






3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 249577位读者 |前言 #
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型 #
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
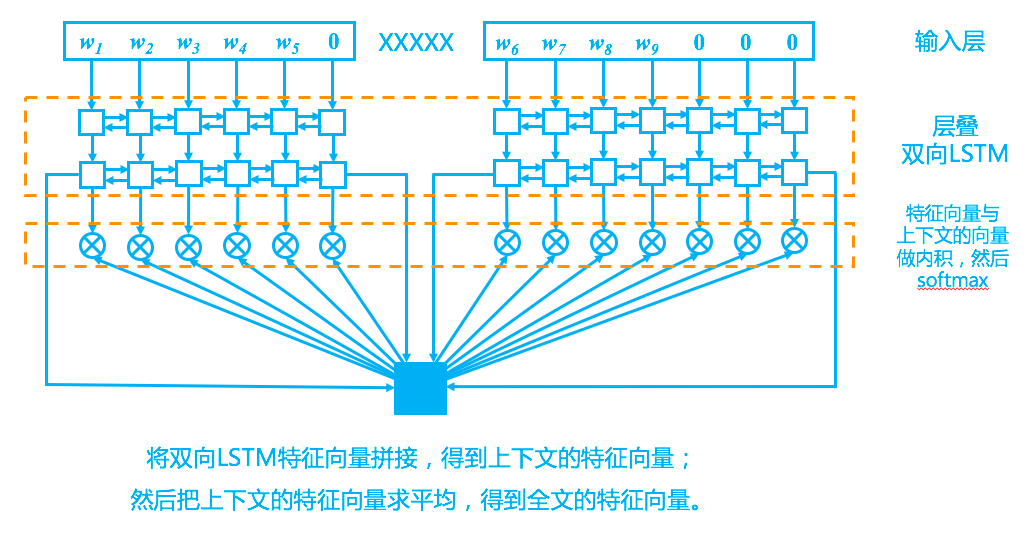
完形填空模型
初步分析 #
首先留意到,这个任务就是从上下文中挑选一个词来填到空缺的位置,如
【篇章】
1 ||| 工商 协进会 报告 , 12月 消费者 信心 上升 到 78.1 , 明显 高于 11月 的 72 。
2 ||| 另 据 《 华尔街 日报 》 报道 , 2013年 是 1995年 以来 美国 股市 表现 最 好 的 一 年 。
3 ||| 这 一 年 里 , 投资 美国 股市 的 明智 做法 是 追 着 “ 傻钱 ” 跑 。
4 ||| 所谓 的 “ 傻钱 ” XXXXX , 其实 就 是 买 入 并 持有 美国 股票 这样 的 普通 组合 。
5 ||| 这个 策略 要 比 对冲 基金 和 其它 专业 投资者 使用 的 更为 复杂 的 投资 方法 效果 好 得 多 。【问题-填空类】
所谓 的 “ 傻钱 ” XXXXX , 其实 就 是 买 入 并 持有 美国 股票 这样 的 普通 组合 。【答案】
策略
熟悉自然语言处理的朋友会联想到,这个任务本身跟语言模型差不多,甚至说这个任务应该更简单一些,因为语言模型是从前$n$个词中预测下一个词,这个预测要遍历词表中所有词,而这个完形填空任务只需要从上下文中挑,大大缩小了收缩范围。当然,两者的焦点是不一样的,语言模型关心的是概率分布,而完形填空关心的是预测正确率。
上下文编码 #
按照经验,对于语言模型建模来说,LSTM效果是最好的,因此这里同样使用LSTM,为了更好地捕捉全局语义信息,堆叠了多层的双向LSTM,当然,对于NLP来说,这都是套路了。
首先,我们以“XXXXX”断开材料,分为上文和下文,然后上文和下文依次输入到同一个双向LSTM中(算两次,而不是拼在一起算一次),得到各自的特征。也就是说,上下文的LSTM是共享参数的。为什么这样呢?原因很简单,因为我们自己在阅读上下文时,用的只是同一个大脑呀,没必要区别对待。有了一层LSTM,那就可以层叠多个,这也是套路了。至于多少层适合,则需要看具体的数据集了。对于这个比赛任务来说,两层比单层有明显提升,而三层比两层则没有提高,甚至有些下降。
最后,为了得到整段材料的特征向量(用来做下面的匹配),只需要将双向LSTM的最后的状态向量拼接起来,得到上下文各自的特征向量,然后将两个向量求平均,就得到全局特征向量。
(值得指出的是,如果换成论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》里边的数据集(格式一样,内容换成了人民日报的),同样是本文的模型,LSTM的层数需要3层,最终的准确率也比论文中最好结果有0.5%的提升。)
预测概率 #
接下来的一个问题是:怎么才能实现“在上下文中搜索”而不是在整个词表中搜索呢?
