






8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 80640位读者 | 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花$n$倍的时间,可以达到$n$倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 333061位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
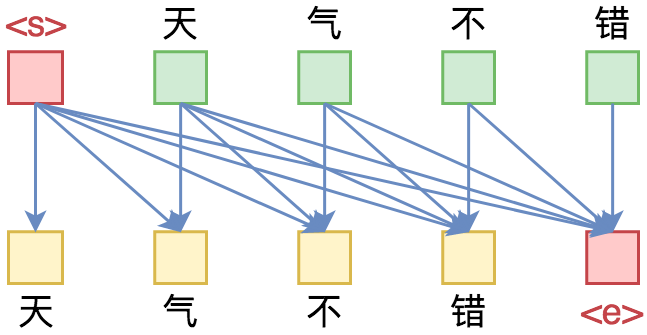
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
23
Mar
AdaFactor优化器浅析(附开源实现)
By 苏剑林 | 2020-03-23 | 85707位读者 | 引用自从GPT、BERT等预训练模型流行起来后,其中一个明显的趋势是模型越做越大,因为更大的模型配合更充分的预训练通常能更有效地刷榜。不过,理想可以无限远,现实通常很局促,有时候模型太大了,大到哪怕你拥有了大显存的GPU甚至TPU,依然会感到很绝望。比如GPT2最大的版本有15亿参数,最大版本的T5模型参数量甚至去到了110亿,这等规模的模型,哪怕在TPU集群上也没法跑到多大的batch size。
这时候通常要往优化过程着手,比如使用混合精度训练(tensorflow下还可以使用一种叫做bfloat16的新型浮点格式),即省显存又加速训练;又或者使用更省显存的优化器,比如RMSProp就比Adam更省显存。本文则介绍AdaFactor,一个由Google提出来的新型优化器,首发论文为《Adafactor: Adaptive Learning Rates with Sublinear Memory Cost》。AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。
Adam
首先我们来回顾一下常用的Adam优化器的更新过程。设$t$为迭代步数,$\alpha_t$为当前学习率,$L(\theta)$是损失函数,$\theta$是待优化参数,$\epsilon$则是防止溢出的小正数,那么Adam的更新过程为
26
Mar
GELU的两个初等函数近似是怎么来的
By 苏剑林 | 2020-03-26 | 52414位读者 | 引用GELU,全称为Gaussian Error Linear Unit,也算是RELU的变种,是一个非初等函数形式的激活函数。它由论文《Gaussian Error Linear Units (GELUs)》提出,后来被用到了GPT中,再后来被用在了BERT中,再再后来的不少预训练语言模型也跟着用到了它。随着BERT等预训练语言模型的兴起,GELU也跟着水涨船高,莫名其妙地就成了热门的激活函数了。
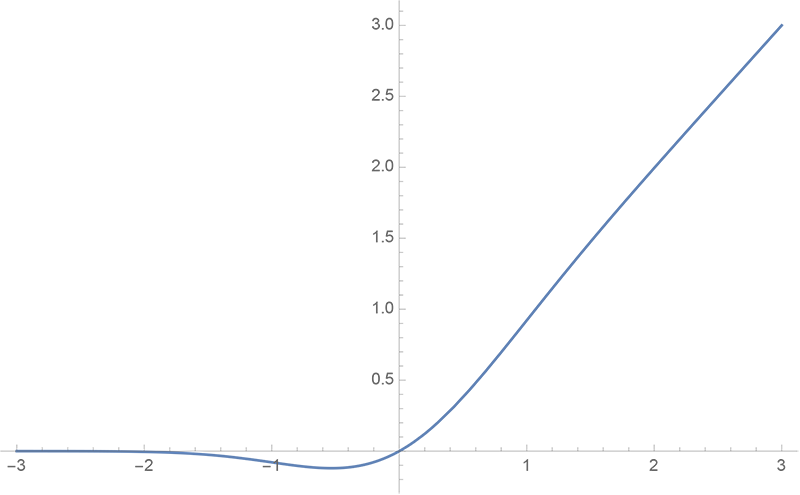
gelu函数图像
在GELU的原始论文中,作者不仅提出了GELU的精确形式,还给出了两个初等函数的近似形式,本文来讨论它们是怎么得到的。
16
Jun
如何应对Seq2Seq中的“根本停不下来”问题?
