused1]表示
else:
R.append('[UNK]') # 剩余的字符是[UNK]
return R
tokenizer = OurTokenizer(token_dict)
tokenizer.tokenize(u'今天天气不错')
# 输出是 ['[CLS]', u'今', u'天', u'天', u'气', u'不', u'错', '[SEP]']
这里简单解释一下Tokenizer的输出结果。首先,默认情况下,分词后句子首位会分别加上[CLS]和[SEP]标记,其中[CLS]位置对应的输出向量是能代表整句的句向量(反正Bert是这样设计的),而[SEP]则是句间的分隔符,其余部分则是单字输出(对于中文来说)。
本来Tokenizer有自己的_tokenize方法,我这里重写了这个方法,是要保证tokenize之后的结果,跟原来的字符串长度等长(如果算上两个标记,那么就是等长再加2)。Tokenizer自带的_tokenize会自动去掉空格,然后有些字符会粘在一块输出,导致tokenize之后的列表不等于原来字符串的长度了,这样如果做序列标注的任务会很麻烦。而为了避免这种麻烦,还是自己重写一遍好了~主要就是用[unused1]来表示空格类字符,而其余的不在列表的字符用[UNK]表示,其中[unused*]这些标记是未经训练的(随即初始化),是Bert预留出来用来增量添加词汇的标记,所以我们可以用它们来指代任何新字符。
三个例子 #
这里包含keras-bert的三个例子,分别是文本分类、关系抽取和主体抽取,都是在官方发布的预训练权重基础上进行微调来做的。
Bert官方Github:https://github.com/google-research/bert
官方的中文预训练权重:chinese_L-12_H-768_A-12.zip
例子所在Github:https://github.com/bojone/bert_in_keras/
根据官方介绍,这份权重是用中文维基百科为语料进行训练的。
(2019年6月20日更新:哈工大讯飞联合实验室发布了一版新权重,也可以用keras_bert加载,详情请看这里。)
文本分类 #
作为第一个例子,我们做一个最基本的文本分类任务,熟悉做这个基本任务之后,剩下的各种任务都会变得相当简单了。这次我们以之前已经讨论过多次的文本感情分类任务为例,所用的标注数据也是以前所整理的。
让我们来看看模型部分全貌(完整代码见这里):
# 注意,尽管可以设置seq_len=None,但是仍要保证序列长度不超过512
bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path, seq_len=None)
for l in bert_model.layers:
l.trainable = True
x1_in = Input(shape=(None,))
x2_in = Input(shape=(None,))
x = bert_model([x1_in, x2_in])
x = Lambda(lambda x: x[:, 0])(x) # 取出[CLS]对应的向量用来做分类
p = Dense(1, activation='sigmoid')(x)
model = Model([x1_in, x2_in], p)
model.compile(
loss='binary_crossentropy',
optimizer=Adam(1e-5), # 用足够小的学习率
metrics=['accuracy']
)
model.summary()在Keras中调用Bert来做情感分类任务就这样写完了~写完了~~
是不是感觉还没有尽兴,模型代码就结束了?Keras调用Bert就这么简短。事实上,真正调用Bert的也就只有load_trained_model_from_checkpoint那一行代码,剩下的只是普通的Keras操作(再次感谢CyberZHG大佬)。所以,如果你已经入门了Keras,那么调用Bert是无往不利啊。
如此简单的调用,能达到什么精度?经过5个epoch的fine tune后,验证集的最好准确率是95.5%+!之前我们在《文本情感分类(三):分词 OR 不分词》中死调烂调,也就只有90%上下的准确率;而用了Bert之后,寥寥几行,就提升了5个百分点多的准确率!也难怪Bert能在NLP界掀起一阵热潮...