回忆我们做语言模型的时候,如果要在整个词表中搜索,那就要做一个全连接层,节点数是词表的单词数,然后softmax预测概率。我们可以这样看全连接层:我们为词表中的每一个词都分配一个与输出特征维度一样的向量,然后做内积运算,然后做softmax。也就是说,特征与词做配对,是通过内积来实现的。这就提供了参考思路:如果我们让LSTM输出的特征与词向量维度一样大,然后将这个特征与输入的词向量一一做内积(配对),然后就可以做softmax了,这样就实现了只在上下文搜索。
笔者一开始也是用这样的思路的,但这个思路的准确率只能到69%~70%。后来分析了一下,原始的词向量经过多层的LSTM编码后,事实上已经远离了原来词向量的向量空间了,所以,与其“长途跋涉”地与输入的词向量配对,倒不如直接跟LSTM的中间状态向量配对?至少在同一层LSTM中,状态向量之间是比较接近的(指的是处于同一的向量空间),匹配起来应该容易一点。
实验证明了笔者的猜想,经过改进后的模型,在官方提供的验证集达到了73%~74%左右的准确率,测试集能达到75%~76%的准确率。后来再经过一段时间的实验,也没有明显提高,所以就把这个模型提交上去了。
实现细节 #
事实上笔者不是很懂调参,因此下面的代码的参数不一定是最优,期待有兴趣的调参高手能优化各个参数,给出更好的结果。笔者认为,哪怕对于本文的模型来说,我们自己给出的结果还不是最优的。
下面是在模型的实现中,一些较为重要的细节:
1、本次的语料领域是童话故事类,我们通过训练语料和额外补充的童话故事语料(爬取方法请参考这里)来预训练Word2Vec词向量,然后就用作LSTM的输入;
2、为了处理未登录词,一般设置一个填充符号UNK(代码中用的ID是0)。因为这里的词向量都是用Word2Vec训练好的,但UNK并没有,所以只开放UNK对应的词向量的训练;
3、需要使用bidirectional_dynamic_rnn来处理好变长序列问题;
4、最后一步做内积之后,需要给填充位置的内积减去一个大常数(代码中减去了$10^{12}$),然后才做softmax以及调用softmax_cross_entropy_with_logits损失函数,原因很简单,内积的softmax才是概率,我们要使得填充位置的概率为0,就要使对应位置的内积结果是一个非常小的负数;
5、假如目标词在上下文多次出现,那么将概率平摊到每一个出现位置中,也就是说,交叉熵的目标不一定是one hot格式的;最后预测的时候,要把重复出现的词的概率相加,然后才排序取最大者。
代码 #
数据集 #
数据集下载:https://github.com/ymcui/cmrc2017
下面的代码也可以在我的Github观看:https://github.com/bojone/CCL_CMRC2017
训练脚本 #
#! -*- coding:utf-8 -*-
#实验环境:tensorflow 1.2
import codecs
import re
import os
import numpy as np
def split_data(text):
words = re.split('[ \n]+', text)
idx = words.index('XXXXX')
return words[:idx],words[idx+1:]
print u'正在读取训练语料...'
train_x = codecs.open('../CMRC2017_train/train.doc_query', encoding='utf-8').read()
train_x = re.split('<qid_.*?\n', train_x)[:-1]
train_x = ['\n'.join([l.split('||| ')[1] for l in re.split('\n+', t) if l.split('||| ')[0]]) for t in train_x]
train_x = [split_data(l) for l in train_x]
train_y = codecs.open('../CMRC2017_train/train.answer', encoding='utf-8').read()
train_y = train_y.split('\n')[:-1]
train_y = [l.split('||| ')[1] for l in train_y]
print u'正在读取验证语料...'
