






20
Jan
从Wasserstein距离、对偶理论到WGAN
By 苏剑林 | 2019-01-20 | 224030位读者 | 引用
推土机哪家强?成本最低找Wasserstein
2017年的时候笔者曾写过博文《互怼的艺术:从零直达WGAN-GP》,从一个相对通俗的角度来介绍了WGAN,在那篇文章中,WGAN更像是一个天马行空的结果,而实际上跟Wasserstein距离没有多大关系。
在本篇文章中,我们再从更数学化的视角来讨论一下WGAN。当然,本文并不是纯粹地讨论GAN,而主要侧重于Wasserstein距离及其对偶理论的理解。本文受启发于著名的国外博文《Wasserstein GAN and the Kantorovich-Rubinstein Duality》,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。不管怎样,在此先对前辈及前辈的文章表示致敬。
(注:完整理解本文,应该需要多元微积分、概率论以及线性代数等基础知识。还有,本文确实长,数学公式确实多,但是,真的不复杂、不难懂,大家不要看到公式就吓怕了~)
6
Mar
O-GAN:简单修改,让GAN的判别器变成一个编码器!
By 苏剑林 | 2019-03-06 | 262216位读者 | 引用本文来给大家分享一下笔者最近的一个工作:通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。

FFHQ线性插值效果图
18
Feb
恒等式 det(exp(A)) = exp(Tr(A)) 赏析
By 苏剑林 | 2019-02-18 | 70318位读者 | 引用本文的主题是一个有趣的矩阵行列式的恒等式
\begin{equation}\det(\exp(\boldsymbol{A})) = \exp(\text{Tr}(\boldsymbol{A}))\label{eq:main}\end{equation}
这个恒等式在挺多数学和物理的计算中都出现过,笔者都在不同的文献中看到过好几次了。
注意左端是矩阵的指数,然后求行列式,这两步都是计算量非常大的运算;右端仅仅是矩阵的迹(一个标量),然后再做标量的指数。两边的计算量差了不知道多少倍,然而它们居然是相等的!这不得不说是一个神奇的事实。
所以,本文就来好好欣赏一个这个恒等式。
22
Feb
巧断梯度:单个loss实现GAN模型
By 苏剑林 | 2019-02-22 | 47547位读者 | 引用我们知道普通的模型都是搭好架构,然后定义好loss,直接扔给优化器训练就行了。但是GAN不一样,一般来说它涉及有两个不同的loss,这两个loss需要交替优化。现在主流的方案是判别器和生成器都按照1:1的次数交替训练(各训练一次,必要时可以给两者设置不同的学习率,即TTUR),交替优化就意味我们需要传入两次数据(从内存传到显存)、执行两次前向传播和反向传播。
如果我们能把这两步合并起来,作为一步去优化,那么肯定能节省时间的,这也就是GAN的同步训练。
(注:本文不是介绍新的GAN,而是介绍GAN的新写法,这只是一道编程题,不是一道算法题~)
如果在TF中
14
Mar
圆周率节快乐!|| 原来已经写了十年博客~
By 苏剑林 | 2019-03-14 | 80416位读者 | 引用
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 119322位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
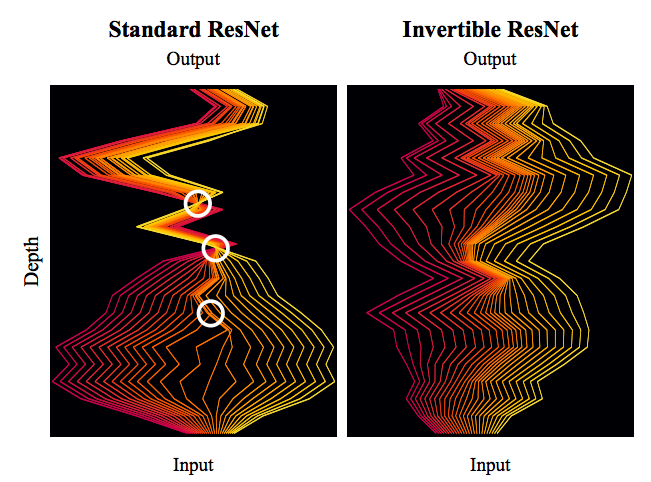
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
6
Nov
Keras:Tensorflow的黄金标准
By 苏剑林 | 2019-11-06 | 79201位读者 | 引用这两周投入了比较多的精力去做bert4keras的开发,除了一些API的规范化工作外,其余的主要工作量是构建预训练部分的代码。在昨天,预训练代码基本构建完毕,并同时在TPU/多GPU环境下测试通过,从而有志(有算力)改进预训练模型的同学多了一个选择。——这可能是目前最为清晰易懂的bert及其预训练代码。
预训练代码链接: https://github.com/bojone/bert4keras/tree/master/pretraining
经过这两周的开发(填坑),笔者的最大感想就是:Keras已经成为了tensorflow的黄金标准了。只要你的代码按照Keras的标准规范写,那可以轻松迁移到tf.keras中去,继而可以非常轻松地在TPU或多GPU环境下训练,真正的几乎是一劳永逸。相反,如果你的写法过于灵活,包括像笔者之前介绍的很多“移花接木”式的Keras技巧,就可能会有不少问题,甚至可能出现的一种情况是:就算你已经在多GPU上跑通了,在TPU上你也死活调不通。

Keras和Tensorflow
11
Nov
JoSE:球面上的词向量和句向量
By 苏剑林 | 2019-11-11 | 72203位读者 | 引用这篇文章介绍一个发表在NeurIPS 2019的做词向量和句向量的模型JoSE(Joint Spherical Embedding),论文名字是《Spherical Text Embedding》。JoSE模型思想上和方法上传承自Doc2Vec,评测结果更加漂亮,但写作有点故弄玄虚之感。不过笔者决定写这篇文章,是因为觉得里边的某些分析过程有点意思,可能会对一般的优化问题都有些参考价值。
优化目标
在思想上,这篇文章基本上跟Doc2Vec是一致的:为了训练句向量,把句子用一个id表示,然后把它也当作一个词,跟句内所有的词都共现,最后训练一个Skip Gram模型,训练的方式都是基于负采样的。跟Doc2Vec不一样的是,JoSE将全体向量的模长都归一化了(也就是只考虑单位球面上的向量),然后训练目标没有用交叉熵,而是用hinge loss:
\begin{equation}\max(0, m - \cos(\boldsymbol{u}, \boldsymbol{v}) - \cos(\boldsymbol{u}, \boldsymbol{d}) + \cos(\boldsymbol{u}', \boldsymbol{v}) + \cos(\boldsymbol{u}', \boldsymbol{d})\label{eq:loss}\end{equation}

最近评论