






18
Nov
Adam的epsilon如何影响学习率的Scaling Law?
By 苏剑林 | 2024-11-18 | 34021位读者 |上一篇文章《当Batch Size增大时,学习率该如何随之变化?》我们从多个角度讨论了学习率与Batch Size之间的缩放规律,其中对于Adam优化器我们采用了SignSGD近似,这是分析Adam优化器常用的手段。那么一个很自然的问题就是:用SignSGD来近似Adam究竟有多科学呢?
我们知道,Adam优化器的更新量分母会带有一个$\epsilon$,初衷是预防除零错误,所以其值通常很接近于零,以至于我们做理论分析的时候通常选择忽略掉它。然而,当前LLM的训练尤其是低精度训练,我们往往会选择偏大的$\epsilon$,这导致在训练的中、后期$\epsilon$往往已经超过梯度平方大小,所以$\epsilon$的存在事实上已经不可忽略。
因此,这篇文章我们试图探索$\epsilon$如何影响Adam的学习率与Batch Size的Scaling Law,为相关问题提供一个参考的计算方案。
SoftSign #
由于是接着上一篇文章介绍,所以就不再重复相关背景了。为了探究$\epsilon$的作用,我们从SignSGD换到SoftSignSGD,即$\newcommand{sign}{\mathop{\text{sign}}}\tilde{\boldsymbol{\varphi}}_B = \sign(\tilde{\boldsymbol{g}}_B)$变成$\tilde{\boldsymbol{\varphi}}_B = \text{softsign}(\tilde{\boldsymbol{g}}_B)$,其中
\begin{equation}\sign(x)=\frac{x}{\sqrt{x^2}}\quad\to\quad\text{softsign}(x, \epsilon)=\frac{x}{\sqrt{x^2+\epsilon^2}}\end{equation}
这个形式无疑更贴近更贴近Adam。但在此之前,我们需要确认$\epsilon$是否真的不可忽略,才能确定是否有进一步研究的价值。
在Keras的Adam实现中,$\epsilon$的默认值是$10^{-7}$,在Torch中则是$10^{-8}$,这时候梯度绝对值小于$\epsilon$几率还不算大;但在LLM中,$\epsilon$的普遍取值是$10^{-5}$(比如LLAMA2),当训练进入“正轨”后,梯度绝对值小于$\epsilon$的分量将会很普遍了,所以$\epsilon$的影响是显著的。
这个跟LLM的参数量也有一定关系。一个能稳定训练的模型,不管参数量多大,它的梯度模长大小大致都在同一数量级,这是反向传播的稳定性决定的(参考《训练1000层的Transformer究竟有什么困难?》)。因此,参数量越大的模型,平均下来每个参数的梯度绝度值就相对变小了,从而$\epsilon$的作用就更突出了。
值得指出的是,$\epsilon$的引入实际上提供了Adam与SGD之间的一个插值,这是因为当$x\neq 0$时
\begin{equation}\lim_{\epsilon\to \infty}\epsilon\,\text{softsign}(x, \epsilon)=\lim_{\epsilon\to \infty}\frac{x \epsilon}{\sqrt{x^2+\epsilon^2}} = x\end{equation}
所以,$\epsilon$越大,Adam表现越接近SGD。
S型近似 #
确认了引入$\epsilon$必要性后,我们着手开始分析。在分析过程中,我们将会反复遇到S型函数,所以还有一个准备工作是探究S型函数的简单近似。
S型函数相比大家已经见怪不怪,上一节引入的$\text{softsign}$函数本身就是之一,上一篇文章分析过程中的$\text{erf}$函数也是一例,此外还有$\tanh$、$\text{sigmoid}$等。接下来我们处理的是满足如下特性的S型函数$S(x)$:
1、全局光滑且单调递增;
2、奇函数,值域是$[-1,1]$;
3、在原点处斜率为$k > 0$。
对于这类函数,我们考虑两种近似。第一种近似跟$\text{softsign}$类似:
\begin{equation}S(x)\approx \frac{x}{\sqrt{x^2 + 1/k^2}}\end{equation}
它大概是保留$S(x)$如上3点性质的最简单函数了;第二种近似是基于$\text{clip}$函数:
