






26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 69862位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 41388位读者 | 引用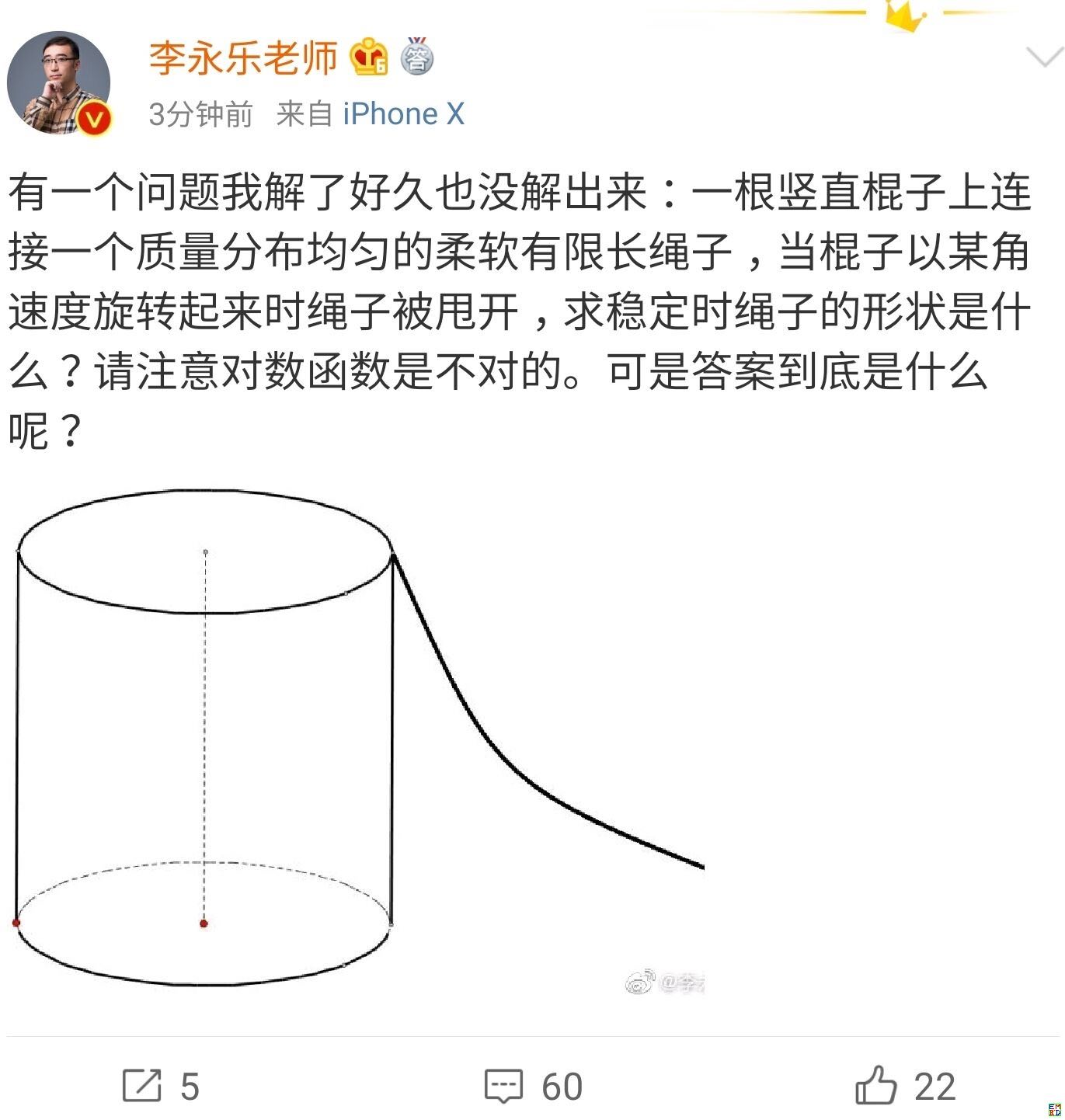
21
Jul
思考:两个椭圆片能粘合成一个立体吗?
