






12
Aug
“Cool Papers + 站内搜索”的一些新尝试
By 苏剑林 | 2024-08-12 | 29469位读者 |在《Cool Papers更新:简单搭建了一个站内检索系统》这篇文章中,我们介绍了Cool Papers新增的站内搜索系统。搜索系统的目的,自然希望能够帮助用户快速找到他们需要的论文。然而,如何高效地检索到对自己有价值的结果,并不是一件简单的事情,这里边往往需要一些技巧,比如精准提炼关键词。
这时候算法的价值就体现出来了,有些步骤人工来做会比较繁琐,但用算法来却很简单。所以接下来,我们将介绍几点通过算法来提高Cool Papers的搜索和筛选论文效率的新尝试。
相关论文 #
站内搜索背后的技术是全文检索引擎(Full-text Search Engine),简单来说,这就是一个基于关键词匹配的搜索算法,其相似度指标是BM25。
既然核心是关键词,那么我们可以在关键词方面下点功夫。于是,我们根据论文的标题和摘要抽取了每篇论文的10个关键词,作为这篇论文的一个压缩表征。这些关键词的第一个用途,就是传入到站内搜索中,用来搜索该论文的相关论文,这就是每篇论文新增的“[REL]”按钮的原理。
![新增的[REL]按钮](/usr/uploads/2024/08/4271789345.jpeg)
新增的[REL]按钮
简单的测试表明,该思路确实能召回一定的相关文献的,不过由于目前抽取关键词的算法只是TF-IDF,所以效果并不是很完美。先就这样凑合用着吧,权当是给后面留下优化空间了。
历史词云 #
论文关键的第二个用途,是将用户点击过的所有论文关键词都聚合起来,形成一个词云,可以作为用户论文偏好的一个描述。如果读者近来有用Cool Papers刷论文,那么这个词云应该已经小有规模了,因为词云的统计在前段时间已经悄悄上线了,现在可以在首页点击下方的“More”看到(Track一栏):

笔者的阅读词云
除了用户偏好描述外,词云统计未来可能还有可能用于相关论文推荐等定制化服务,这些就取决于后续的开发了,敬请大家期待,也欢迎大家多提建议。
偏好排序 #
之前我们已经多次强调过,Cool Papers主要聚焦于“刷论文”,但每天新增的论文数对某些读者来说还是有点多的,他们并没有时间精力将整个列表过一遍。所以之前我们提供了按星标数排序的一个选择,读者可以只选择星标数比较多也就是相对来说比较热门的论文来阅读。
然而,星标数只能代表全体读者的一个整体偏好,它并不一定符合读者的个人偏好。所以,这次我们增加了个人偏好排序。同样在首页点击“More”按钮我们就可以看到“Prefer”栏目,在里边我们可以设置自己要关注的关键词。当然留空也可以,留空的话网站会默认从历史词云中选前20个关键词作为偏好。
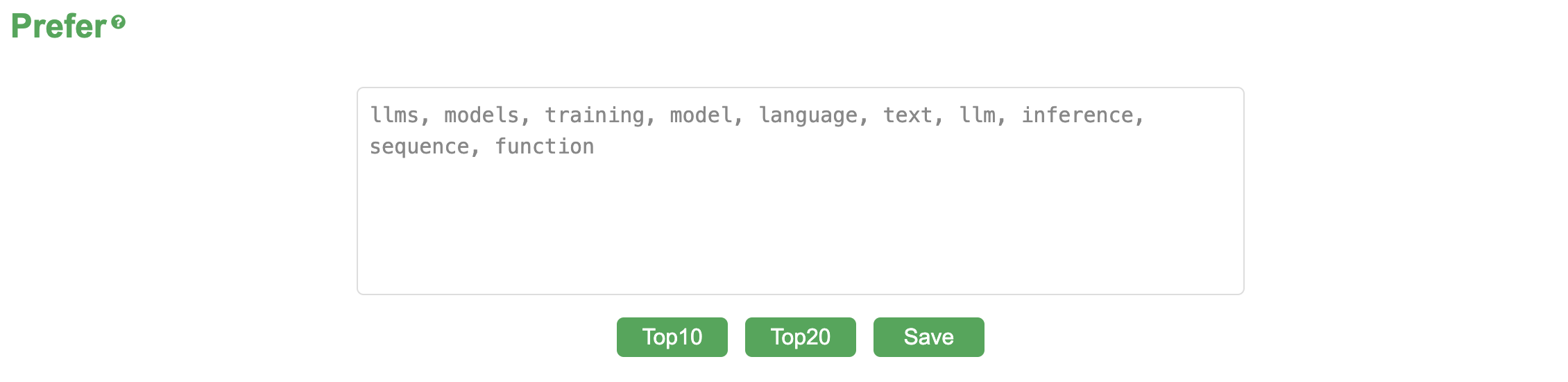
可以设置偏好关键词
设置偏好关键词后,在列表页头部,我们可以看到现在多了“★”和“❤”两个符号,它们分别代表了“按星标数排序”以及“按用户偏好”排序,点击即可触发排序:

两种排序方式
这个排序的原理,还是基于站内搜索实现的,将用户偏好关键词作为query,并限定搜索范围,然后返回搜索排序结果。
文章小结 #
本文介绍了Cool Papers新引入的若干特性,包括相关论文搜索、词云统计、用户偏好排序等,希望能提高大家刷论文的效率。特别要声明的是,以上用户偏好等数据,都是储存在用户的浏览器本地,Cool Papers并没有收集这些数据。
转载到请包括本文地址:https://kexue.fm/archives/10311
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Aug. 12, 2024). 《“Cool Papers + 站内搜索”的一些新尝试 》[Blog post]. Retrieved from https://kexue.fm/archives/10311
@online{kexuefm-10311,
title={“Cool Papers + 站内搜索”的一些新尝试},
author={苏剑林},
year={2024},
month={Aug},
url={\url{https://kexue.fm/archives/10311}},
}

August 22nd, 2024
赞
August 26th, 2024
关于REL的论文,可以理解为TF-IDF召回,然后BM25算法排序吗?
论文的发表时间有没有参与到这个相关性里呢?
没有时间,纯粹是关键词查找