valid_x = codecs.open('../CMRC2017_cloze_valid/cloze.valid.doc_query', encoding='utf-8').read()
valid_x = re.split('<qid_.*?\n', valid_x)[:-1]
valid_x = ['\n'.join([l.split('||| ')[1] for l in re.split('\n+', t) if l.split('||| ')[0]]) for t in valid_x]
valid_x = [split_data(l) for l in valid_x]
valid_y = codecs.open('../CMRC2017_cloze_valid/cloze.valid.answer', encoding='utf-8').read()
valid_y = valid_y.split('\n')[:-1]
valid_y = [l.split('||| ')[1] for l in valid_y]
word_size = 128
if os.path.exists('model.config'): #如果有则读取配置信息
id2word,word2id,embedding_array = pickle.load(open('model.config'))
else: #如果没有则重新训练词向量
import jieba
import codecs
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
from gensim.models import Word2Vec
print u'正在对添加语料进行分词...'
additional = codecs.open('../additional.txt', encoding='utf-8').read().split('\n') #自行从网上爬的童话语料
additional = map(lambda s: jieba.lcut(s, HMM=False), additional)
class data_for_word2vec: #用迭代器将三个语料整合起来
def __iter__(self):
for x in train_x:
yield x[0]
yield x[1]
for x in valid_x:
yield x[0]
yield x[1]
for x in additional:
yield x
word2vec = Word2Vec(data_for_word2vec(), size=word_size, min_count=2, sg=2, negative=10, iter=10)
word2vec.save('word2vec_tk')
from collections import defaultdict
id2word = {i+1:j for i,j in enumerate(word2vec.wv.index2word)}
word2id = defaultdict(int, {j:i for i,j in id2word.items()})
embedding_array = np.array([word2vec[id2word[i+1]] for i in range(len(id2word))])
pickle.dump([id2word,word2id,embedding_array], open('model.config','w'))
import tensorflow as tf
padding_vec = tf.Variable(tf.random_uniform([1, word_size], -0.05, 0.05)) #只对填充向量进行训练,其余向量保持word2vec的结果
embeddings = tf.constant(embedding_array, dtype=tf.float32)
embeddings = tf.concat([padding_vec,embeddings], 0)
L_context = tf.placeholder(tf.int32, shape=[None,None])
L_context_length = tf.placeholder(tf.int32, shape=[None])
R_context = tf.placeholder(tf.int32, shape=[None,None])
R_context_length = tf.placeholder(tf.int32, shape=[None])
L_context_vec = tf.nn.embedding_lookup(embeddings, L_context)
R_context_vec = tf.nn.embedding_lookup(embeddings, R_context)
def add_brnn(inputs, rnn_size, seq_lens, name): #定义单层双向LSTM,上下文公用参数,分别过LSTM然后拼接
rnn_cell_fw = tf.contrib.rnn.BasicLSTMCell(rnn_size)
rnn_cell_bw = tf.contrib.rnn.BasicLSTMCell(rnn_size)
outputs = []
with tf.variable_scope(name_or_scope=name) as vs:
for input,seq_len in zip(inputs,seq_lens):
outputs.append(tf.nn.bidirectional_dynamic_rnn(rnn_cell_fw, rnn_cell_bw, input, sequence_length=seq_len, dtype=tf.float32))
vs.reuse_variables()
return [tf.concat(o[0],2) for o in outputs], [o[1] for o in outputs]
[L_outputs,R_outputs],[L_final_state,R_final_state] = add_brnn([L_context_vec,R_context_vec], word_size, [L_context_length,R_context_length], name='LSTM_1')
[L_outputs,R_outputs],[L_final_state,R_final_state] = add_brnn([L_outputs,R_outputs], word_size, [L_context_length,R_context_length], name='LSTM_2')
L_context_mask = (1-tf.cast(tf.sequence_mask(L_context_length), tf.float32))*(-1e12) #对填充位置进行mask,注意这里是softmax之前的mask,所以mask不是乘以0,而是减去1e12
R_context_mask = (1-tf.cast(tf.sequence_mask(R_context_length), tf.float32))*(-1e12)
context_mask = tf.concat([L_context_mask,R_context_mask], 1)
