






7
Jun
端午&高考乱弹:怀念的,也许只是怀念本身
By 苏剑林 | 2019-06-07 | 55092位读者 | 引用
24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 357321位读者 | 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。
30
Jul
Keras实现两个优化器:Lookahead和LazyOptimizer
By 苏剑林 | 2019-07-30 | 49533位读者 | 引用最近用Keras实现了两个优化器,也算是有点实现技巧,遂放在一起写篇文章简介一下(如果只有一个的话我就不写了)。这两个优化器的名字都挺有意思的,一个是look ahead(往前看?),一个是lazy(偷懒?),难道是两个完全不同的优化思路么?非也非也~只能说发明者们起名字太有创意了。
Lookahead
首先登场的是Lookahead优化器,它源于论文《Lookahead Optimizer: k steps forward, 1 step back》,是最近才提出来的优化器,有意思的是大牛Hinton和Adam的作者之一Jimmy Ba也出现在了论文作者列表当中,有这两个大神加持,这个优化器的出现便吸引了不少目光。
9
Aug
seq2seq之双向解码
By 苏剑林 | 2019-08-09 | 49091位读者 | 引用在文章《玩转Keras之seq2seq自动生成标题》中我们已经基本探讨过seq2seq,并且给出了参考的Keras实现。
本文则将这个seq2seq再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自《Synchronous Bidirectional Neural Machine Translation》,最后笔者也是用Keras实现的。
背景介绍
研究过seq2seq的读者都知道,常见的seq2seq的解码过程是从左往右逐字(词)生成的,即根据encoder的结果先生成第一个字;然后根据encoder的结果以及已经生成的第一个字,来去生成第二个字;再根据encoder的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解
\begin{equation}p(Y|X)=p(y_1|X)p(y_2|X,y_1)p(y_3|X,y_1,y_2)\cdots\label{eq:p}\end{equation}
31
Oct
从去噪自编码器到生成模型
By 苏剑林 | 2019-10-31 | 119174位读者 | 引用在我看来,几大顶会之中,ICLR的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是《Learning Generative Models using Denoising Density Estimators》和《Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces》。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。

fashion mnist、CelebA、cifar10上的生成效果
10
Jun
无监督分词和句法分析!原来BERT还可以这样用
By 苏剑林 | 2020-06-10 | 91666位读者 | 引用BERT的一般用法就是加载其预训练权重,再接一小部分新层,然后在下游任务上进行finetune,换句话说一般的用法都是有监督训练的。基于这个流程,我们可以做中文的分词、NER甚至句法分析,这些想必大家就算没做过也会有所听闻。但如果说直接从预训练的BERT(不finetune)就可以对句子进行分词,甚至析出其句法结构出来,那应该会让人感觉到意外和有趣了。
本文介绍ACL 2020的论文《Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT》,里边提供了直接利用Masked Language Model(MLM)来分析和解释BERT的思路,而利用这种思路,我们可以无监督地做到分词甚至句法分析。
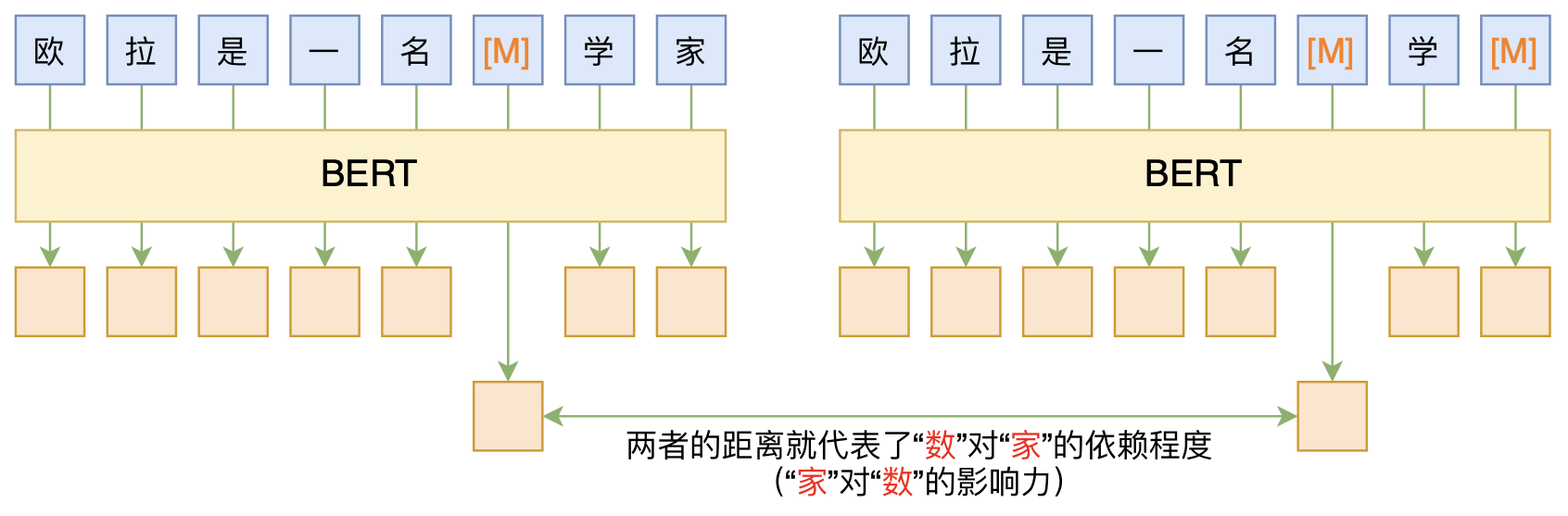
基于BERT的“token-token”相关度计算图示
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 100573位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
19
Jul
通过互信息思想来缓解类别不平衡问题
By 苏剑林 | 2020-07-19 | 177507位读者 | 引用类别不平衡问题,也叫“长尾问题”,是机器学习面临的常见问题之一,尤其是来源于真实场景下的数据集,几乎都是类别不平衡的。大概在两年前,笔者也思考过这个问题,当时正好对“互信息”相关的内容颇有心得,所以构思了一种基于互信息思想的解决办法,但又想了一下,那思路似乎过于平凡,所以就没有深究。然而,前几天在arxiv上刷到Google的一篇文章《Long-tail learning via logit adjustment》,意外地发现里边包含了跟笔者当初的构思几乎一样的方法,这才意识到当初放弃的思路原来还能达到SOTA的水平~于是结合这篇论文,将笔者当初的构思过程整理于此,希望不会被读者嫌弃“马后炮”。
问题描述
这里主要关心的是单标签的多分类问题,假设有$1,2,\cdots,K$共$K$个候选类别,训练数据为$(x,y)\sim\mathcal{D}$,建模的分布为$p_{\theta}(y|x)$,那么我们的优化目标是最大似然,或者说最小化交叉熵,即
\begin{equation}\mathop{\text{argmin}}_{\theta}\,\mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p_{\theta}(y|x)]\end{equation}

最近评论