






7
May
Cool Papers更新:简单搭建了一个站内检索系统
By 苏剑林 | 2024-05-07 | 44963位读者 | 引用自从《更便捷的Cool Papers打开方式:Chrome重定向扩展》之后,Cool Papers有两次比较大的变化,一次是引入了venue分支,逐步收录了一些会议历年的论文集,如ICLR、ICML等,这部分是动态人工扩充的,欢迎有心仪的会议的读者提更多需求;另一次就是本文的主题,前天新增加的站内检索功能。
本文将简单介绍一下新增功能,并对搭建站内检索系统的过程做个基本总结。
简介
在Cool Papers的首页,我们看到搜索入口:

Cool Papers(2024.05.07)
29
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(二)
By 苏剑林 | 2024-07-29 | 26091位读者 | 引用前两周笔者写了《对齐全量微调!这是我看过最精彩的LoRA(一)》(当时还没有编号“一”),里边介绍了一个名为“LoRA-GA”的LoRA变体,它通过梯度SVD来改进LoRA的初始化,从而实现LoRA与全量微调的对齐。当然,从理论上来讲,这样做也只能尽量对齐第一步更新后的$W_1$,所以当时就有读者提出了“后面的$W_2,W_3,\cdots$不管了吗?”的疑问,当时笔者也没想太深入,就单纯觉得对齐了第一步后,后面的优化也会严格一条较优的轨迹走。
有趣的是,LoRA-GA才出来没多久,arXiv上就新出了《LoRA-Pro: Are Low-Rank Adapters Properly Optimized?》,其所提的LoRA-Pro正好能回答这个问题!LoRA-Pro同样是想着对齐全量微调,但它对齐的是每一步梯度,从而对齐整条优化轨迹,这正好是跟LoRA-GA互补的改进点。
对齐全量
本文接着上一篇文章的记号和内容进行讲述,所以这里仅对上一节的内容做一个简单回顾,不再详细重复介绍。LoRA的参数化方式是
\begin{equation}W = (W_0 - A_0 B_0) + AB\end{equation}
26
Aug
近乎完美地解决MathJax与Marked的冲突
By 苏剑林 | 2024-08-26 | 13549位读者 | 引用在《让MathJax更好地兼容谷歌翻译和延时加载》我们提到Cool Papers加入了MathJax来解析LaTeX公式,不过万万没想到引发了诸多兼容性问题,虽然部分问题纯粹是笔者的强迫症作祟,但一个尽可能完美的解决方案终究是让人赏心悦目的,所以还是愿意在上面花一点心思。
上一篇文章我们已经解决了MathJax与谷歌翻译、延时加载的兼容性,这篇文章我们则来解决MathJax与Marked的冲突。
问题简述
Markdown是一种轻量级标记语言,允许人们使用易读易写的纯文本格式编写文档,可谓是目前最流行的写作语法之一,Cool Papers中的[Kimi]功能,基本上也是按照Markdown语法输出。然而。Markdown并不是直接面向浏览器的语言,面向浏览器的语言叫做HTML,所以在展示给用户之前,有一个Markdown转HTML的过程(渲染)。