\begin{equation}S(x)\approx \text{clip}(kx, -1, 1) \triangleq \left\{\begin{aligned}&1, &kx\geq 1 \\
&kx, &-1 < kx < 1\\
&-1, &kx \leq -1\end{aligned}\right.\end{equation}
这本质上是一个分段线性函数,放弃了全局光滑的性质,但分段线性会使得积分算起来更容易,我们很快就会看到这一点。
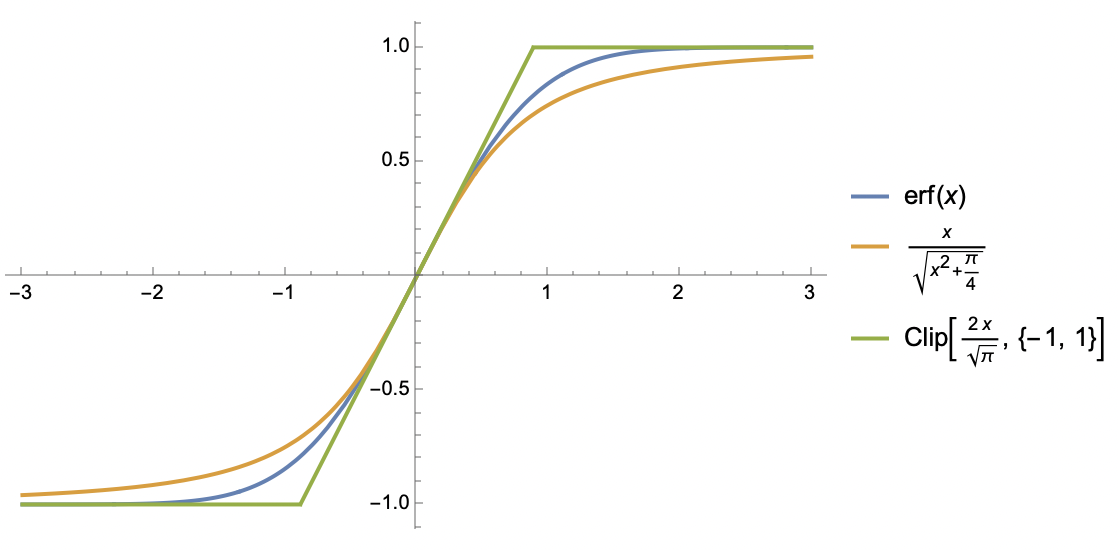
Erf函数与它的两种近似
均值估计 #
事不宜迟,沿着上一篇文章的方法,出发点还是
\begin{equation}\mathbb{E}[\mathcal{L}(\boldsymbol{w} - \eta\tilde{\boldsymbol{\varphi}}_B)] \approx \mathcal{L}(\boldsymbol{w}) - \eta\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B]^{\top}\boldsymbol{g} + \frac{1}{2}\eta^2 \text{Tr}(\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B\tilde{\boldsymbol{\varphi}}_B^{\top}]\boldsymbol{H})\end{equation}
我们需要做的事情就是估计$\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B]$和$\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B\tilde{\boldsymbol{\varphi}}_B^{\top}]$。
这一节我们算的是$\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B]$,为此我们需要用$\text{clip}$函数去近似$\text{softsign}$函数:
\begin{equation}\text{softsign}(x, \epsilon)\approx \text{clip}(x/\epsilon, -1, 1) = \left\{\begin{aligned}&1, & x/\epsilon \geq 1 \\
& x / \epsilon, & -1 < x/\epsilon < 1 \\
&-1, & x/\epsilon \leq -1 \\
\end{aligned}\right.\end{equation}
然后我们有
\begin{equation}\begin{aligned}
\mathbb{E}[\tilde{\varphi}_B] =&\, \mathbb{E}[\text{softsign}(g + \sigma z/\sqrt{B}, \epsilon)] \approx \mathbb{E}[\text{clip}(g/\epsilon + \sigma z/\epsilon\sqrt{B},-1, 1)] \\[5pt]
=&\,\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty} \text{clip}(g/\epsilon + \sigma z/\epsilon\sqrt{B},-1, 1) e^{-z^2/2}dz \\[5pt]
=&\,\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{-(g+\epsilon)\sqrt{B}/\sigma} (-1)\times e^{-z^2/2}dz + \frac{1}{\sqrt{2\pi}}\int_{-(g-\epsilon)\sqrt{B}/\sigma}^{\infty} 1\times e^{-z^2/2}dz \\[5pt]
&\,\qquad\qquad + \frac{1}{\sqrt{2\pi}}\int_{-(g+\epsilon)\sqrt{B}/\sigma}^{-(g-\epsilon)\sqrt{B}/\sigma} (g/\epsilon + \sigma z/\epsilon\sqrt{B})\times e^{-z^2/2}dz
\end{aligned}\end{equation}
积分形式很复杂,但用Mathematica算并不难,结果可以用$\text{erf}$函数表达出来:
\begin{equation}\frac{1}{2}\left[\text{erf}\left(\frac{a+b}{\sqrt{2}}\right)+\text{erf}\left(\frac{a-b}{\sqrt{2}}\right)\right]+\frac{a}{2b}\left[\text{erf}\left(\frac{a+b}{\sqrt{2}}\right)-\text{erf}\left(\frac{a-b}{\sqrt{2}}\right)\right]+\frac{e^{-(a+b)^2/2} - e^{-(a-b)^2/2}}{b\sqrt{2\pi}}\end{equation}
其中$a = g\sqrt{B}/\sigma, b=\epsilon \sqrt{B}/\sigma$。这个函数看起来比较复杂,但它刚好是$a$的S型函数,值域为$(-1,1)$且在$a=0$处的斜率是$\text{erf}(b/\sqrt{2})/b$,所以利用第一种近似形式
\begin{equation}\mathbb{E}[\tilde{\varphi}_B]\approx\frac{a}{\sqrt{a^2 + b^2 / \text{erf}(b/\sqrt{2})^2}}\approx \frac{a}{\sqrt{a^2 + b^2 + \pi / 2}}=\frac{g/\sigma}{\sqrt{(g^2+\epsilon^2)/\sigma^2 + \pi / 2B}}\label{eq:E-u-approx}\end{equation}
第二个约等号是利用近似$\text{erf}(x)\approx x / \sqrt{x^2 + \pi / 4}$来处理分母中的$\text{erf}(b/\sqrt{2})$。可以说相当幸运,最终的形式并没有太复杂。接着我们有
\begin{equation}\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B]_i \approx \frac{g_i/\sigma_i}{\sqrt{(g_i^2+\epsilon^2)/\sigma_i^2 + \pi / 2B}} = \frac{\text{softsign}(g_i, \epsilon)}{\sqrt{1 + \pi \sigma_i^2 /(g_i^2+\epsilon^2)/2B}}\approx \frac{\text{softsign}(g_i, \epsilon)}{\sqrt{1 + \pi \kappa^2/2B}} = \nu_i \beta\end{equation}
跟上一篇文章一样,最后一个约等号使用了平均场近似,$\kappa^2$是全体$\sigma_i^2 /(g_i^2+\epsilon^2)$的某种平均,而$\nu_i = \text{softsign}(g_i, \epsilon)$以及$\beta = (1 + \pi\kappa^2 / 2B)^{-1/2}$。
方差估计 #
均值也就是一阶矩解决了,现在轮到二阶矩了
\begin{equation}\begin{aligned}
\mathbb{E}[\tilde{\varphi}_B^2] =&\, \mathbb{E}[\text{softsign}(g + \sigma z/\sqrt{B}, \epsilon)^2] \approx \mathbb{E}[\text{clip}(g/\epsilon + \sigma z/\epsilon\sqrt{B},-1, 1)^2] \\[5pt]
=&\,\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{\infty} \text{clip}(g/\epsilon + \sigma z/\epsilon\sqrt{B},-1, 1)^2 e^{-z^2/2}dz \\[5pt]
=&\,\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{-(g+\epsilon)\sqrt{B}/\sigma} (-1)^2\times e^{-z^2/2}dz + \frac{1}{\sqrt{2\pi}}\int_{-(g-\epsilon)\sqrt{B}/\sigma}^{\infty} 1^2\times e^{-z^2/2}dz \\[5pt]
