






29
Oct
用ALBERT和ELECTRA之前,请确认你真的了解它们
By 苏剑林 | 2020-10-29 | 64754位读者 | 引用在预训练语言模型中,ALBERT和ELECTRA算是继BERT之后的两个“后起之秀”。它们从不同的角度入手对BERT进行了改进,最终提升了效果(至少在不少公开评测数据集上是这样),因此也赢得了一定的口碑。但在平时的交流学习中,笔者发现不少朋友对这两个模型存在一些误解,以至于在使用过程中浪费了不必要的时间。在此,笔者试图对这两个模型的一些关键之处做下总结,供大家参考,希望大家能在使用这两个模型的时候少走一些弯路。

ALBERT与ELECTRA
(注:本文中的“BERT”一词既指开始发布的BERT模型,也指后来的改进版RoBERTa,我们可以将BERT理解为没充分训练的RoBERTa,将RoBERTa理解为更充分训练的BERT。本文主要指的是它跟ALBERT和ELECTRA的对比,因此不区分BERT和RoBERTa。)
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 62502位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。
11
Dec
从动力学角度看优化算法(六):为什么SimSiam不退化?
By 苏剑林 | 2020-12-11 | 73487位读者 | 引用自SimCLR以来,CV中关于无监督特征学习的工作层出不穷,让人眼花缭乱。这些工作大多数都是基于对比学习的,即通过适当的方式构造正负样本进行分类学习的。然而,在众多类似的工作中总有一些特立独行的研究,比如Google的BYOL和最近的SimSiam,它们提出了单靠正样本就可以完成特征学习的方案,让人觉得耳目一新。但是没有负样本的支撑,模型怎么不会退化(坍缩)为一个没有意义的常数模型呢?这便是这两篇论文最值得让人思考和回味的问题了。
其中SimSiam给出了让很多人都点赞的答案,但笔者觉得SimSiam也只是把问题换了种说法,并没有真的解决这个问题。笔者认为,像SimSiam、GAN等模型的成功,很重要的原因是使用了基于梯度的优化器(而非其他更强或者更弱的优化器),所以不结合优化动力学的答案都是不完整的。在这里,笔者尝试结合动力学来分析SimSiam不会退化的原因。
SimSiam
在看SimSiam之前,我们可以先看看BYOL,来自论文《Bootstrap your own latent: A new approach to self-supervised Learning》,其学习过程很简单,就是维护两个编码器Student和Teacher,其中Teacher是Student的滑动平均,Student则又反过来向Teacher学习,有种“左脚踩右脚”就可以飞起来的感觉。示意图如下:
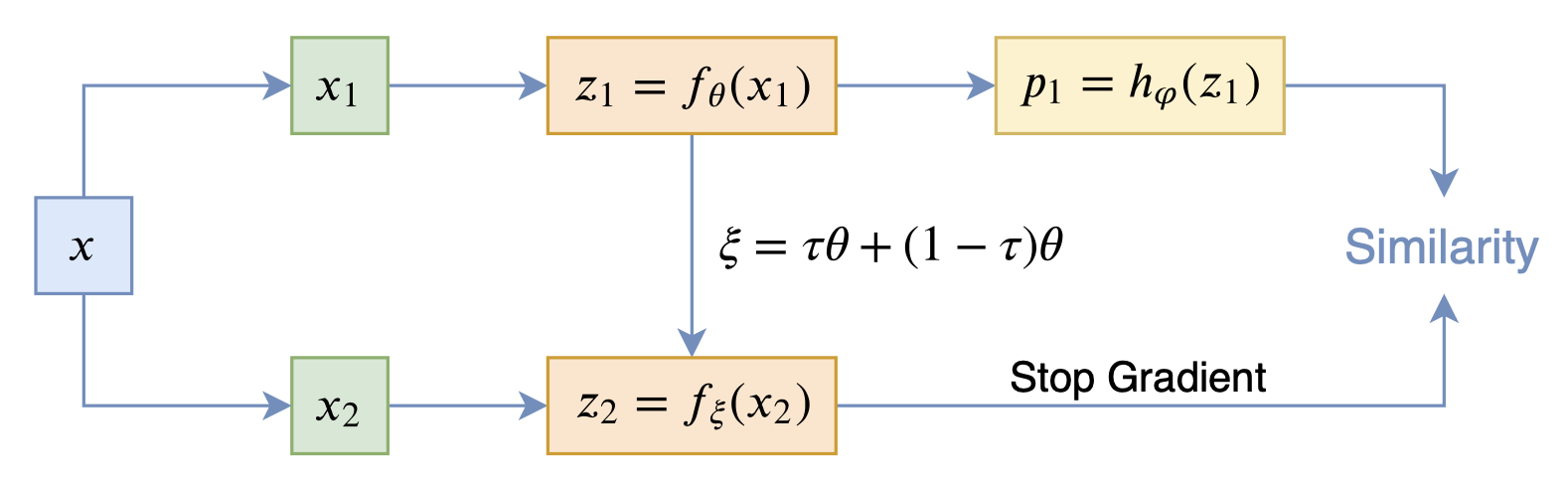
BYOL示意图
20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 64933位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
4
Dec
层次分解位置编码,让BERT可以处理超长文本
By 苏剑林 | 2020-12-04 | 109158位读者 | 引用大家都知道,目前的主流的BERT模型最多能处理512个token的文本。导致这一瓶颈的根本原因是BERT使用了从随机初始化训练出来的绝对位置编码,一般的最大位置设为了512,因此顶多只能处理512个token,多出来的部分就没有位置编码可用了。当然,还有一个重要的原因是Attention的$\mathcal{O}(n^2)$复杂度,导致长序列时显存用量大大增加,一般显卡也finetune不了。
