






31
Jan
幂等生成网络IGN:试图将判别和生成合二为一的GAN
By 苏剑林 | 2024-01-31 | 49729位读者 | 引用前段时间,一个名为“幂等生成网络(Idempotent Generative Network,IGN)”的生成模型引起了一定的关注。它自称是一种独立于已有的VAE、GAN、flow、Diffusion之外的新型生成模型,并且具有单步采样的特点。也许是大家苦于当前主流的扩散模型的多步采样生成过程久矣,因此任何声称可以实现单步采样的“风吹草动”都很容易吸引人们的关注。此外,IGN名称中的“幂等”一词也增加了它的神秘感,进一步扩大了人们的期待,也成功引起了笔者的兴趣,只不过之前一直有别的事情要忙,所以没来得及认真阅读模型细节。
最近闲了一点,想起来还有个IGN没读,于是重新把论文翻了出来,但阅读之后却颇感困惑:这哪里是个新模型,不就是个GAN的变种吗?跟常规GAN不同的是,它将生成器和判别器合二为一了。那这个“合二为一”是不是有什么特别的好处,比如训练更稳定?个人又感觉没有。下面将分享笔者从GAN角度理解IGN的过程和疑问。
生成对抗
关于GAN(Generative Adversarial Network,生成对抗网络),笔者前几年系统地学习过一段时间(查看GAN标签可以查看到相关文章),但近几年没有持续地关注了,因此这里先对GAN做个简单的回顾,也方便后续章节中我们对比GAN与IGN之间的异同。
7
May
Cool Papers更新:简单搭建了一个站内检索系统
By 苏剑林 | 2024-05-07 | 49605位读者 | 引用自从《更便捷的Cool Papers打开方式:Chrome重定向扩展》之后,Cool Papers有两次比较大的变化,一次是引入了venue分支,逐步收录了一些会议历年的论文集,如ICLR、ICML等,这部分是动态人工扩充的,欢迎有心仪的会议的读者提更多需求;另一次就是本文的主题,前天新增加的站内检索功能。
本文将简单介绍一下新增功能,并对搭建站内检索系统的过程做个基本总结。
简介
在Cool Papers的首页,我们看到搜索入口:

Cool Papers(2024.05.07)
12
Aug
“Cool Papers + 站内搜索”的一些新尝试
By 苏剑林 | 2024-08-12 | 17937位读者 | 引用在《Cool Papers更新:简单搭建了一个站内检索系统》这篇文章中,我们介绍了Cool Papers新增的站内搜索系统。搜索系统的目的,自然希望能够帮助用户快速找到他们需要的论文。然而,如何高效地检索到对自己有价值的结果,并不是一件简单的事情,这里边往往需要一些技巧,比如精准提炼关键词。
这时候算法的价值就体现出来了,有些步骤人工来做会比较繁琐,但用算法来却很简单。所以接下来,我们将介绍几点通过算法来提高Cool Papers的搜索和筛选论文效率的新尝试。
相关论文
站内搜索背后的技术是全文检索引擎(Full-text Search Engine),简单来说,这就是一个基于关键词匹配的搜索算法,其相似度指标是BM25。
6
Sep
“闭门造车”之多模态思路浅谈(三):位置编码
By 苏剑林 | 2024-09-06 | 58451位读者 | 引用在前面的文章中,我们曾表达过这样的观点:多模态LLM相比纯文本LLM的主要差异在于,前者甚至还没有形成一个公认为标准的方法论。这里的方法论,不仅包括之前讨论的生成和训练策略,还包括一些基础架构的设计,比如本文要谈的“多模态位置编码”。
对于这个主题,我们之前在《Transformer升级之路:17、多模态位置编码的简单思考》就已经讨论过一遍,并且提出了一个方案(RoPE-Tie)。然而,当时笔者对这个问题的思考仅处于起步阶段,存在细节考虑不周全、认识不够到位等问题,所以站在现在的角度回看,当时所提的方案与完美答案还有明显的距离。
因此,本文我们将自上而下地再次梳理这个问题,并且给出一个自认为更加理想的结果。
多模位置
多模态模型居然连位置编码都没有形成共识,这一点可能会让很多读者意外,但事实上确实如此。对于文本LLM,目前主流的位置编码是RoPE(RoPE就不展开介绍了,假设读者已经熟知),更准确来说是RoPE-1D,因为原始设计只适用于1D序列。后来我们推导了RoPE-2D,这可以用于图像等2D序列,按照RoPE-2D的思路我们可以平行地推广到RoPE-3D,用于视频等3D序列。
26
Sep
利用“熄火保护 + 通断器”实现燃气灶智能关火
By 苏剑林 | 2024-09-26 | 18563位读者 | 引用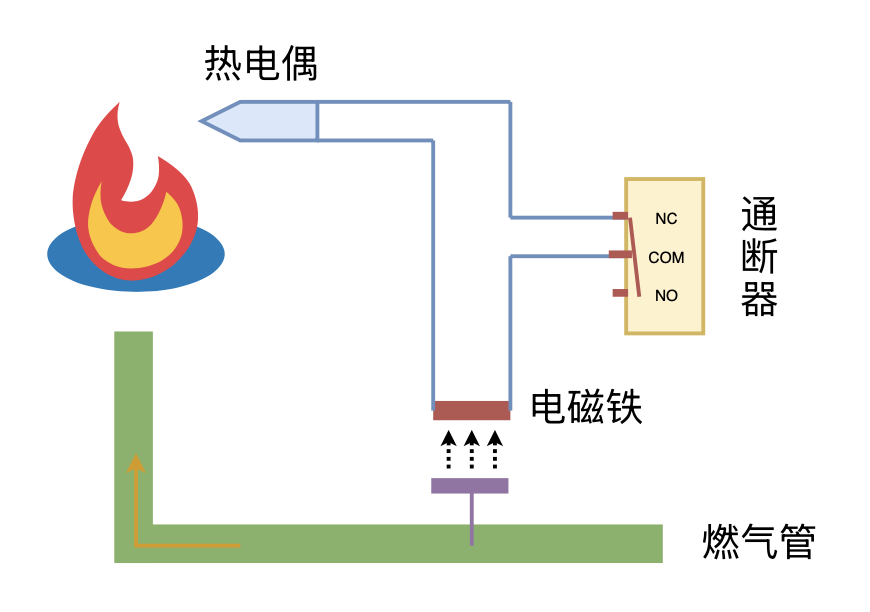
17
Jan
细水长flow之TARFLOW:流模型满血归来?
By 苏剑林 | 2025-01-17 | 19511位读者 | 引用不知道还有没有读者对这个系列有印象?这个系列取名“细水长flow”,主要介绍flow模型的相关工作,起因是当年(2018年)OpenAI发布了一个新的流模型Glow,在以GAN为主流的当时来说着实让人惊艳了一番。但惊艳归惊艳,事实上在相当长的时间内,Glow及后期的一些改进在生成效果方面都是比不上GAN的,更不用说现在主流的扩散模型了。
不过局面可能要改变了,上个月的论文《Normalizing Flows are Capable Generative Models》提出了新的流模型TARFLOW,它在几乎在所有的生成任务效果上都逼近了当前SOTA,可谓是流模型的“满血”回归。