By 苏剑林 | 2019-07-21 | 50009位读者 | 引用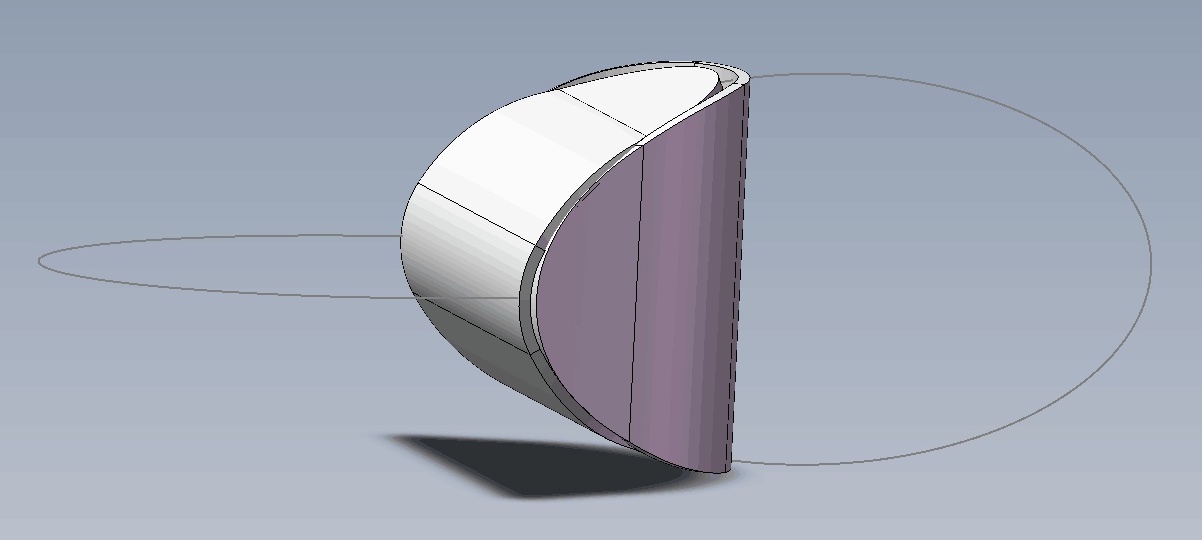
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 86542位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 82078位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 266202位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
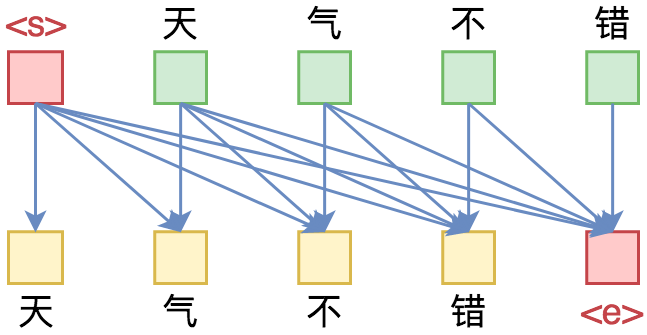
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
16
Jan
从几何视角来理解模型参数的初始化策略
By 苏剑林 | 2020-01-16 | 74315位读者 | 引用对于复杂模型来说,参数的初始化显得尤为重要。糟糕的初始化,很多时候已经不单是模型效果变差的问题了,还更有可能是模型根本训练不动或者不收敛。在深度学习中常见的自适应初始化策略是Xavier初始化,它是从正态分布$\mathcal{N}\left(0,\frac{2}{fan_{in} + fan_{out}}\right)$中随机采样而构成的初始权重,其中$fan_{in}$是输入的维度而$fan_{out}$是输出的维度。其他初始化策略基本上也类似,只不过假设有所不同,导致最终形式略有差别。
标准的初始化策略的推导是基于概率统计的,大概的思路是假设输入数据的均值为0、方差为1,然后期望输出数据也保持均值为0、方差为1,然后推导出初始变换应该满足的均值和方差条件。这个过程理论上没啥问题,但在笔者看来依然不够直观,而且推导过程的假设有点多。本文则希望能从几何视角来理解模型的初始化方法,给出一个更直观的推导过程。
信手拈来的正交
前者时间笔者写了《n维空间下两个随机向量的夹角分布》,其中的一个推论是
推论1: 高维空间中的任意两个随机向量几乎都是垂直的。
29
Jan

最近评论