在这里,用笔者的个人经历先回答读者可能关心的两个问题。
第一个问题应该是大家都很关心的,那就是“要多少显存才够?”。事实上,这没有一个标准答案,显存的使用取决于三个因素:句子长度、batch size、模型复杂度。像上面的情感分析例子,在笔者的GTX1060 6G显存上也能跑起来,只需要将batch size调到24即可。所以,如果你的显存不够大,将句子的maxlen和batch size都调小一点试试。当然,如果你的任务太复杂,再小的maxlen和batch size也可能OOM,那就只有升级显卡了。
第二个问题是“有什么原则来指导Bert后面应该要接哪些层?”。答案是:用尽可能少的层来完成你的任务。比如上述情感分析只是一个二分类任务,你就取出第一个向量然后加个Dense(1)就好了,不要想着多加几层Dense,更加不要想着接个LSTM再接Dense;如果你要做序列标注(比如NER),那你就接个Dense+CRF就好,也不要多加其他东西。总之,额外加的东西尽可能少。一是因为Bert本身就足够复杂,它有足够能力应对你要做的很多任务;二来你自己加的层都是随机初始化的,加太多会对Bert的预训练权重造成剧烈扰动,容易降低效果甚至造成模型不收敛~
关系抽取 #
假如读者已经有了一定的Keras基础,那么经过第一个例子的学习,其实我们应该已经完全掌握了Bert的fine tune了,因为实在是简单到没有什么好讲了。所以,后面两个例子主要是提供一些参考模式,让读者能体会到如何“用尽可能少的层来完成你的任务”。
在第二个例子中,我们介绍基于Bert实现的一个极简的关系抽取模型,其标注原理跟《基于DGCNN和概率图的轻量级信息抽取模型》介绍的一样,但是得益于Bert强大的编码能力,我们所写的部分可以大大简化。在笔者所给出的一种参考实现中,模型部分如下(完整模型见这里):
t = bert_model([t1, t2])
ps1 = Dense(1, activation='sigmoid')(t)
ps2 = Dense(1, activation='sigmoid')(t)
subject_model = Model([t1_in, t2_in], [ps1, ps2]) # 预测subject的模型
k1v = Lambda(seq_gather)([t, k1])
k2v = Lambda(seq_gather)([t, k2])
kv = Average()([k1v, k2v])
t = Add()([t, kv])
po1 = Dense(num_classes, activation='sigmoid')(t)
po2 = Dense(num_classes, activation='sigmoid')(t)
object_model = Model([t1_in, t2_in, k1_in, k2_in], [po1, po2]) # 输入text和subject,预测object及其关系
train_model = Model([t1_in, t2_in, s1_in, s2_in, k1_in, k2_in, o1_in, o2_in],
[ps1, ps2, po1, po2])如果读者已经读过《基于DGCNN和概率图的轻量级信息抽取模型》一文,了解到不用Bert时的模型架构,那么就会理解到上述实现是多么的简介明了。
可以看到,我们引入了Bert作为编码器,然后得到了编码序列$t$,然后直接接两个Dense(1),这就完成了subject的标注模型;接着,我们把传入的s的首尾对应的编码向量拿出来,直接加到编码向量序列$t$中去,然后再接两个Dense(num_classes),就完成object的标注模型(同时标注出了关系)。
这样简单的设计,最终F1能到多少?答案是:线下dev能接近82%,线上我提交过一次,结果是85%+(都是单模型)!相比之下,《基于DGCNN和概率图的轻量级信息抽取模型》中的模型,需要接CNN,需要搞全局特征,需要将s传入到LSTM进行编码,还需要相对位置向量,各种拍脑袋的模块融合在一起,单模型也只比它好一点点(大约82.5%)。要知道,这个基于Bert的简单模型我只写了一个小时就写出来了,而各种技巧和模型融合在一起的DGCNN模型,我前前后后调试了差不多两个月!Bert的强悍之处可见一斑。
(注:这个模型的fine tune最好有8G以上的显存。另外,因为我在比赛即将结束的前几天才接触的Bert,才把这个基于Bert的模型写出来,没有花心思好好调试,所以最终的提交结果并没有包含Bert。)
用Bert做关系抽取的这个例子,跟前面情感分析的简单例子,有一个明显的差别是学习率的变化。
情感分析的例子中,只是用了恒定的学习率($10^{-5}$)训练了几个epoch,效果就还不错了。在关系抽取这个例子中,第一个epoch的学习率慢慢从$0$增加到$5\times 10^{-5}$(这样称为warmup),第二个epoch再从$5\times 10^{-5}$降到$10^{-5}$,总的来说就是先增后减,Bert本身也是用类似的学习率曲线来训练的,这样的训练方式比较稳定,不容易崩溃,而且效果也比较好。
事件主体抽取 #
最后一个例子来自CCKS 2019 面向金融领域的事件主体抽取,这个比赛目前还在进行,不过我也已经没有什么动力和兴趣做下去了,所以放出我现在的模型(准确率为89%+)供大家参考,祝继续参赛的选手取得更好的成绩。
简单介绍一下这个比赛的数据,大概是这样的
输入:“公司A产品出现添加剂,其下属子公司B和公司C遭到了调查”, “产品出现问题”
输出: “公司A”
也就是说,这是个双输入、单输出的模型,输入是一个query和一个事件类型,输出一个实体(有且只有一个,并且是query的一个片段)。其实这个任务可以看成是SQUAD 1.0的简化版,根据这个输出特性,输出应该用指针结构比较好(两个softmax分别预测首尾)。剩下的问题是:双输入怎么搞?
