






6
Mar
O-GAN:简单修改,让GAN的判别器变成一个编码器!
By 苏剑林 | 2019-03-06 | 253537位读者 | 引用本文来给大家分享一下笔者最近的一个工作:通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。

FFHQ线性插值效果图
1
Mar
构造一个显式的、总是可逆的矩阵
By 苏剑林 | 2019-03-01 | 43689位读者 | 引用从《恒等式 det(exp(A)) = exp(Tr(A)) 赏析》一文我们得到矩阵$\exp(\boldsymbol{A})$总是可逆的,它的逆就是$\exp(-\boldsymbol{A})$。问题是$\exp(\boldsymbol{A})$只是一个理论定义,单纯这样写没有什么价值,因为它要把每个$\boldsymbol{A}^n$都算出来。
有没有什么具体的例子呢?有,本文来构造一个显式的、总是可逆的矩阵。
其实思路非常简单,假设$\boldsymbol{x},\boldsymbol{y}$是两个$k$维列向量,那么$\boldsymbol{x}\boldsymbol{y}^{\top}$就是一个$k\times k$的矩阵,我们就来考虑
\begin{equation}\begin{aligned}\exp\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)=&\sum_{n=0}^{\infty}\frac{\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)^n}{n!}\\
=&\boldsymbol{I}+\boldsymbol{x}\boldsymbol{y}^{\top}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{2}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{6}+\dots\end{aligned}\end{equation}
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 101774位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
18
Feb
恒等式 det(exp(A)) = exp(Tr(A)) 赏析
By 苏剑林 | 2019-02-18 | 68366位读者 | 引用本文的主题是一个有趣的矩阵行列式的恒等式
\begin{equation}\det(\exp(\boldsymbol{A})) = \exp(\text{Tr}(\boldsymbol{A}))\label{eq:main}\end{equation}
这个恒等式在挺多数学和物理的计算中都出现过,笔者都在不同的文献中看到过好几次了。
注意左端是矩阵的指数,然后求行列式,这两步都是计算量非常大的运算;右端仅仅是矩阵的迹(一个标量),然后再做标量的指数。两边的计算量差了不知道多少倍,然而它们居然是相等的!这不得不说是一个神奇的事实。
所以,本文就来好好欣赏一个这个恒等式。
26
Feb
非对抗式生成模型GLANN的简单介绍
By 苏剑林 | 2019-02-26 | 69523位读者 | 引用前段时间看到facebook发表了一个非对抗的生成模型GLANN(去年12月挂在arxiv上),号称用非对抗的方式也能生成1024的高清人脸,于是饶有兴致地阅读了一番,确实有点收获,但也有点失望。至于为啥失望,大家阅读下去就明白了。
原论文:《Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors》
机器之心介绍:《为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN》
效果图:

GLANN效果图
14
Mar
圆周率节快乐!|| 原来已经写了十年博客~
By 苏剑林 | 2019-03-14 | 77847位读者 | 引用
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 115654位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
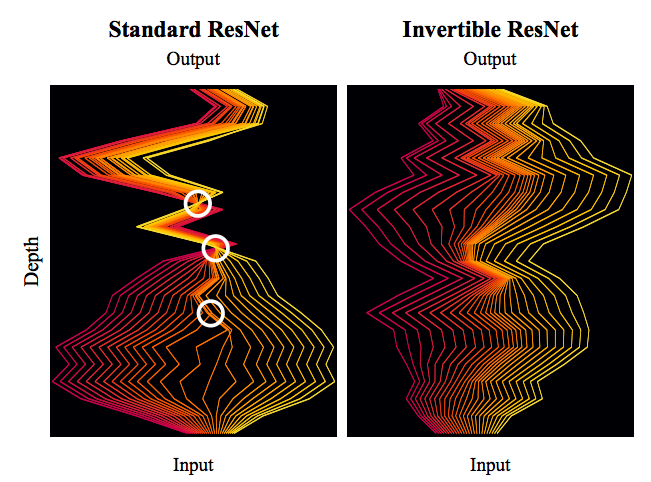
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 90339位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。

最近评论