






17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 95795位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
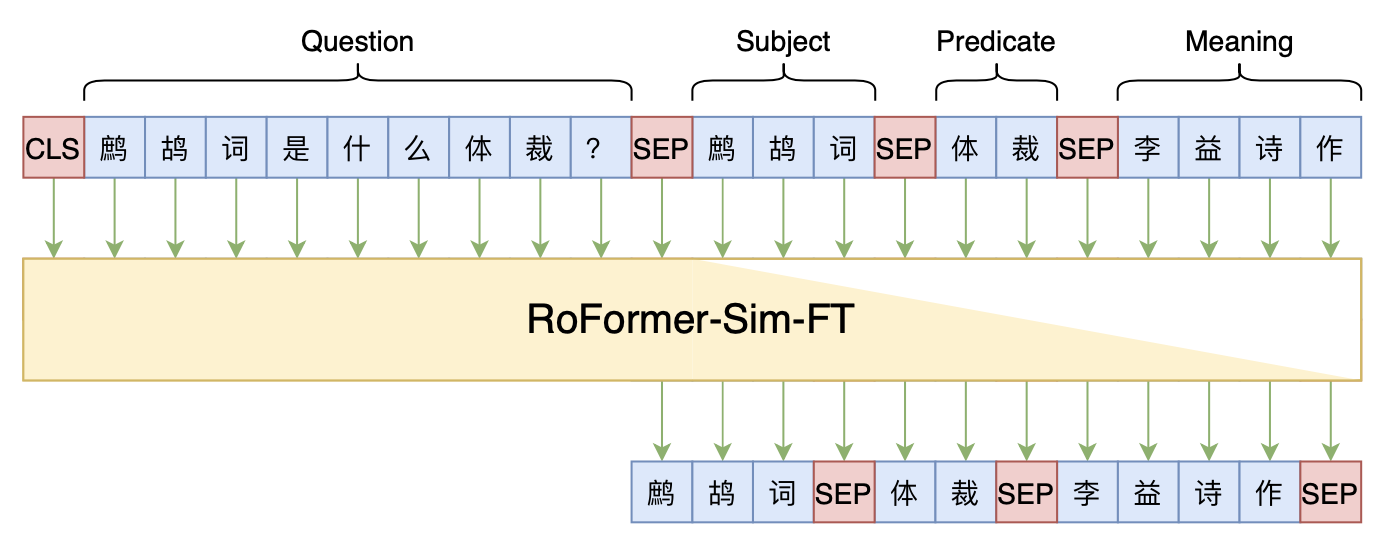
本文baseline模型示意图
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 111408位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
29
Apr
节省显存的重计算技巧也有了Keras版了
By 苏剑林 | 2020-04-29 | 64865位读者 | 引用不少读者最近可能留意到了公众号文章《BERT重计算:用22.5%的训练时间节省5倍的显存开销(附代码)》,里边介绍了一个叫做“重计算”的技巧,简单来说就是用来省显存的方法,让平均训练速度慢一点,但batch_size可以增大好几倍。该技巧首先发布于论文《Training Deep Nets with Sublinear Memory Cost》,其实在2016年就已经提出了,只不过似乎还没有特别流行起来。
探索
公众号文章提到该技巧在pytorch和paddlepaddle都有原生实现了,但tensorflow还没有。但事实上从tensorflow 1.8开始,tensorflow就已经自带了该功能了,当时被列入了tf.contrib这个子库中,而从tensorflow 1.15开始,它就被内置为tensorflow的主函数之一,那就是tf.recompute_grad。
找到tf.recompute_grad之后,笔者就琢磨了一下它的用法,经过一番折腾,最终居然真的成功地用起来了,居然成功地让batch_size从48增加到了144!然而,在继续整理测试的过程中,发现这玩意居然在tensorflow 2.x是失效的...于是再折腾了两天,查找了各种资料并反复调试,最终算是成功地补充了这一缺陷。
最后是笔者自己的开源实现:
该实现已经内置在bert4keras中,使用bert4keras的读者可以升级到最新版本(0.7.5+)来测试该功能。
2
Apr
bert4keras在手,baseline我有:百度LIC2020
By 苏剑林 | 2020-04-02 | 131225位读者 | 引用百度的“2020语言与智能技术竞赛”开赛了,今年有五个赛道,分别是机器阅读理解、推荐任务对话、语义解析、关系抽取、事件抽取。每个赛道中,主办方都给出了基于PaddlePaddle的baseline模型,这里笔者也基于bert4keras给出其中三个赛道的个人baseline,从中我们可以看到用bert4keras搭建baseline模型的方便快捷与简练。
思路简析
这里简单分析一下这三个赛道的任务特点以及对应的baseline设计。
23
Mar
AdaFactor优化器浅析(附开源实现)
By 苏剑林 | 2020-03-23 | 114453位读者 | 引用自从GPT、BERT等预训练模型流行起来后,其中一个明显的趋势是模型越做越大,因为更大的模型配合更充分的预训练通常能更有效地刷榜。不过,理想可以无限远,现实通常很局促,有时候模型太大了,大到哪怕你拥有了大显存的GPU甚至TPU,依然会感到很绝望。比如GPT2最大的版本有15亿参数,最大版本的T5模型参数量甚至去到了110亿,这等规模的模型,哪怕在TPU集群上也没法跑到多大的batch size。
这时候通常要往优化过程着手,比如使用混合精度训练(tensorflow下还可以使用一种叫做bfloat16的新型浮点格式),即省显存又加速训练;又或者使用更省显存的优化器,比如RMSProp就比Adam更省显存。本文则介绍AdaFactor,一个由Google提出来的新型优化器,首发论文为《Adafactor: Adaptive Learning Rates with Sublinear Memory Cost》。AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。