15
Oct
让MathJax的数学公式随窗口大小自动缩放
By 苏剑林 | 2024-10-15 | 16533位读者 | 引用随着MathJax的出现和流行,在网页上显示数学公式便逐渐有了标准答案。然而,MathJax(包括其竞品KaTeX)只是负责将网页LaTeX代码转化为数学公式,对于自适应分辨率方面依然没有太好的办法。像本站一些数学文章,因为是在PC端排版好的,所以在PC端浏览效果尚可,但转到手机上看就可能有点难以入目了。
经过测试,笔者得到了一个方案,让MathJax的数学公式也能像图片一样,随着窗口大小而自适应缩放,从而尽量保证移动端的显示效果,在此跟大家分享一波。
背景思路
这个问题的起源是,即便在PC端进行排版,有时候也会遇到一些单行公式的长度超出了网页宽度,但又不大好换行的情况,这时候一个解决方案是用HTML代码手动调整一下公式的字体大小,比如
<span style="font-size:90%">
\begin{equation}一个超长的数学公式\end{equation}
</span>
16
Oct
Cool Papers浏览器扩展升级至v0.2.0
By 苏剑林 | 2024-10-16 | 20446位读者 | 引用年初,我们在《更便捷的Cool Papers打开方式:Chrome重定向扩展》中发布了一个Chrome浏览器插件(Cool Papers Redirector v0.1.0),可以通过右击菜单从任意页面中重定向到Cool Papers中,让大家更方便地获取Kimi对论文的理解。前几天我们把该插件升级到了v0.2.0,并顺利上架到了Chrome应用商店中,遂在此向大家推送一下。
更新汇总
相比旧版v0.1.0,当前版v0.2.0的主要更新内容如下:
1、右键菜单跳转改为在新标签页打开;
2、右键菜单支持同时访问多个论文ID;
3、右键菜单支持PDF页面;
4、右键菜单新增更多论文源(arXiv、OpenReview、ACL、IJCAI、PMLR);
5、右键菜单在搜索不到论文ID时,转入站内搜索(即划词搜索);
6、在某些网站的适当位置插入快捷跳转链接(arXiv、OpenReview,ACL)。
29
Nov
从Hessian近似看自适应学习率优化器
By 苏剑林 | 2024-11-29 | 14425位读者 | 引用这几天在重温去年的Meta的一篇论文《A Theory on Adam Instability in Large-Scale Machine Learning》,里边给出了看待Adam等自适应学习率优化器的新视角:它指出梯度平方的滑动平均某种程度上近似于在估计Hessian矩阵的平方,从而Adam、RMSprop等优化器实际上近似于二阶的Newton法。
这个角度颇为新颖,而且表面上跟以往的一些Hessian近似有明显的差异,因此值得我们去学习和思考一番。
牛顿下降
设损失函数为$\mathcal{L}(\boldsymbol{\theta})$,其中待优化参数为$\boldsymbol{\theta}$,我们的优化目标是
