






31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 67423位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
9
Aug
线性Transformer应该不是你要等的那个模型
By 苏剑林 | 2021-08-09 | 91851位读者 | 引用在本博客中,我们已经多次讨论过线性Attention的相关内容。介绍线性Attention的逻辑大体上都是:标准Attention具有$\mathcal{O}(n^2)$的平方复杂度,是其主要的“硬伤”之一,于是我们$\mathcal{O}(n)$复杂度的改进模型,也就是线性Attention。有些读者看到线性Attention的介绍后,就一直很期待我们发布基于线性Attention的预训练模型,以缓解他们被BERT的算力消耗所折腾的“死去活来”之苦。
然而,本文要说的是:抱有这种念头的读者可能要失望了,标准Attention到线性Attention的转换应该远远达不到你的预期,而BERT那么慢的原因也并不是因为标准Attention的平方复杂度。
BERT之反思
按照直观理解,平方复杂度换成线性复杂度不应该要“突飞猛进”才对嘛?怎么反而“远远达不到预期”?出现这个疑惑的主要原因,是我们一直以来都没有仔细评估一下常规的Transformer模型(如BERT)的整体计算量。
22
Oct
CAN:借助先验分布提升分类性能的简单后处理技巧
By 苏剑林 | 2021-10-22 | 103165位读者 | 引用顾名思义,本文将会介绍一种用于分类问题的后处理技巧——CAN(Classification with Alternating Normalization),出自论文《When in Doubt: Improving Classification Performance with Alternating Normalization》。经过笔者的实测,CAN确实多数情况下能提升多分类问题的效果,而且几乎没有增加预测成本,因为它仅仅是对预测结果的简单重新归一化操作。
有趣的是,其实CAN的思想是非常朴素的,朴素到每个人在生活中都应该用过同样的思想。然而,CAN的论文却没有很好地说清楚这个思想,只是纯粹形式化地介绍和实验这个方法。本文的分享中,将会尽量将算法思想介绍清楚。
思想例子
假设有一个二分类问题,模型对于输入$a$给出的预测结果是$p^{(a)} = [0.05, 0.95]$,那么我们就可以给出预测类别为$1$;接下来,对于输入$b$,模型给出的预测结果是$p^{(b)}=[0.5,0.5]$,这时候处于最不确定的状态,我们也不知道输出哪个类别好。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 161265位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
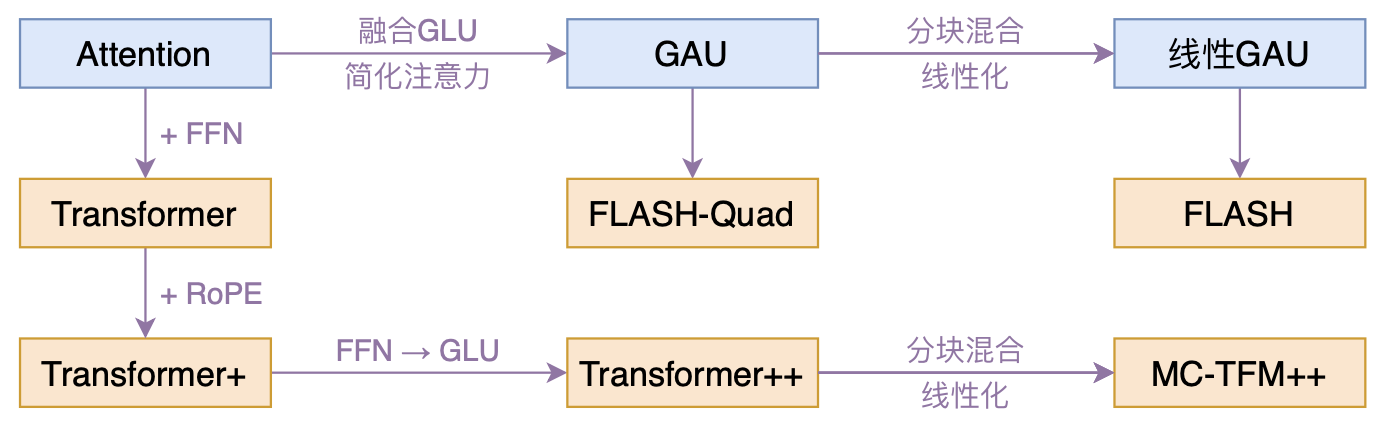
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 52445位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
22
Apr
GAU-α:尝鲜体验快好省的下一代Attention
By 苏剑林 | 2022-04-22 | 41652位读者 | 引用在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了GAU(Gated Attention Unit,门控线性单元),在这里笔者愿意称之为“目前最有潜力的下一代Attention设计”,因为它真正达到了“更快(速度)、更好(效果)、更省(显存)”的特点。
然而,有些读者在自己的测试中得到了相反的结果,比如收敛更慢、效果更差等,这与笔者的测试结果大相径庭。本文就来分享一下笔者自己的训练经验,并且放出一个尝鲜版“GAU-α”供大家测试。
GAU-α
首先介绍一下开源出来的“GAU-α”在CLUE任务上的成绩单:
$$\tiny{\begin{array}{c|ccccccccccc}
\hline
& \text{iflytek} & \text{tnews} & \text{afqmc} & \text{cmnli} & \text{ocnli} & \text{wsc} & \text{csl} & \text{cmrc2018} & \text{c3} & \text{chid} & \text{cluener}\\
\hline
\text{BERT} & 60.06 & 56.80 & 72.41 & 79.56 & 73.93 & 78.62 & 83.93 & 56.17 & 60.54 & 85.69 & 79.45 \\
\text{RoBERTa} & 60.64 & \textbf{58.06} & 74.05 & 81.24 & 76.00 & \textbf{87.50} & 84.50 & 56.54 & 67.66 & 86.71 & 79.47\\