前面两个例子虽然复杂度不同,但它们都是单一输入的,双输入怎么办呢?当然,这里的实体类型只有有限个,直接Embedding也行,只不过我使用一种更能体现Bert的简单粗暴和强悍的方案:直接用连接符将两个输入连接成一个句子,然后就变成单输入了!比如上述示例样本处理成:
输入:“___产品出现问题___公司A产品出现添加剂,其下属子公司B和公司C遭到了调查”
输出: “公司A”
然后就变成了普通的单输入抽取问题了。说到这个,这个模型的代码也就没有什么好说的了,就简单几行(完整代码请看这里):
x = bert_model([x1, x2])
ps1 = Dense(1, use_bias=False)(x)
ps1 = Lambda(lambda x: x[0][..., 0] - (1 - x[1][..., 0]) * 1e10)([ps1, x_mask])
ps2 = Dense(1, use_bias=False)(x)
ps2 = Lambda(lambda x: x[0][..., 0] - (1 - x[1][..., 0]) * 1e10)([ps2, x_mask])
model = Model([x1_in, x2_in], [ps1, ps2])另外加上一些解码的trick,还有模型融合,提交上去,就可以做到89%+了。在看看目前排行榜,发现最好的结果也就是90%多一点点,所以估计大家都差不多是这样做的了...(这个代码重复实验时波动比较大,大家可以多跑几次,取最优结果。)
这个例子主要告诉我们,用Bert实现自己的任务时,最好能整理成单输入的模式,这样一来比较简单,二来也更加高效。
比如做句子相似度模型,输入两个句子,输出一个相似度,有两个可以想到的做法,第一种是两个句子分别过同一个Bert,然后取出各自的[CLS]特征来做分类;第二种就是像上面一样,用个记号把两个句子连接在一起,变成一个句子,然后过一个Bert,然后将输出特征做分类,后者显然会更快一些,而且能够做到特征之间更全面的交互。
文章小结 #
本文介绍了Keras下Bert的基本调用方法,其中主要是提供三个参考例子,供大家逐步熟悉Bert的fine tune步骤和原理。其中有不少是笔者自己闭门造车的经验之谈,如果有所偏颇,还望读者指正。
事实上有了CyberZHG大佬实现的keras-bert,在Keras下使用Bert也就是小菜一碟,大家折腾个半天,也就上手了。最后祝大家用得痛快~
转载到请包括本文地址:https://kexue.fm/archives/6736
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 18, 2019). 《当Bert遇上Keras:这可能是Bert最简单的打开姿势 》[Blog post]. Retrieved from https://kexue.fm/archives/6736
@online{kexuefm-6736,
title={当Bert遇上Keras:这可能是Bert最简单的打开姿势},
author={苏剑林},
year={2019},
month={Jun},
url={\url{https://kexue.fm/archives/6736}},
}

March 10th, 2021
请教苏神,事件主体抽取中,到这里model = Model([x1_in, x2_in], [ps1, ps2])是输入文本的token_idx,segment_ids预测主体的起始位置,后面train_model = Model([x1_in, x2_in, s1_in, s2_in], [ps1, ps2])作用是什么呢?
作用是建立train_model
专门为了训练模型的?请问博主这种方式是属于keras哪种特性?我好学习一下
是的。模型重用,权重共享。
April 9th, 2021
苏老师我有个问题想请教一下 Bert的Embedding layer参与训练吗?看代码我觉得是参与训练的。但是如果Embedding层的参数一直在更新的话,也就意味着词对应的词向量也一直在变。那对于模型来说是不是很难去捕捉这些词的语义。期待您的回答谢谢!
更新。不要想那么多,模型的输入是one hot,剩下的都是梯度下降参数罢了,该怎么优化,模型自己决定,不用我们着急。
好的谢谢老师
April 22nd, 2021
https://spaces.ac.cn/archives/6736/comment-page-6#%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB
这个代码例子中,x = bert_model([x1_in, x2_in]) 这一行, x1_in 表示输入序列,
x2_in 表示seg_type_id是吗?(0,0,0,....0单句;[0,0,0,1,1,1,...1]双句) 但是这样naming 变量是不是容易歧义?如果默认是( seg_type=[1,1,1,...1,])模型和输入[0,0,0...]表现会有差别吗?
另外一个问题是transformer类的tokenizer工具在encode输入序列后输出的dict有三个{[input_ids],[token_type_ids],[att_mask]}, 但是bert4keras 和 keras_bert都没有[mask]这个,请问是目前还不支持使用mask吗?
1、这是我最早使用bert的代码,有不规范之处很正常;
2、bert4keras自动mask掉padding部分,自动mask才是正常的、智能的,如果没有什么特别需求,还需要人工传入mask矩阵,那才是不科学的。
August 4th, 2021
苏神,你好!请教一下Bert4keras中如何取出隐藏层全部12层或者部分隐藏层的输出结果?