TARFLOW的生成效果
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 29854位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
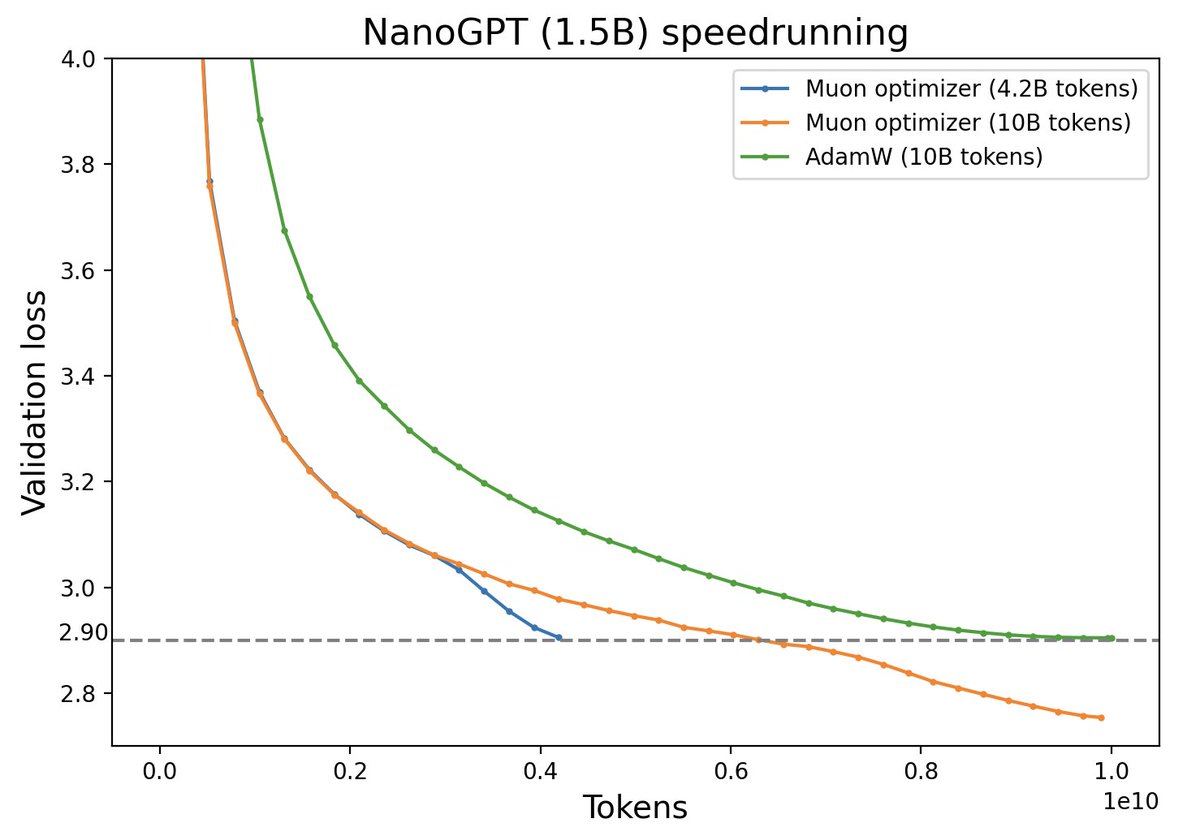
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)
27
Feb
Muon续集:为什么我们选择尝试Muon?
By 苏剑林 | 2025-02-27 | 7251位读者 | 引用本文解读一下我们最新的技术报告《Muon is Scalable for LLM Training》,里边分享了我们之前在《Muon优化器赏析:从向量到矩阵的本质跨越》介绍过的Muon优化器的一次较大规模的实践,并开源了相应的模型(我们称之为“Moonlight”,目前是一个3B/16B的MoE模型)。我们发现了一个比较惊人的结论:在我们的实验设置下,Muon相比Adam能够达到将近2倍的训练效率。

Muon的Scaling Law及Moonlight的MMLU表现
优化器的工作说多不多,但说少也不少,为什么我们会选择Muon来作为新的尝试方向呢?已经调好超参的Adam优化器,怎么快速切换到Muon上进行尝试呢?模型Scale上去之后,Muon与Adam的性能效果差异如何?接下来将分享我们的思考过程。

最近评论