&\,\qquad\qquad + \frac{1}{\sqrt{2\pi}}\int_{-(g+\epsilon)\sqrt{B}/\sigma}^{-(g-\epsilon)\sqrt{B}/\sigma} (g/\epsilon + \sigma z/\epsilon\sqrt{B})^2\times e^{-z^2/2}dz
\end{aligned}\end{equation}
结果同样可以用$\text{erf}$函数表示,但更加冗长,这里就不写出来了,还是那句话,对Mathematica来说这都不是事。视为$a$的函数时,可以发现结果是一条倒钟形的曲线,关于$y$轴对称,上界是$1$,最小值是则在$(0,1)$内。参考$\mathbb{E}[\tilde{\varphi}_B]$的近似式$\eqref{eq:E-u-approx}$,我们选择如下近似
\begin{equation}\mathbb{E}[\tilde{\varphi}_B^2] \approx 1 - \frac{b^2}{a^2 + b^2 + \pi / 2} = 1 - \frac{\epsilon^2/(g^2+\epsilon^2)}{1 + \pi\sigma^2/(g^2+\epsilon^2) / 2B}\end{equation}
有一说一,这个近似的精度并不高,主要是为了计算的方便,但它已经保留了倒钟形、$y$轴对称、上界为1、$b=0$时结果为1、$b\to\infty$结果则为0等关键特性。接下来继续应用平均场近似:
\begin{equation}\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B\tilde{\boldsymbol{\varphi}}_B^{\top}]_{i,i} \approx 1 - \frac{\epsilon^2/(g_i^2+\epsilon^2)}{1 + \pi\sigma_i^2/(g_i^2+\epsilon^2) / 2B}\approx 1 - \frac{\epsilon^2/(g_i^2+\epsilon^2)}{1 + \pi\kappa^2 / 2B} = \nu_i^2 \beta^2 + (1 - \beta^2)\end{equation}
所以$\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B\tilde{\boldsymbol{\varphi}}_B^{\top}]_{i,j}\approx \nu_i \nu_j \beta^2 + \delta_{i,j}(1-\beta^2)$。其中$\delta_{i,j}(1-\beta^2)$这一项就代表了$\tilde{\boldsymbol{\varphi}}$的协方差矩阵$(1-\beta^2)\boldsymbol{I}$,它是一个对角阵,这是可以预料的,因为我们的假设之一是$\tilde{\boldsymbol{\varphi}}$各分量之间的独立性,所以协方差矩阵必然是对角阵。
结果初探 #
由此我们得到
\begin{equation}\eta^* \approx \frac{\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B]^{\top}\boldsymbol{g}}{\text{Tr}(\mathbb{E}[\tilde{\boldsymbol{\varphi}}_B\tilde{\boldsymbol{\varphi}}_B^{\top}]\boldsymbol{H})} \approx \frac{\beta\sum_i \nu_i g_i}{\beta^2\sum_{i,j} \nu_i \nu_j H_{i,j} + (1-\beta^2)\sum_i H_{i,i} }\end{equation}
注意,除了$\beta$外,剩余的其他符号都不依赖于$B$,所以上式已经给出$\eta^*$与$B$的依赖关系。注意为了保证极小值的存在性,我们都会假设$\boldsymbol{H}$矩阵的正定性,而在此假设之下必然有$\sum_{i,j} \nu_i \nu_j H_{i,j} > 0$和$\sum_i H_{i,i} > 0$。
上一篇文章我们说Adam最重要的特性是可能会出现“Surge现象”,即$\eta^*$关于$B$不再是全局的单调递增函数。接下来我们将会证明,$\epsilon > 0$的引入会降低Surge现象出现的几率,并且$\epsilon \to \infty$时完全消失。这个证明并不难,很明显Surge现象出现的必要条件是
\begin{equation}\sum_{i,j} \nu_i \nu_j H_{i,j} - \sum_i H_{i,i} > 0\end{equation}
