






21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 91704位读者 |大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
极限探索 #
在预训练模型兴起之后,不少研究人员都对一个问题相当感兴趣:预训练模型的极限在哪里?当然,“极限”这个词含义很丰富,以GPT3为代表的一系列工作试图探索的是参数量、数据量的极限,而微软近来提出的DeepNet则探究的是深度的极限。对于我们来说,我们更想知道同一参数量下的性能极限,试图最充分地“压榨”预训练模型的性能,RoFormerV2正是这一理念的产物。
简单来说,RoFormerV2先在RoFormer的基础上对模型结构做了适当的简化,从而获得了一定的速度提升。训练方面,除了进行常规的无监督MLM预训练外,我们还收集了20多G的标注数据,进行了有监督的多任务预训练。在有监督式训练之下,模型效果获得了长足的提升,基本上实现了同一参数量下速度和效果的最优解。
特别地,3亿参数量的RoFormer large,在CLUE榜单上超过了若干10亿+参数量的模型,做到了第5名,它也是榜上前5名中参数量最少的模型:
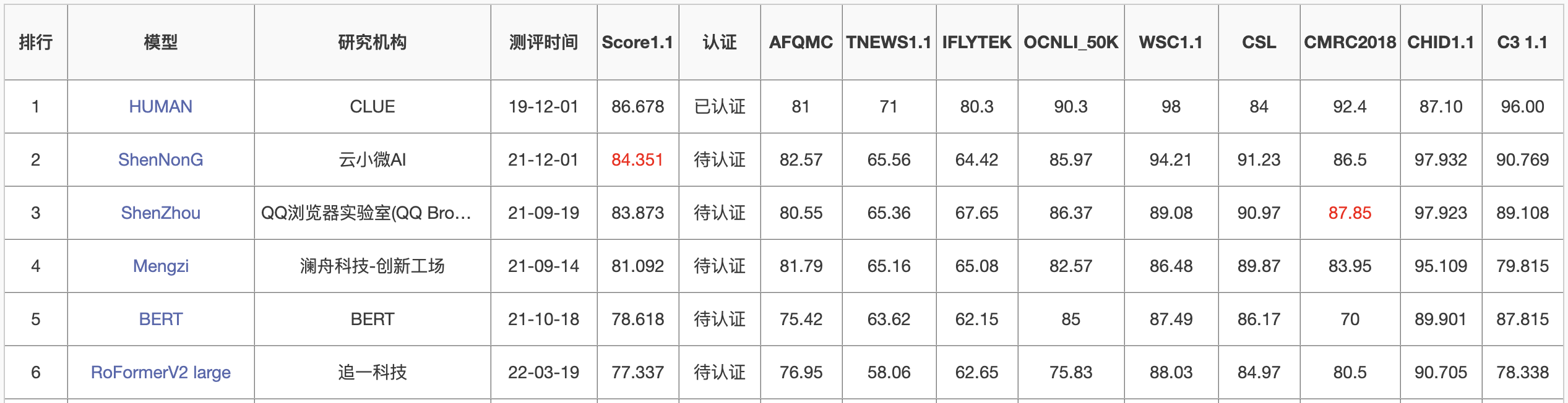
RoFormerV2 large在CLUE上的“成绩单”
模型介绍 #
相比RoFormer,RoFormerV2的主要改动是简化模型结构、增加训练数据以及加入有监督训练,这些改动能让RoFormerV2最终取得了速度和效果的“双赢”。
结构的简化 #
在结构上,RoFormerV2主要去掉了模型的所有Bias项,以及Layer Norm换成了简单的RMS Norm,并且去掉了RMS Norm的gamma参数。这些改动的灵感主要来自Google的T5模型。
大家的潜意识里可能会觉得Bias项以及Layer Norm的beta和gamma参数计算量都很小,至少对速度来说是无关痛痒的。但事实出乎我们的意料:去掉这些看似“无关痛痒”的参数外,RoFormerV2的训练速度获得了明显的提升!
一些参考数据如下(RoFormer和RoBERTa速度接近,就不列出来了,base版的测试显卡为3090,large版的测试显卡为A100):
\begin{array}{c|cc|cc}
\hline
& \text{序列长度} & \text{训练速度} & \text{序列长度} & \text{训练速度} \\
\hline
\text{RoBERTa base} & 128 & 1.0\text{x} & 512 & 1.0\text{x} \\
\text{RoFormerV2 base} & 128 & 1.3\text{x} & 512 & 1.2\text{x}\\
\hline
\text{RoBERTa large} & 128 & 1.0\text{x} & 512 & 1.0\text{x} \\
\text{RoFormerV2 large} & 128 & 1.3\text{x} & 512 & 1.2\text{x} \\
\hline
\end{array}
无监督训练 #
同RoFormer一样,RoFormerV2也是先通过MLM任务进行无监督预训练,不同的地方主要有两点:
1、RoFormer是在RoBERTa权重基础上进行训练,RoFormerV2是从零训练;
2、RoFormer的无监督训练只有30多G数据,RoFormerV2则用到了280G数据。
从零训练相比于在已有权重基础上继续训练会更加困难,主要体现在Post Norm结构更难收敛。为此,我们提出了一种新的训练技术:将残差设计为
\begin{equation}\boldsymbol{x}_{t+1} = \text{Norm}(\boldsymbol{x}_t + \alpha F(\boldsymbol{x}_t)) \end{equation}
其中$\alpha$初始化为0并线性地缓慢增加到1,相关讨论还可以参考《浅谈Transformer的初始化、参数化与标准化》。该方案跟ReZero相似,不同的是ReZero中$\alpha$是可训练参数且去掉$\text{Norm}$操作,而实验显示我们的改动相比ReZero的最终效果更好,几乎是DeepNet之前的最优解。
多任务训练 #
前面提到RoFormerV2的结构有所简化以获得速度的提升,但由于“没有免费的午餐”,同样的训练设置之下RoFormerV2相比RoBERTa、RoFormer的效果会有轻微下降。为了弥补回这部分下降的效果,更有效地挖掘模型潜力,我们补充了有监督式的多任务预训练。
具体来说,我们收集了77个共计20G的标注数据集,构建了92个任务进行多任务训练,这些数据集涵盖文本分类、文本匹配、阅读理解、信息抽取、指代消解等常见自然语言理解任务,以求模型能获得比较全面的自然语言理解能力。为了完成训练,我们在bert4keras基础上进一步开发了一个多任务训练框架,灵活支持不同格式的任务进行混合训练,并整合了梯度归一化等技术(参考《多任务学习漫谈(二):行梯度之事》)来确保每个任务都达到尽可能优的效果。
RoFormerV2并不是第一个尝试多任务预训练的模型,在它之前有MT-DNN、T5以及前段时间的ZeroPrompt都已经肯定过多任务预训练的价值,而我们主要是在中文上进行了充分的验证并首先进行了开源。
实验结果 #
我们主要在CLUE榜单上对比效果:
$$\small{\begin{array}{c|ccccccccccc}
\hline
