






9
Jan
局部余弦相似度大,全局余弦相似度一定也大吗?
By 苏剑林 | 2024-01-09 | 28725位读者 | 引用在分析模型的参数时,有些情况下我们会将模型的所有参数当成一个整体的向量,有些情况下我们则会将不同的参数拆开来看。比如,一个7B大小的LLAMA模型所拥有的70亿参数量,有时候我们会将它当成“一个70亿维的向量”,有时候我们会按照模型的实现方式将它看成“数百个不同维度的向量”,最极端的情况下,我们也会将它看成是“七十亿个1维向量”。既然有不同的看待方式,那么当我们要算一些统计指标时,也就会有不同的计算方式,即局部计算和全局计算,这引出了局部计算的指标与全局计算的指标有何关联的问题。
本文我们关心两个向量的余弦相似度。如果两个大向量的维度被拆成了若干组,同一组对应的子向量余弦相似度都很大,那么两个大向量的余弦相似度是否一定就大呢?答案是否定的。特别地,这还跟著名的“辛普森悖论”有关。
问题背景
这个问题源于笔者对优化器的参数增量导致的损失函数变化量的分析。具体来说,假设优化器的更新规则是:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta_t \boldsymbol{u}_t\end{equation}
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 58016位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
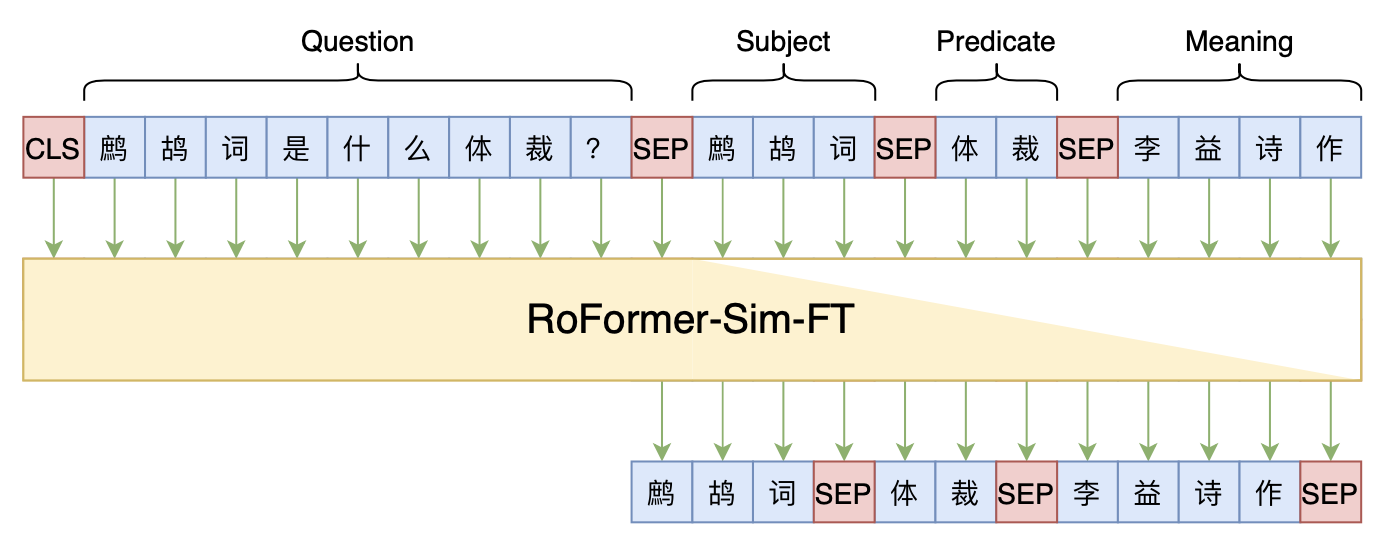
本文baseline模型示意图
1
Sep
从三角不等式到Margin Softmax
By 苏剑林 | 2021-09-01 | 29882位读者 | 引用在《基于GRU和AM-Softmax的句子相似度模型》中我们介绍了AM-Softmax,它是一种带margin的softmax,通常用于用分类做检索的场景。当时通过图示的方式简单说了一下引入margin是因为“分类与排序的不等价性”,但没有比较定量地解释这种不等价性的来源。
在这篇文章里,我们来重提这个话题,从距离的三角不等式的角度来推导和理解margin的必要性。
三角不等式
平时,我们说的距离一般指比较直观的“欧氏距离”,但在数学上距离,距离又叫“度量”,它有公理化的定义,是指定义在某个集合上的二元函数$d(x,y)$,满足:
29
Jul
基于GRU和AM-Softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 305377位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的

将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。

最近评论