若否,整个$\eta^*$关于$\beta$便是单调递增的,而$\beta$关于$B$是单调递增的,所以整个$\eta^*$关于$B$单调递增,不存在Surge现象。别忘了$\nu_i = \text{softsign}(g_i, \epsilon)$是关于$\epsilon$的单调递减函数,所以当$\epsilon$增大时$\sum_{i,j} \nu_i \nu_j H_{i,j}$会更小,从而上述不等式成立的可能性更低,并且$\epsilon\to \infty$时$\nu_i$为零,上述不等式不可能再成立,因此Surge现象消失。
进一步,我们可以证明$\epsilon\to\infty$时,结果跟SGD的一致,这只需要留意到
\begin{equation}\frac{\eta^*}{\epsilon} \approx \frac{\beta\sum_i (\epsilon \nu_i) g_i}{\beta^2\sum_{i,j} (\epsilon \nu_i)(\epsilon \nu_j) H_{i,j} + \epsilon^2(1-\beta^2)\sum_i H_{i,i} }\end{equation}
我们有极限
\begin{equation}\lim_{\epsilon\to\infty} \beta = 1,\quad\lim_{\epsilon\to\infty} \epsilon \nu_i = g_i, \quad \lim_{\epsilon\to\infty} \epsilon^2(1-\beta^2) = \pi \sigma^2 / 2B\end{equation}
这里$\sigma^2$是全体$\sigma_i^2$的某种平均。于是我们得到当$\epsilon$足够大时有近似
\begin{equation}\frac{\eta^*}{\epsilon} \approx \frac{\sum_i g_i^2}{\sum_{i,j} g_i g_j H_{i,j} + \left(\pi \sigma^2\sum_i H_{i,i}\right)/2B }\end{equation}
右端就是假设梯度协方差矩阵为$(\pi\sigma^2/2B)\boldsymbol{I}$时的SGD结果。
文章小结 #
本文延续了上一篇文章的方法,尝试分析了Adam的$\epsilon$对学习率与Batch Size之间的Scaling Law的影响,结果是一个介乎SGD与SignSGD之间的形式,当$\epsilon$越大,结果越接近SGD,“Surge现象”出现的概率就越低。总的来说,计算结果没有特别让人意外之处,但可以作为分析$\epsilon$作用的一个参考过程。
转载到请包括本文地址:https://kexue.fm/archives/10563
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Nov. 18, 2024). 《Adam的epsilon如何影响学习率的Scaling Law? 》[Blog post]. Retrieved from https://kexue.fm/archives/10563
@online{kexuefm-10563,
title={Adam的epsilon如何影响学习率的Scaling Law?},
author={苏剑林},
year={2024},
month={Nov},
url={\url{https://kexue.fm/archives/10563}},
}

January 8th, 2025
请教苏老师,如果训练过程中梯度变小,接近甚至小于epsilon后,我发现这时候直接降低epsilon,会导致loss先增后降(低于原来水平),猜测loss的增加是因为epsilon降低引起等效“学习率”增加导致,有更好的热切策略能让loss不增加嘛?
采用LAMB optiizer的策略?按weight norm来缩放update。
January 18th, 2025
苏神能解读下这篇文章吗 Scaling Laws for Floating Point Quantization Training
暂不在兴趣范围内
September 24th, 2025
老师您好, 如果结论是【当ϵ越大,结果越接近SGD,“Surge现象”出现的概率就越低】,那我们训练模型的时候就把ϵ设置的非常小就行了?
这个看需求吧,有时候我们希望adam更靠近sgd一些。不过多数时候我们确实会将它设置得很小。