






11
Aug
细水长flow之NICE:流模型的基本概念与实现
By 苏剑林 | 2018-08-11 | 268405位读者 | 引用前言:自从在机器之心上看到了glow模型之后(请看《下一个GAN?OpenAI提出可逆生成模型Glow》),我就一直对其念念不忘。现在机器学习模型层出不穷,我也经常关注一些新模型动态,但很少像glow模型那样让我怦然心动,有种“就是它了”的感觉。更意外的是,这个效果看起来如此好的模型,居然是我以前完全没有听说过的。于是我翻来覆去阅读了好几天,越读越觉得有意思,感觉通过它能将我之前的很多想法都关联起来。在此,先来个阶段总结。
背景
本文主要是《NICE: Non-linear Independent Components Estimation》一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。
艰难的分布
众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。

glow模型生成的高清人脸
29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 72113位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 94862位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
11
Oct
BN究竟起了什么作用?一个闭门造车的分析
By 苏剑林 | 2019-10-11 | 115137位读者 | 引用BN,也就是Batch Normalization,是当前深度学习模型(尤其是视觉相关模型)的一个相当重要的技巧,它能加速训练,甚至有一定的抗过拟合作用,还允许我们用更大的学习率,总的来说颇多好处(前提是你跑得起较大的batch size)。
那BN究竟是怎么起作用呢?早期的解释主要是基于概率分布的,大概意思是将每一层的输入分布都归一化到$\mathcal{N}(0,1)$上,减少了所谓的Internal Covariate Shift,从而稳定乃至加速了训练。这种解释看上去没什么毛病,但细思之下其实有问题的:不管哪一层的输入都不可能严格满足正态分布,从而单纯地将均值方差标准化无法实现标准分布$\mathcal{N}(0,1)$;其次,就算能做到$\mathcal{N}(0,1)$,这种诠释也无法进一步解释其他归一化手段(如Instance Normalization、Layer Normalization)起作用的原因。
在去年的论文《How Does Batch Normalization Help Optimization?》里边,作者明确地提出了上述质疑,否定了原来的一些观点,并提出了自己关于BN的新理解:他们认为BN主要作用是使得整个损失函数的landscape更为平滑,从而使得我们可以更平稳地进行训练。
本博文主要也是分享这篇论文的结论,但论述方法是笔者“闭门造车”地构思的。窃认为原论文的论述过于晦涩了,尤其是数学部分太不好理解,所以本文试图尽可能直观地表达同样观点。