\begin{equation}\boldsymbol{\theta}^* = \mathop{\text{argmin}}_{\boldsymbol{\theta}} \mathcal{L}(\boldsymbol{\theta})\label{eq:loss}\end{equation}
假设$\boldsymbol{\theta}$的当前值是$\boldsymbol{\theta}_t$,Newton法通过将损失函数展开到二阶来寻求$\boldsymbol{\theta}_{t+1}$:
\begin{equation}\mathcal{L}(\boldsymbol{\theta})\approx \mathcal{L}(\boldsymbol{\theta}_t) + \boldsymbol{g}_t^{\top}(\boldsymbol{\theta} - \boldsymbol{\theta}_t) + \frac{1}{2}(\boldsymbol{\theta} - \boldsymbol{\theta}_t)^{\top}\boldsymbol{\mathcal{H}}_t(\boldsymbol{\theta} - \boldsymbol{\theta}_t)\end{equation}
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 14651位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
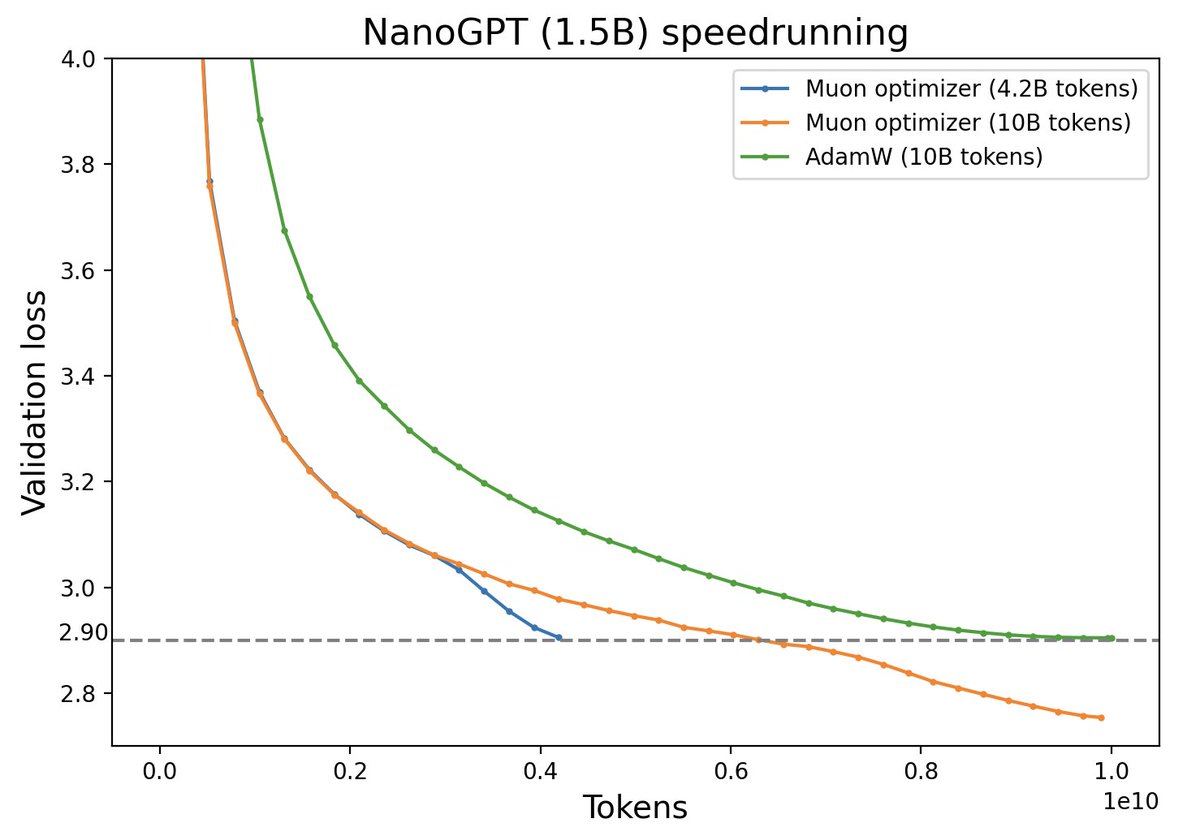
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)
2
Jan
为什么梯度裁剪的默认模长是1?
By 苏剑林 | 2025-01-02 | 7296位读者 | 引用我们知道,梯度裁剪(Gradient Clipping)是让模型训练更加平稳的常用技巧。常用的梯度裁剪是根据所有参数的梯度总模长来对梯度进行裁剪,其运算可以表示为
\begin{equation}\text{clip}(\boldsymbol{g},\tau)=\left\{\begin{aligned}&\boldsymbol{g}, &\Vert\boldsymbol{g}\Vert\leq \tau \\
&\frac{\tau}{\Vert\boldsymbol{g}\Vert}\boldsymbol{g},&\Vert\boldsymbol{g}\Vert > \tau
\end{aligned}\right.\end{equation}
这样一来,$\text{clip}(\boldsymbol{g},\tau)$保持跟$\boldsymbol{g}$相同的方向,但模长不超过$\tau$。注意这里的$\Vert\boldsymbol{g}\Vert$是整个模型所有的参数梯度放在一起视为单个向量所算的模长,也就是所谓的Global Gradient Norm。
不知道大家有没有留意到一个细节:不管是数百万参数还是数百亿参数的模型,$\tau$的取值在很多时候都是1。这意味着什么呢?是单纯地复用默认值,还是背后隐含着什么深刻的原理呢?

最近评论