Adam
首先我们来回顾一下常用的Adam优化器的更新过程。设$t$为迭代步数,$\alpha_t$为当前学习率,$L(\theta)$是损失函数,$\theta$是待优化参数,$\epsilon$则是防止溢出的小正数,那么Adam的更新过程为
1
Mar
对抗训练浅谈:意义、方法和思考(附Keras实现)
By 苏剑林 | 2020-03-01 | 346735位读者 | 引用当前,说到深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。本博客里以前所涉及的对抗话题,都是前一种含义,而今天,我们来聊聊后一种含义中的“对抗训练”。
本文包括如下内容:
1、对抗样本、对抗训练等基本概念的介绍;
2、介绍基于快速梯度上升的对抗训练及其在NLP中的应用;
3、给出了对抗训练的Keras实现(一行代码调用);
4、讨论了对抗训练与梯度惩罚的等价性;
5、基于梯度惩罚,给出了一种对抗训练的直观的几何理解。
25
Nov
6个派生优化器的简单介绍及其实现
By 苏剑林 | 2019-11-25 | 72211位读者 | 引用优化器可能是深度学习最“玄学”的一个模块之一了:有时候换一个优化器就能带来明显的提升,有时候别人说提升很多的优化器用到自己的任务上却一丁点用都没有,理论性质好的优化器不一定工作得很好,纯粹拍脑袋而来的优化器也未必就差了。但不管怎样,优化器终究也为热爱“深度炼丹”的同学提供了多一个选择。
近几年来,关于优化器的工作似乎也在慢慢增多,很多论文都提出了对常用优化器(尤其是Adam)的大大小小的改进。本文就汇总一些优化器工作或技巧,并统一给出了代码实现,供读者有需调用。
基本形式
所谓“派生”,就是指相关的技巧都是建立在已有的优化器上的,任意一个已有的优化器都可以用上这些技巧,从而变成一个新的优化器。
已有的优化器的基本形式为:
\begin{equation}\begin{aligned}\boldsymbol{g}_t =&\, \nabla_{\boldsymbol{\theta}} L\\
\boldsymbol{h}_t =&\, f(\boldsymbol{g}_{\leq t})\\
\boldsymbol{\theta}_{t+1} =&\, \boldsymbol{\theta}_t - \gamma \boldsymbol{h}_t
\end{aligned}\end{equation}
其中$\boldsymbol{g}_t$即梯度,而$\boldsymbol{g}_{\leq t}$指的是截止到当前步的所有梯度信息,它们经过某种运算$f$(比如累积动量、累积二阶矩校正学习率等)后得到$\boldsymbol{h}_t$,然后由$\boldsymbol{h}_t$来更新参数,这里的$\gamma$就是指学习率。
6
Nov
Keras:Tensorflow的黄金标准
By 苏剑林 | 2019-11-06 | 98927位读者 | 引用这两周投入了比较多的精力去做bert4keras的开发,除了一些API的规范化工作外,其余的主要工作量是构建预训练部分的代码。在昨天,预训练代码基本构建完毕,并同时在TPU/多GPU环境下测试通过,从而有志(有算力)改进预训练模型的同学多了一个选择。——这可能是目前最为清晰易懂的bert及其预训练代码。
预训练代码链接: https://github.com/bojone/bert4keras/tree/master/pretraining
经过这两周的开发(填坑),笔者的最大感想就是:Keras已经成为了tensorflow的黄金标准了。只要你的代码按照Keras的标准规范写,那可以轻松迁移到tf.keras中去,继而可以非常轻松地在TPU或多GPU环境下训练,真正的几乎是一劳永逸。相反,如果你的写法过于灵活,包括像笔者之前介绍的很多“移花接木”式的Keras技巧,就可能会有不少问题,甚至可能出现的一种情况是:就算你已经在多GPU上跑通了,在TPU上你也死活调不通。

Keras和Tensorflow

最近评论