(注:阅读本文之前,请确保你已经清楚知道BN是什么,本文不再重复介绍BN的概念和流程。)
23
Mar
AdaFactor优化器浅析(附开源实现)
By 苏剑林 | 2020-03-23 | 82939位读者 | 引用自从GPT、BERT等预训练模型流行起来后,其中一个明显的趋势是模型越做越大,因为更大的模型配合更充分的预训练通常能更有效地刷榜。不过,理想可以无限远,现实通常很局促,有时候模型太大了,大到哪怕你拥有了大显存的GPU甚至TPU,依然会感到很绝望。比如GPT2最大的版本有15亿参数,最大版本的T5模型参数量甚至去到了110亿,这等规模的模型,哪怕在TPU集群上也没法跑到多大的batch size。
这时候通常要往优化过程着手,比如使用混合精度训练(tensorflow下还可以使用一种叫做bfloat16的新型浮点格式),即省显存又加速训练;又或者使用更省显存的优化器,比如RMSProp就比Adam更省显存。本文则介绍AdaFactor,一个由Google提出来的新型优化器,首发论文为《Adafactor: Adaptive Learning Rates with Sublinear Memory Cost》。AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。
Adam
首先我们来回顾一下常用的Adam优化器的更新过程。设$t$为迭代步数,$\alpha_t$为当前学习率,$L(\theta)$是损失函数,$\theta$是待优化参数,$\epsilon$则是防止溢出的小正数,那么Adam的更新过程为
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 89847位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 65799位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
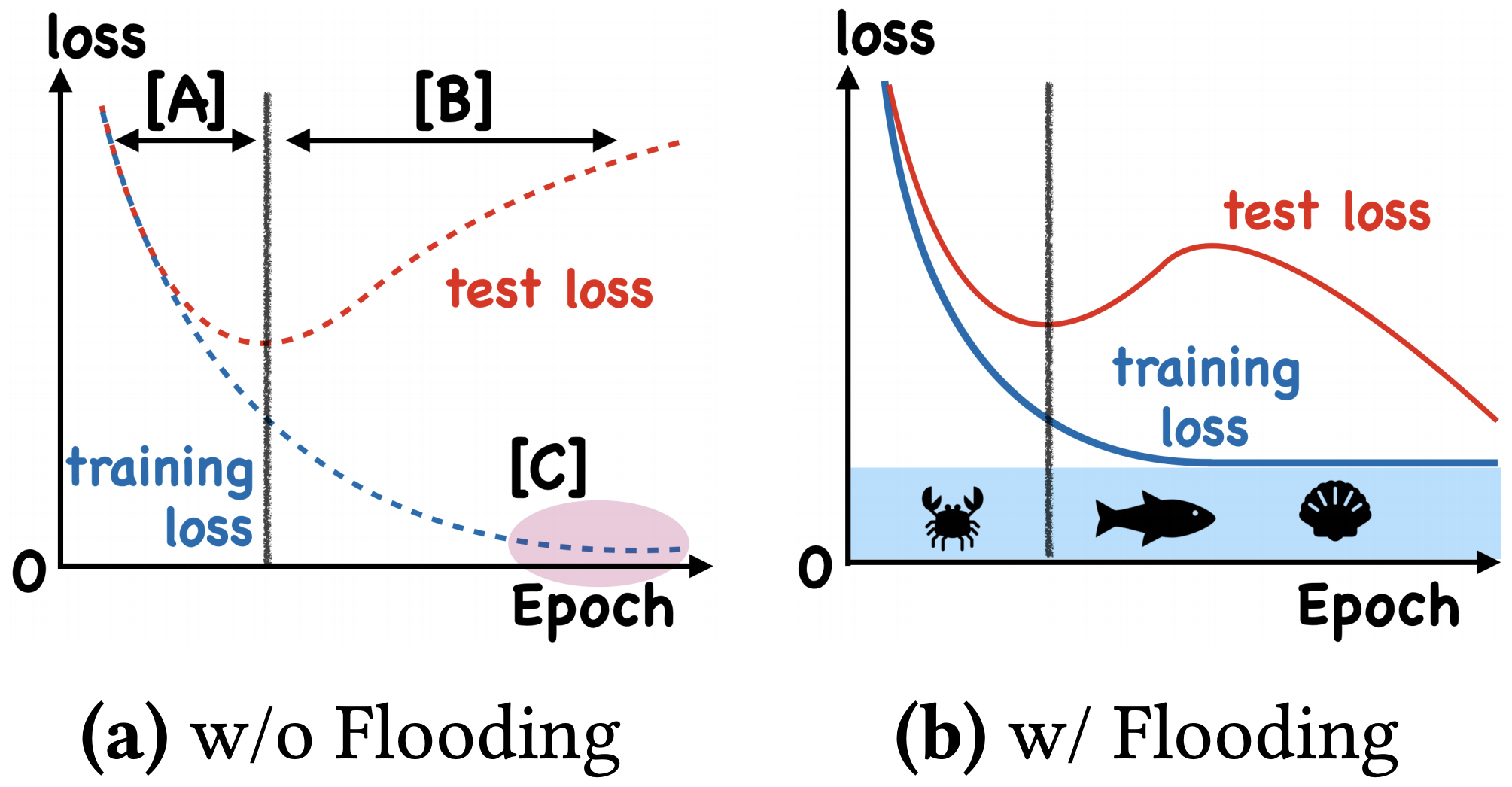
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图
16
Apr
搜狐文本匹配:基于条件LayerNorm的多任务baseline
By 苏剑林 | 2021-04-16 | 85993位读者 | 引用前段时间看到了“2021搜狐校园文本匹配算法大赛”,觉得赛题颇有意思,便尝试了一下,不过由于比赛本身只是面向在校学生,所以笔者是不能作为正式参赛人员参赛的,因此把自己的做法开源出来,作为比赛baseline供大家参考。
赛题介绍
顾名思义,比赛的任务是文本匹配,即判断两个文本是否相似,本来是比较常规的任务,但有意思的是它分了多个子任务。具体来说,它分A、B两大类,A类匹配标准宽松一些,B类匹配标准严格一些,然后每个大类下又分为“短短匹配”、“短长匹配”、“长长匹配”3个小类,因此,虽然任务类型相同,但严格来看它是六个不同的子任务。

最近评论