outputs = tf.concat([L_outputs,R_outputs], 1)
final_state = (tf.concat([L_final_state[0][1], L_final_state[1][1]], 1) + tf.concat([R_final_state[0][1], R_final_state[1][1]], 1))/2 #双向拼接、上下文取平均,得到encode向量
attention = context_mask + tf.matmul(outputs, tf.expand_dims(final_state, 2))[:,:,0] #encode向量与每个时间步状态向量做内积,然后mask,然后softmax
sample_labels = tf.placeholder(tf.float32, shape=[None,None])
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=sample_labels, logits=attention))
pred = tf.nn.softmax(attention)
train_step = tf.train.AdamOptimizer().minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
train_x = [([word2id[i] for i in j[0]] if j[0] else [0], [word2id[i] for i in j[1]] if j[1] else [0]) for j in train_x] #词序列ID化
train_y = [word2id[i] for i in train_y]
valid_x = [([word2id[i] for i in j[0]] if j[0] else [0], [word2id[i] for i in j[1]] if j[1] else [0]) for j in valid_x]
valid_y = [word2id[i] for i in valid_y]
def construct_sample(x, y, i):
return x[i][0], x[i][1], y[i]
train_x = [construct_sample(train_x, train_y, i) for i in range(len(train_x))] #输入输出配对,构成训练样本
valid_x = [construct_sample(valid_x, valid_y, i) for i in range(len(valid_x))]
batch_size = 160
def generate_batch_data(data, batch_size): #生成单个batch
np.random.shuffle(data)
batch = []
for x in data:
batch.append(x)
if len(batch) == batch_size:
l0 = [len(x[0]) for x in batch]
l1 = [len(x[1]) for x in batch]
x0 = np.array([x[0]+[0]*(max(l0)-len(x[0])) for x in batch])
x1 = np.array([x[1]+[0]*(max(l1)-len(x[1])) for x in batch])
x2 = np.array([[x[2]] for x in batch])
y = (np.hstack([x0,x1])==x2).astype(np.float32)
yield (x0,
x1,
y/y.sum(axis=1).reshape((-1,1)),
np.array(l0),
np.array(l1),
x2
)
batch = []
if batch:
l0 = [len(x[0]) for x in batch]
l1 = [len(x[1]) for x in batch]
x0 = np.array([x[0]+[0]*(max(l0)-len(x[0])) for x in batch])
x1 = np.array([x[1]+[0]*(max(l1)-len(x[1])) for x in batch])
x2 = np.array([[x[2]] for x in batch])
y = (np.hstack([x0,x1])==x2).astype(np.float32)
yield (x0,
x1,
y/y.sum(axis=1).reshape((-1,1)),
np.array(l0),
np.array(l1),
x2
)
batch = []
import datetime
import json
epochs = 30
saver = tf.train.Saver()
if not os.path.exists('./tk'):
os.mkdir('./tk')
try:
saver.restore(sess, './tk/tk_highest.ckpt')
except:
pass
def cumsum_proba(x, y): #对相同项的概率进行合并
tmp = {}
for i,j in zip(x, y):
if i in tmp:
tmp[i] += j
else:
tmp[i] = j
return tmp.keys()[np.argmax(tmp.values())]
highest_acc = 0.
train_log = {'loss':[], 'accuracy':[]}
for e in range(epochs):
train_data = list(generate_batch_data(train_x, batch_size))
count = 0
batch = 0
for x in train_data:
if batch % 10 == 0:
loss_ = sess.run(loss, feed_dict={L_context:x[0], R_context:x[1], sample_labels:x[2], L_context_length:x[3], R_context_length:x[4]})
print '%s, epoch %s, trained on %s samples, loss: %s'%(datetime.datetime.now(), e+1, count, loss_)
saver.save(sess, './tk/tk_%s.ckpt'%e) #每个epoch保存一次
train_log['loss'].append(float(loss_))
json.dump(train_log, open('train.log', 'w'))
sess.run(train_step, feed_dict={L_context:x[0], R_context:x[1], sample_labels:x[2], L_context_length:x[3], R_context_length:x[4]})
if batch % 100 == 0:
valid_data = list(generate_batch_data(valid_x, batch_size))
r = 0.
