






20
May
函数光滑化杂谈:不可导函数的可导逼近
By 苏剑林 | 2019-05-20 | 121941位读者 | 引用一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到$\text{argmax}$等操作),所以没法直接用。
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max
后面谈到的大部分内容,基础点就是$\max$操作的光滑近似,我们有:
\begin{equation}\max(x_1,x_2,\dots,x_n) = \lim_{K\to +\infty}\frac{1}{K}\log\left(\sum_{i=1}^n e^{K x_i}\right)\end{equation}
10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 222951位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
\begin{equation}L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\label{eq:base}\end{equation}
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现($f(z)$对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于$z$的连续性,它对应不同的形式:
\begin{equation}\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\end{equation}
当然,离散情况下我们更喜欢将记号$z$换成$y$或者$c$。
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 414970位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
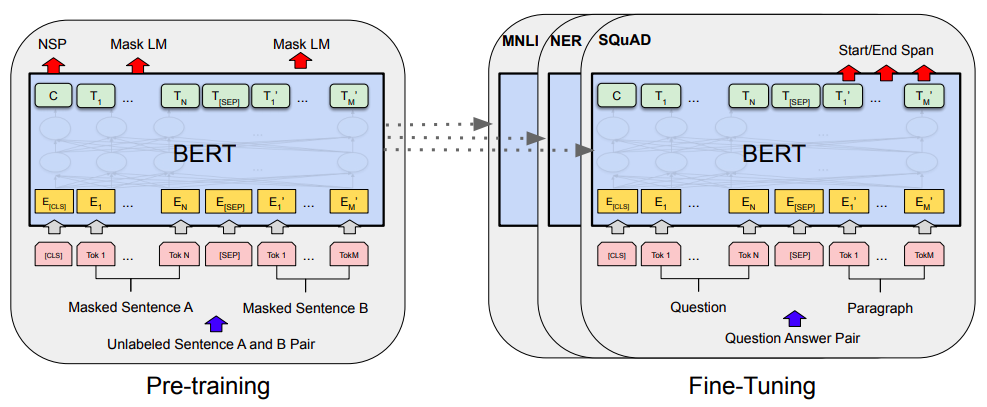
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 81842位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 48828位读者 | 引用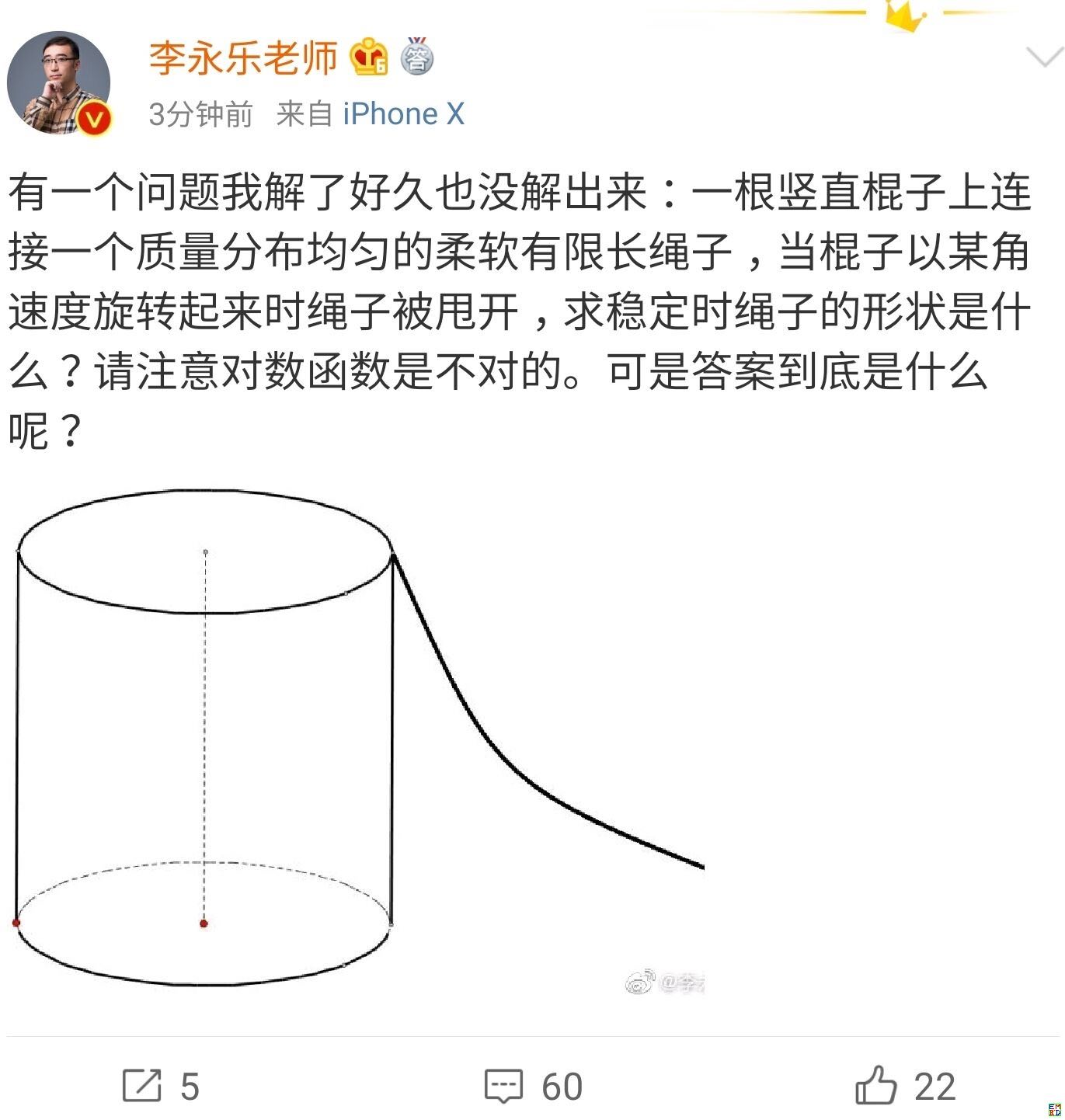
21
Jul
思考:两个椭圆片能粘合成一个立体吗?
By 苏剑林 | 2019-07-21 | 58350位读者 | 引用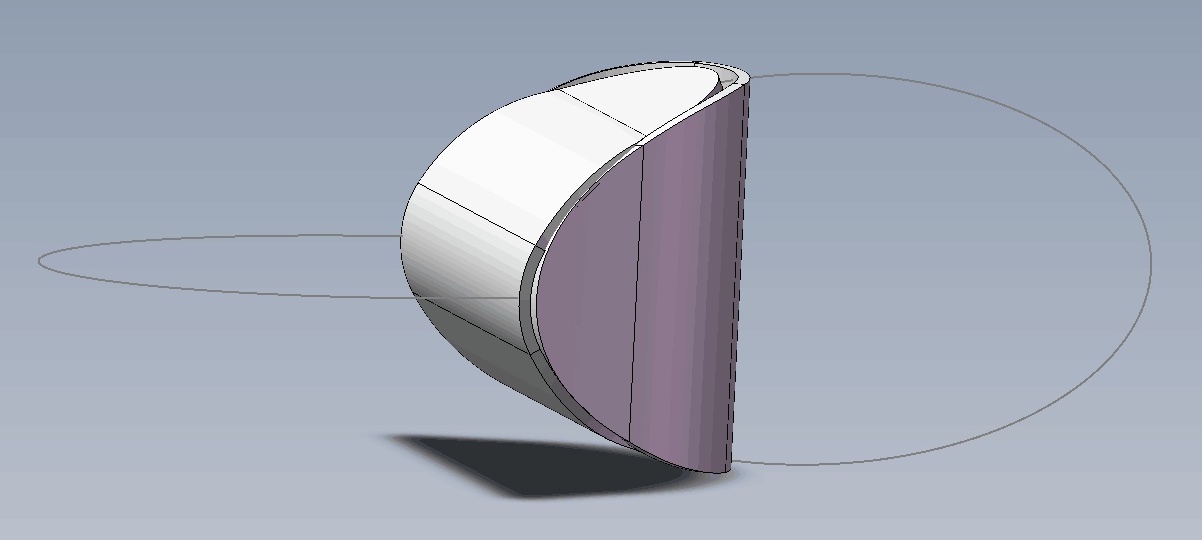
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 98748位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 95163位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。

最近评论