& \text{iflytek} & \text{tnews} & \text{afqmc} & \text{cmnli} & \text{ocnli} & \text{wsc} & \text{csl} & \text{cmrc2018} & \text{c3} & \text{chid} & \text{cluener}\\
\hline
\text{BERT base} & 61.19 & 56.29 & 73.37 & 79.37 & 71.73 & 73.85 & 84.03 & 72.10 & 61.33 & 85.13 & 78.68\\
\hline
\text{RoBERTa base} & 61.12 & 58.35 & 73.61 & 80.81 & 74.27 & 82.28 & \textbf{85.33} & 75.40 & 67.11 & 86.04 & 79.38\\
\text{RoBERTa large} & 60.58 & 55.51 & 75.14 & \textbf{82.16} & 75.47 & 81.97 & 85.07 & 78.85 & 76.74 & \textbf{88.65} & \textbf{80.19}\\
\hline
\text{RoFormer base} & 61.08 & 56.74 & 73.82 & 80.97 & 73.10 & 80.57 & 84.93 & 73.50 & 66.29 & 86.30 & 79.69\\
\hline
\text{RoFormerV2 small} & 60.46 & 51.46 & 72.39 & 76.93 & 67.70 & 69.11 & 83.00 & 71.80 & 64.49 & 77.35 & 78.20\\
\text{RoFormerV2 base} & 62.50 & \textbf{58.74} & 75.63 & 80.62 & 74.23 & 82.71 & 84.17 & 77.00 & 75.57 & 85.95 & 79.87\\
\text{RoFormerV2 large} & \textbf{62.65} & 58.06 & \textbf{76.95} & 81.20 & \textbf{75.83} & \textbf{88.03} & 84.97 & \textbf{80.50} & \textbf{78.34} & 87.68 & \textbf{80.17}\\
\hline
\end{array}}$$
可以看到,多任务训练的提升是相当可观的,在大多数任务上RoFormerV2不仅“追回”了结构简化带来的效果差距,还有一定的提升,平均来说算得上达到了同级模型的最优效果。另外,CMNLI和CHID两个任务上,RoFormerV2都不如RoBERTa,这是因为这两个任务都训练数据都非常多(数十万级别),当训练数据量足够大时,模型的效果主要取决于模型的容量,多任务训练带来的提升比较小。
所以,总的来说就是:如果你的任务类型比较常规,数据量不是特别大,那么RoFormerV2往往是一个不错的选择;如果你希望加快一点训练速度,那么也可以选择RoFormerV2;但如果你的任务数据量特别大,那么RoFormerV2通常不会有优势。
本文小结 #
本文主要对我们新发布的RoFormerV2模型做了基本的介绍,它主要通过结构的简化来提升速度,并通过无监督预训练和有监督预训练的结合来提升效果,从而达到了速度与效果的“双赢”。
转载到请包括本文地址:https://kexue.fm/archives/8998
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 21, 2022). 《RoFormerV2:自然语言理解的极限探索 》[Blog post]. Retrieved from https://kexue.fm/archives/8998
@online{kexuefm-8998,
title={RoFormerV2:自然语言理解的极限探索},
author={苏剑林},
year={2022},
month={Mar},
url={\url{https://kexue.fm/archives/8998}},
}

September 28th, 2023
问下苏神RoFormerV2从零训练的速度和使用资源怎么样?花了多久时间训练一个epoch呢?
好像Large版用两张80G的A100大概训练了两个月吧,不大记得了,Base版好像是一个月左右,具体训练配置Github上有。
May 14th, 2024
问下苏神,我正在做一些大模型在中文语料上的训练工作,您这边方便提供一下文中提到的数据集吗
不能,这是我前公司的数据,我没有权限分享。
了解,感谢回复!
March 29th, 2025
roformerV2的苏神版本只支持keras2.3.1+tf1.15-tf2.2的组合,在现在看来太老旧了,不适合新朋友使用。
如果大家在2025后想继续使用roformerV2,建议使用keras3的新实现。你可以在keras_hub>0.20版本后使用(截至这条消息的2025.3.29这个版本还未发布,但是很快了,敬请期待)。
权重下载链接:
https://www.modelscope.cn/models/q935499957/roformerV2_small_zh-Keras
https://www.modelscope.cn/models/q935499957/roformerV2_base_zh-Keras
https://www.modelscope.cn/models/q935499957/roformerV2_large_zh-Keras
感谢