\text{RoFormer} & 60.91 & 57.54 & 73.52 & 80.92 & \textbf{76.07} & 86.84 & 84.63 & 56.26 & 67.24 & 86.57 & 79.72\\
\text{RoFormerV2}^* & 60.87 & 56.54 & 72.75 & 80.34 & 75.36 & 80.92 & 84.67 & 57.91 & 64.62 & 85.09 & \textbf{81.08}\\
\hline
\text{GAU-}\alpha & \textbf{61.41} & 57.76 & \textbf{74.17} & \textbf{81.82} & 75.86 & 79.93 & \textbf{85.67} & \textbf{58.09} & \textbf{68.24} & \textbf{87.91} & 80.01\\
\hline
\end{array}}$$
18
May
当BERT-whitening引入超参数:总有一款适合你
By 苏剑林 | 2022-05-18 | 33443位读者 | 引用在《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者提出了BERT-whitening,验证了一个线性变换就能媲美当时的SOTA方法BERT-flow。此外,BERT-whitening还可以对句向量进行降维,带来更低的内存占用和更快的检索速度。然而,在《无监督语义相似度哪家强?我们做了个比较全面的评测》中我们也发现,whitening操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的SimBERT),那么额外的whitening操作往往会降低效果。
为了弥补这个不足,本文提出往BERT-whitening中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得“降维不掉点”的结果。换句话说,即便是原来加上whitening后效果会下降的任务,如今也有机会在降维的同时获得相近甚至更好的效果了。
方法概要
目前BERT-whitening的流程是:
\begin{equation}\begin{aligned}
\tilde{\boldsymbol{x}}_i =&\, (\boldsymbol{x}_i - \boldsymbol{\mu})\boldsymbol{U}\boldsymbol{\Lambda}^{-1/2} \\
\boldsymbol{\mu} =&\, \frac{1}{N}\sum\limits_{i=1}^N \boldsymbol{x}_i \\
\boldsymbol{\Sigma} =&\, \frac{1}{N}\sum\limits_{i=1}^N (\boldsymbol{x}_i - \boldsymbol{\mu})^{\top}(\boldsymbol{x}_i - \boldsymbol{\mu}) = \boldsymbol{U}\boldsymbol{\Lambda}\boldsymbol{U}^{\top} \,\,(\text{SVD分解})
\end{aligned}\end{equation}
17
Apr
梯度视角下的LoRA:简介、分析、猜测及推广
By 苏剑林 | 2023-04-17 | 61714位读者 | 引用随着ChatGPT及其平替的火热,各种参数高效(Parameter-Efficient)的微调方法也“水涨船高”,其中最流行的方案之一就是本文的主角LoRA了,它出自论文《LoRA: Low-Rank Adaptation of Large Language Models》。LoRA方法上比较简单直接,而且也有不少现成实现,不管是理解还是使用都很容易上手,所以本身也没太多值得细写的地方了。
然而,直接实现LoRA需要修改网络结构,这略微麻烦了些,同时LoRA给笔者的感觉是很像之前的优化器AdaFactor,所以笔者的问题是:能否从优化器角度来分析和实现LoRA呢?本文就围绕此主题展开讨论。
方法简介
以往的一些结果(比如《Exploring Aniversal Intrinsic Task Subspace via Prompt Tuning》)显示,尽管预训练模型的参数量很大,但每个下游任务对应的本征维度(Intrinsic Dimension)并不大,换句话说,理论上我们可以微调非常小的参数量,就能在下游任务取得不错的效果。
LoRA借鉴了上述结果,提出对于预训练的参数矩阵$W_0\in\mathbb{R}^{n\times m}$,我们不去直接微调$W_0$,而是对增量做低秩分解假设:
\begin{equation}W = W_0 + A B,\qquad A\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m}\end{equation}

最近评论