位置编码的层次分解示意图
本文主要面向前一个原因,即假设有足够多的显存前提下,如何简单修改当前最大长度为512的BERT模型,使得它可以直接处理更长的文本,主要思路是层次分解已经训练好的绝对位置编码,使得它可以延拓到更长的位置。
9
Feb
一个二值化词向量模型,是怎么跟果蝇搭上关系的?
By 苏剑林 | 2021-02-09 | 24676位读者 | 引用
果蝇(图片来自Google搜索)
可能有些读者最近会留意到ICLR 2021的论文《Can a Fruit Fly Learn Word Embeddings?》,文中写到它是基于仿生思想(仿果蝇的嗅觉回路)做出来的一个二值化词向量模型。其实论文的算法部分并不算难读,可能整篇论文读下来大家的最主要疑惑就是“这东西跟果蝇有什么关系?”、“作者真是从果蝇里边受到启发的?”等等。本文就让我们来追寻一下该算法的来龙去脉,试图回答一下这个词向量模型是怎么跟果蝇搭上关系的。
BioWord
原论文并没有给该词向量模型起个名字,为了称呼上的方便,这里笔者就自作主张将其称为“BioWord”了。总的来说,论文内容大体上有三部分:
1、给每个n-gram构建了一个词袋表示向量;
2、对这些n-gram向量执行BioHash算法,得到所谓的(二值化的)静态/动态词向量;
3、“拼命”讲了一个故事。
26
Jan
Seq2Seq重复解码现象的理论分析尝试
By 苏剑林 | 2021-01-26 | 29513位读者 | 引用去年笔者写过博文《如何应对Seq2Seq中的“根本停不下来”问题?》,里边介绍了一篇论文中对Seq2Seq解码不停止现象的处理,并指出那篇论文只是提了一些应对该问题的策略,并没有提供原理上的理解。近日,笔者在Arixv读到了AAAI 2021的一篇名为《A Theoretical Analysis of the Repetition Problem in Text Generation》的论文,里边从理论上分析了Seq2Seq重复解码现象。从本质上来看,重复解码和解码不停止其实都是同理的,所以这篇新论文算是填补了前面那篇论文的空白。
经过学习,笔者发现该论文确实有不少可圈可点之处,值得一读。笔者对原论文中的分析过程做了一些精简、修正和推广,将结果记录成此文,供大家参考。此外,抛开问题背景不讲,读者也可以将本文当成一节矩阵分析习题课,供大家复习线性代数哈~
9
Oct
关于WhiteningBERT原创性的疑问和沟通
By 苏剑林 | 2021-10-09 | 62023位读者 | 引用在文章《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者受到BERT-flow的启发,提出了一种名为BERT-whitening的替代方案,它比BERT-flow更简单,但多数数据集下能取得相近甚至更好的效果,此外它还可以用于对句向量降维以提高检索速度。后来,笔者跟几位合作者一起补充了BERT-whitening的实验,并将其写成了英文论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》,在今年3月29日发布在Arxiv上。
然而,大约一周后,一篇名为《WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach》的论文 (下面简称WhiteningBERT)出现在Arxiv上,内容跟BERT-whitening高度重合,有读者看到后向我反馈WhiteningBERT抄袭了BERT-whitening。本文跟关心此事的读者汇报一下跟WhiteningBERT的作者之间的沟通结果。
时间节点
首先,回顾一下BERT-whitening的相关时间节点,以帮助大家捋一下事情的发展顺序:

最近评论