for x in valid_data:
p = sess.run(pred, feed_dict={L_context:x[0], R_context:x[1], sample_labels:x[2], L_context_length:x[3], R_context_length:x[4]})
w = np.hstack([x[0],x[1]])
r += (np.array([cumsum_proba(s,t) for s,t in zip(w, p)]) == x[5].reshape(-1)).sum()
acc = r/len(valid_x)
print '%s, valid accuracy %s'%(datetime.datetime.now(), acc)
train_log['accuracy'].append(acc)
if highest_acc <= acc:
highest_acc = acc
saver.save(sess, './tk/tk_highest.ckpt') #历史最好也保存一次
batch += 1
count += len(x[0])预测脚本 #
#! -*- coding:utf-8 -*-
#实验环境:tensorflow 1.2
import pickle
import numpy as np
id2word,word2id,embedding_array = pickle.load(open('model.config'))
word_size = embedding_array.shape[1]
import tensorflow as tf
padding_vec = tf.Variable(tf.random_uniform([1, word_size], -0.05, 0.05))
embeddings = tf.constant(embedding_array, dtype=tf.float32)
embeddings = tf.concat([padding_vec,embeddings], 0)
L_context = tf.placeholder(tf.int32, shape=[None,None])
L_context_length = tf.placeholder(tf.int32, shape=[None])
R_context = tf.placeholder(tf.int32, shape=[None,None])
R_context_length = tf.placeholder(tf.int32, shape=[None])
L_context_vec = tf.nn.embedding_lookup(embeddings, L_context)
R_context_vec = tf.nn.embedding_lookup(embeddings, R_context)
def add_brnn(inputs, rnn_size, seq_lens, name):
rnn_cell_fw = tf.contrib.rnn.BasicLSTMCell(rnn_size)
rnn_cell_bw = tf.contrib.rnn.BasicLSTMCell(rnn_size)
outputs = []
with tf.variable_scope(name_or_scope=name) as vs:
for input,seq_len in zip(inputs,seq_lens):
outputs.append(tf.nn.bidirectional_dynamic_rnn(rnn_cell_fw, rnn_cell_bw, input, sequence_length=seq_len, dtype=tf.float32))
vs.reuse_variables()
return [tf.concat(o[0],2) for o in outputs], [o[1] for o in outputs]
[L_outputs,R_outputs],[L_final_state,R_final_state] = add_brnn([L_context_vec,R_context_vec], word_size, [L_context_length,R_context_length], name='LSTM_1')
[L_outputs,R_outputs],[L_final_state,R_final_state] = add_brnn([L_outputs,R_outputs], word_size, [L_context_length,R_context_length], name='LSTM_2')
L_context_mask = (1-tf.cast(tf.sequence_mask(L_context_length), tf.float32))*(-1e12)
R_context_mask = (1-tf.cast(tf.sequence_mask(R_context_length), tf.float32))*(-1e12)
context_mask = tf.concat([L_context_mask,R_context_mask], 1)
outputs = tf.concat([L_outputs,R_outputs], 1)
final_state = (tf.concat([L_final_state[0][1], L_final_state[1][1]], 1) + tf.concat([R_final_state[0][1], R_final_state[1][1]], 1))/2
attention = context_mask + tf.matmul(outputs, tf.expand_dims(final_state, 2))[:,:,0]
sample_labels = tf.placeholder(tf.float32, shape=[None,None])
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=sample_labels, logits=attention))
pred = tf.nn.softmax(attention)
train_step = tf.train.AdamOptimizer().minimize(loss)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
saver = tf.train.Saver()
saver.restore(sess, './tk/tk_highest.ckpt')
import re
def split_data(text):
words = re.split('[ \n]+', text)
idx = words.index('XXXXX')
return words[:idx],words[idx+1:]
def cumsum_proba(x, y):
tmp = {}
for i,j in zip(x, y):
if i in tmp:
tmp[i] += j
else:
tmp[i] = j
return tmp.keys()[np.argmax(tmp.values())]