By 苏剑林 | 2020-06-16 | 64912位读者 | 引用在Seq2Seq的解码过程中,我们是逐个token地递归生成的,直到出现<eos>标记为止,这就是所谓的“自回归”生成模型。然而,研究过Seq2Seq的读者应该都能发现,这种自回归的解码偶尔会出现“根本停不下来”的现象,主要是某个片段反复出现,比如“今天天气不错不错不错不错不错...”、“你觉得我说得对不对不对不对不对不对...”等等,但就是死活不出现<eos>标记。ICML 2020的文章《Consistency of a Recurrent Language Model With Respect to Incomplete Decoding》比较系统地讨论了这个现象,并提出了一些对策,本文来简单介绍一下论文的主要内容。
解码算法
对于自回归模型来说,我们建立的是如下的条件语言模型
\begin{equation}p(y_t|y_{\lt t}, x)\label{eq:p}\end{equation}
那么解码算法就是在已知上述模型时,给定$x$来输出对应的$y=(y_1,y_2,\dots,y_T)$来。解码算法大致可以分为两类:确定性解码算法和随机性解码算法,原论文分别针对这两类解码讨论来讨论了“根本停不下来”问题,所以我们需要来了解一下这两类解码算法。
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 55022位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
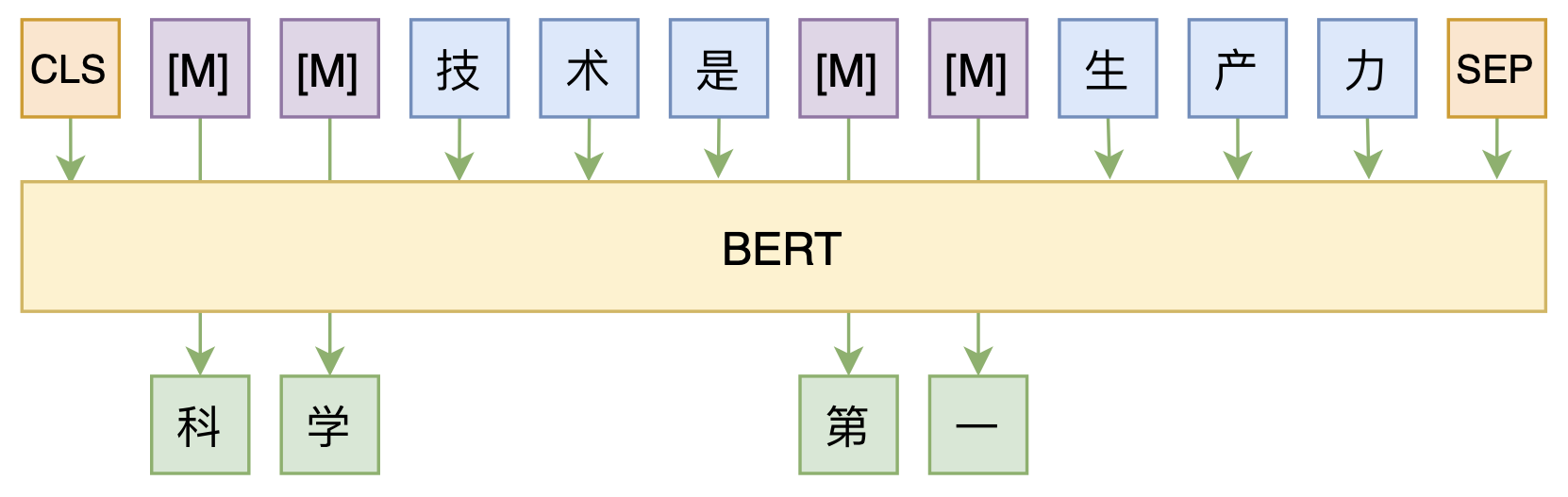