这是个keras问题,跟bert4keras没关系,所以你需要的是学好keras,bert4keras原则上不提供keras教学。
==================
大概的思路如下:
outputs = []
for layer in model.layers:
if xxxx:
outputs.append(layer.output)
new_model = Model(model.inputs, outputs)
拜教了 感谢感谢!
September 16th, 2021
苏神你好,我是看了您的才玩起了bert,当前按照您的思路,我使用bert对词进行编码,然后接了一个双向(16序列)GRU单元实现对文本的编码,然后做分类,但是我看您在做情感分析的时候6g的显存都可以跑起来,
我这边现在的情况是,真正跑起来纯使用CPU会占用112g左右的内存,纯使用GPU的时候,我32g的GPU根本不够用,运行起来就OOM killed,您知道这是什么情况吗?期待您的回复,谢谢
GRU我没接过,理论上接了也不会有太大变化。你这问题我猜不到什么原因,理论上BERT base的简单finetune,6g显存是足够的。
我对比了下,主要是这些矩阵转换耗费了大量的内存,我也非常疑惑,因为我的输入是包含文本句子级维度和句子中单词级维度,然后bert的输入就必须要求我把句子维度先消解,然后编码之后,又必须再把句子维度恢复,这样就多出了两个相反的矩阵操作,通过实验发现确实是这两个矩阵操作耗费大量内存,请教下苏神我该怎么处理呢,因为想了很多办法,这个转换又是必须的
# 消解句子维度,转换成bert需要的输入形式
input_1 = tf.reshape(inputs[0], (-1, maxlen_word))
input_2 = tf.reshape(inputs[1], (-1, maxlen_word))
x = bert_model([input_1, input_2])
x = Lambda(lambda x: x[:, 0])(x)
# 恢复句子级维度,以便后续使用GRU单元编码
x = tf.reshape(x, shape=(-1, maxlen_sentence, 768))
配置是:maxlen_word——256,maxlen_sentence——8,训练一个batch_size才取值16,内存基本就要占用90g左右了,这里就很困惑,我一个batch_size才取16,理论上即使矩阵变换也不会占用很大内存的吧,然后我降低batch_size或者降低maxlen_sentence取值,内存消耗确实会大幅减少,实在是不太懂了苏神
又word又sentence的,你这等价于总的maxlen是256*8=2048了。你倒是看看我的参考脚本用的maxlen是多少...你这maxlen相当于我在1060上用的20倍了,用你90G显存算少了。
哦,我好像明白了,我虽然是一次16个样本,但是消解完句子之后变成了128个句子,这样等于批次变成128 * 256,确实庞大了,感谢苏神,想的有点简单了。
还能再请教一个问题吗,就是如果这样的设计,那我如果使用keras的multi_gpu_model这个功能,加入我有四块GPU,是不是一个batch_size就会平均分配给四个GPU,这样每一块每次就变成4个样本,4 * 8 = 32个句子,这样应该是不是就能玩起来了
大概是这样算吧。
苏神,我又碰到一个问题,我做一个分类,将下面的层设置为True和False效果差距较大,设置为False一两个epoch就能达到一个还可以的效果,但是设置为True的时候,100个epoch都不收敛,验证集和训练集指标一直很低,每一个eopch没有什么明显的变化,这个合理正常吗?
for l in bert_model.layers:
l.trainable = True
不正常,但我也看不懂什么原因。
September 29th, 2021
@苏剑林|comment-17454
这几天试了下,感觉是bert参数全部放开,学习率和我后面的网络相互制衡的原因,后面网络复杂了,学习率低一开始就比较低,收敛也慢,现在在尝试仅仅开放bert高层的参数训练,就可以玩起来了
这个应该是了,BERT后面不宜接太多新的层,不然要专门分层设置学习率才好
December 16th, 2021
您好大佬,有个疑惑,请问只用一个模型能同时做文本分类和NER吗,比如输入的是[cls]+原文,然后用这同一个输入,cls的encoding用来接个分类层,而[cls]+原文这部分的每个字符的encoding接用于NER的网络,两个任务的loss合成一个loss一起训练,不知道可不可以
理论上肯定可以~实际效果实验了才知道。
April 1st, 2022
model = Model([x1_in, x2_in], [ps1, ps2])
train_model = Model([x1_in, x2_in, s1_in, s2_in], [ps1, ps2])
您好,想请教一下,这里如不用参数共享,直接用model = Model([x1_in, x2_in], [ps1, ps2]),利用这个模型进行训练,即双输入双输出,预测实体边界,这样是否合适呢,请您指教
在我的设计中,loss要用到s1_in, s2_in,所以要新建一个训练专用的模型。如果你的设计没用到s1_in, s2_in,那就可以像你说的那样做。