def predict(text): #输入的text为字符串,用空格隔开分词结果,待填空位置用XXXXX表示
text = split_data(text)
text = [word2id[i] for i in text[0]] if text[0] else [0], [word2id[i] for i in text[1]] if text[1] else [0]
p = sess.run(pred, feed_dict={L_context:[text[0]], R_context:[text[1]], L_context_length:[len(text[0])], R_context_length:[len(text[1])]})
return id2word.get(cumsum_proba(text[0]+text[1], p[0]),' ')
if __name__ == '__main__':
import codecs
import os
import sys
vaild_name = sys.argv[1]
output_name = sys.argv[2]
text = codecs.open(vaild_name, encoding='utf-8').read()
valid_x = re.split('<qid_.*?\n', text)[:-1]
valid_x = ['\n'.join([l.split('||| ')[1] for l in re.split('\n+', t) if l.split('||| ')[0]]) for t in valid_x]
valid_x = [split_data(l) for l in valid_x]
valid_x = [([word2id[i] for i in j[0]] if j[0] else [0], [word2id[i] for i in j[1]] if j[1] else [0]) for j in valid_x]
batch_size = 160
def generate_batch_data(data, batch_size):
batch = []
for x in data:
batch.append(x)
if len(batch) == batch_size:
l0 = [len(x[0]) for x in batch]
l1 = [len(x[1]) for x in batch]
x0 = np.array([x[0]+[0]*(max(l0)-len(x[0])) for x in batch])
x1 = np.array([x[1]+[0]*(max(l1)-len(x[1])) for x in batch])
yield (x0,
x1,
np.array(l0),
np.array(l1),
)
batch = []
if batch:
l0 = [len(x[0]) for x in batch]
l1 = [len(x[1]) for x in batch]
x0 = np.array([x[0]+[0]*(max(l0)-len(x[0])) for x in batch])
x1 = np.array([x[1]+[0]*(max(l1)-len(x[1])) for x in batch])
yield (x0,
x1,
np.array(l0),
np.array(l1),
)
batch = []
valid_data = list(generate_batch_data(valid_x, batch_size))
valid_result = []
for x in valid_data:
p = sess.run(pred, feed_dict={L_context:x[0], R_context:x[1], L_context_length:x[2], R_context_length:x[3]})
w = np.hstack([x[0],x[1]])
valid_result.extend(np.array([cumsum_proba(s,t) for s,t in zip(w, p)]))
#生成讯飞杯要求的评测格式
names = re.findall('<qid_\d+>', text)
s = '\n'.join(names[i]+' ||| '+id2word.get(j,' ') for i,j in enumerate(valid_result))
with codecs.open(output_name, 'w', encoding='utf-8') as f:
f.write(s)转载到请包括本文地址:https://kexue.fm/archives/4564
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 03, 2017). 《开学啦!咱们来做完形填空~(讯飞杯) 》[Blog post]. Retrieved from https://kexue.fm/archives/4564
@online{kexuefm-4564,
title={开学啦!咱们来做完形填空~(讯飞杯)},
author={苏剑林},
year={2017},
month={Sep},
url={\url{https://kexue.fm/archives/4564}},
}

May 30th, 2018
y = (np.hstack([x0,x1])==x2).astype(np.float32),楼主请问这句目的是什么?==比较两个对象的值,但不是不可能相等吗?
np.hstack([x0,x1])==x2是逐位判断是否相等,也就是找出答案所在位置。
June 1st, 2018
你好,我想问一下我们这个完形填空不是应该用cbow模型吗?为什么使用的是skip gram模型
我一直在想如果这个真的变成我们平时做的四个选项的完形填空该怎么做,那么是词表变成四个选项了吗?
1、词向量以skip gram为优,跟任务关系不大;
2、选项形式的完形填空方法很多。比如分别填入每个选项,给句子打分;或者同样做成本文类似的模型,只是答案标签的构造方式有所改变。
我现在想不到答案标签要怎么构造,苏老师能不能稍微指导一下
August 20th, 2018
请问有什么问题,你是怎么解决的?
August 27th, 2018
loss一直为nan,attention也是nan,不知道为什么
September 6th, 2018
楼主您好,方法generate_batch_data更具体的任务是什么?
没看明白你问的是什么?
October 18th, 2018
[...]开学啦!咱们来做完形填空~(讯飞杯)[...]
March 8th, 2019
老师 您好,我既然已经求得train.py的tk_highest.ckpt 那么对于我来说 预测脚本 有何意义
没看到
saver.restore(sess, './tk/tk_highest.ckpt')
这一句?
May 22nd, 2019
老师您好,请问您训练的语料库就只有自行爬取的吗,能提供一下已经训练好的词向量model.config吗
很久前的文章了,结果早就没有保存了。