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
29
Oct
用ALBERT和ELECTRA之前,请确认你真的了解它们
By 苏剑林 | 2020-10-29 | 71739位读者 | 引用在预训练语言模型中,ALBERT和ELECTRA算是继BERT之后的两个“后起之秀”。它们从不同的角度入手对BERT进行了改进,最终提升了效果(至少在不少公开评测数据集上是这样),因此也赢得了一定的口碑。但在平时的交流学习中,笔者发现不少朋友对这两个模型存在一些误解,以至于在使用过程中浪费了不必要的时间。在此,笔者试图对这两个模型的一些关键之处做下总结,供大家参考,希望大家能在使用这两个模型的时候少走一些弯路。

ALBERT与ELECTRA
(注:本文中的“BERT”一词既指开始发布的BERT模型,也指后来的改进版RoBERTa,我们可以将BERT理解为没充分训练的RoBERTa,将RoBERTa理解为更充分训练的BERT。本文主要指的是它跟ALBERT和ELECTRA的对比,因此不区分BERT和RoBERTa。)
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 131838位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。
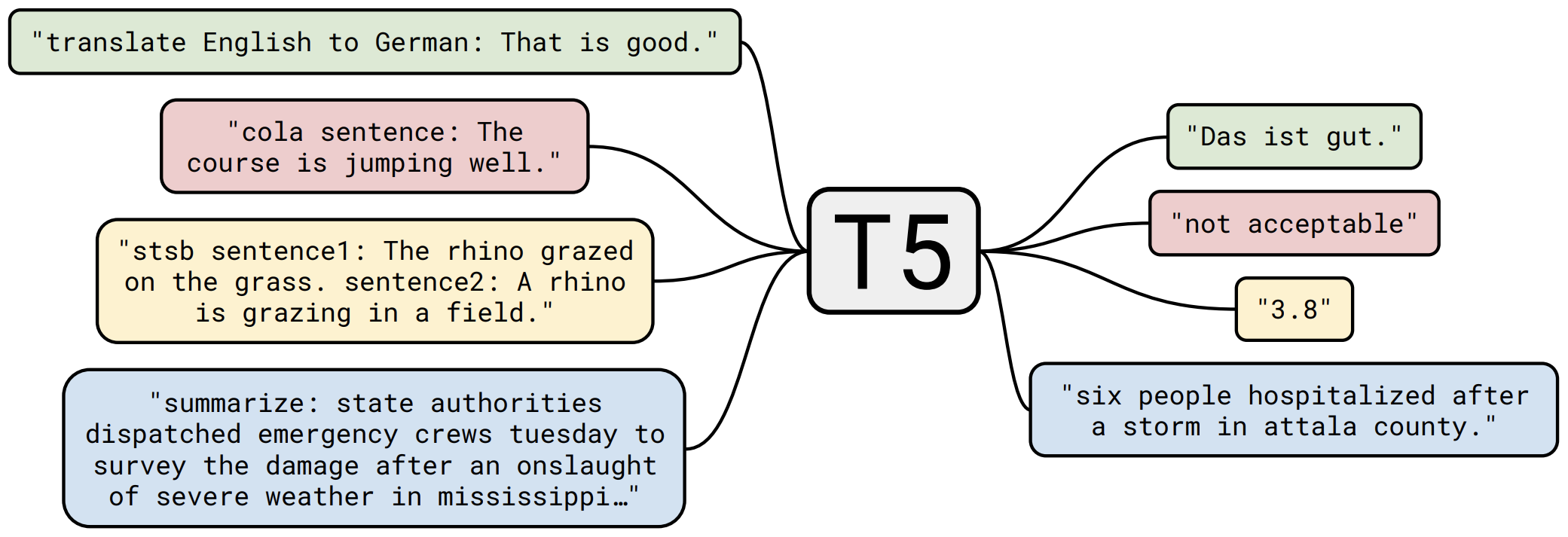
“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。

最近评论