






 感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持!
感谢国家天文台LAMOST项目之“宇宙驿站”提供网络空间和数据库资源! 感谢国家天文台崔辰州博士等人的多方努力和技术支持! 科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
科学空间致力于知识分享,所以欢迎您转载本站文章,但转载本站内容必须遵循 署名-非商业用途-保持一致 的创作共用协议。
17
Nov
AdamW的Weight RMS的渐近估计(下)
By 苏剑林 | 2025-11-17 | 14115位读者 | Kimi 引用在博客《AdamW的Weight RMS的渐近估计(上)》中,我们推导了AdamW训练出来的模型权重的RMS渐近表达式。不过,那会我们假设了Weight Decay和学习率在整个训练过程中是固定的,这跟实际训练并不完全吻合,所以这篇文章我们将之前的结论推广成动态版。
所谓动态版,即允许Weight Decay和学习率都随着训练步数的增加而变化,比如经典的Cosine Decay、WSD(Warmup Stable Decay)等,从而让结论更为通用。
步骤之一
我们的出发点还是AdamW的定义:
\begin{equation}\text{Adam}\color{skyblue}{\text{W}}:=\left\{\begin{aligned}
&\boldsymbol{m}_t = \beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\\
&\boldsymbol{v}_t = \beta_2 \boldsymbol{v}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t^2\\
&\hat{\boldsymbol{m}}_t = \boldsymbol{m}_t\left/\left(1 - \beta_1^t\right)\right.\\
&\hat{\boldsymbol{v}}_t = \boldsymbol{v}_t\left/\left(1 - \beta_2^t\right)\right.\\
&\boldsymbol{u}_t =\hat{\boldsymbol{m}}_t\left/\left(\sqrt{\hat{\boldsymbol{v}}_t} + \epsilon\right)\right.\\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}})
\end{aligned}\right.\end{equation}
6
Nov
n个正态随机数的最大值的渐近估计
By 苏剑林 | 2025-11-06 | 21787位读者 | Kimi 引用设$z_1,z_2,\cdots,z_n$是$n$个从标准正态分布中独立重复采样出来的随机数,由此我们可以构造出很多衍生随机变量,比如$z_1+z_2+\cdots+z_n$,它依旧服从正态分布,又比如$z_1^2+z_2^2+\cdots+z_n^2$,它服从卡方分布。这篇文章我们来关心它的最大值$z_{\max} = \max\{z_1,z_2,\cdots,z_n\}$的分布信息,尤其是它的数学期望$\mathbb{E}[z_{\max}]$。
先看结论
关于$\mathbb{E}[z_{\max}]$的基本估计结果是:
设$z_1,z_2,\cdots,z_n\sim\mathcal{N}(0,1)$,$z_{\max} = \max\{z_1,z_2,\cdots,z_n\}$,那么 \begin{equation}\mathbb{E}[z_{\max}]\sim \sqrt{2\log n}\label{eq:E-z-max}\end{equation}
3
Nov
流形上的最速下降:5. 对偶梯度下降
By 苏剑林 | 2025-11-03 | 21692位读者 | Kimi 引用前四篇文章我们求解了几个具体的给参数加等式约束的最速下降问题,其中第三、四篇的问题没法找到解析解,所以笔者提出了相应的不动点迭代法。其中的其中,第三篇文章《流形上的最速下降:3. Muon + Stiefel》所研究的“Stiefel流形上的Muon”,问题提出自Jeremy Bernstein的《Orthogonal manifold》一文。
对于这个问题,Jeremy Bernstein最后也给出了一个自己的解法,笔者称之为“对偶梯度下降(Dual Gradient Descent)”,也颇为值得学习一番。
基本概念
Jeremy Bernstein的解法,最后发表在Thinking Machines Lab的博客《Modular Manifolds》中,是该实验室的第二篇博客,文章中将它称为“对偶上升(Dual Ascent)”,但笔者这里还是结合前四篇的内容,将其称为“对偶梯度下降”。
27
Oct
低精度Attention可能存在有偏的舍入误差
By 苏剑林 | 2025-10-27 | 35542位读者 | Kimi 引用前段时间笔者在arXiv上刷到了论文《Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention》,里面描述的实验现象跟我们在训练Kimi K2时出现的一些现象很吻合,比如都是第二层Attention开始出现问题。论文将其归因为低精度Attention固有的有偏误差,这个分析角度是比较出乎笔者意料的,所以饶有兴致地阅读了一番。
然而,论文的表述似乎比较让人费解——当然也有笔者本就不大熟悉低精度运算的原因。总之,经过多次向作者请教后,笔者才勉强看懂论文,遂将自己的理解记录在此,供大家参考。
结论简述
要指出的是,论文标题虽然点名了“Flash Attention”,但按照论文的描述,即便block_size取到训练长度那么大,相同的问题依然会出现,所以Flash Attention的分块计算并不是引起问题的原因,因此我们可以按照朴素的低精度Attention实现来简化分析。
21
Oct
MuP之上:1. 好模型的三个特征
By 苏剑林 | 2025-10-21 | 27218位读者 | Kimi 引用不知道大家有没有发现一个有趣的细节,Muon和MuP都是“Mu”开头,但两个“Mu”的原意完全不一样,前者是“MomentUm Orthogonalized by Newton-Schulz”,后者是“Maximal Update Parametrization”,可它们俩之间确实有着非常深刻的联系。也就是说,Muon和MuP有着截然不同的出发点,但最终都走向了相同的方向,甚至无意间取了相似的名字,似乎真应了那句“冥冥中自有安排”。
言归正传。总之,笔者在各种机缘巧合之下,刚好同时学习到了Muon和MuP,这大大加深了笔者对模型优化的理解,同时也让笔者开始思考关于模型优化更本质的原理。经过一段时间的试错,算是有些粗浅的收获,在此跟大家分享一下。
写在前面
按照提出时间的先后顺序,是先有MuP再有Muon,但笔者的学习顺序正好反过来,先学习了Muon然后再学习MuP,事后来看,这也不失为一个不错的学习顺序。
12
Oct
随机矩阵的谱范数的快速估计
By 苏剑林 | 2025-10-12 | 25575位读者 | Kimi 引用在《高阶MuP:更简明但更高明的谱条件缩放》的“近似估计”一节中,我们曾“预支”了一个结论:“一个服从标准正态分布的$n\times m$大小的随机矩阵,它的谱范数大致是$\sqrt{n}+\sqrt{m}$。”
这篇文章我们来补充讨论这个结论,给出随机矩阵谱范数的快速估计方法。
随机矩阵论
设有随机矩阵$\boldsymbol{W}\in\mathbb{R}^{n\times m}$,每个元素都是从标准正态分布$\mathcal{N}(0,1)$中独立重复地采样出来的,要求估计$\boldsymbol{W}$的谱范数,也就是最大奇异值,我们以$\mathbb{E}[\Vert\boldsymbol{W}\Vert_2]$为最终的估计结果。
8
Oct
DiVeQ:一种非常简洁的VQ训练方案
By 苏剑林 | 2025-10-08 | 36473位读者 | Kimi 引用对于坚持离散化路线的研究人员来说,VQ(Vector Quantization)是视觉理解和生成的关键部分,担任着视觉中的“Tokenizer”的角色。它提出在2017年的论文《Neural Discrete Representation Learning》,笔者在2019年的博客《VQ-VAE的简明介绍:量子化自编码器》也介绍过它。
然而,这么多年过去了,我们可以发现VQ的训练技术几乎没有变化,都是STE(Straight-Through Estimator)加额外的Aux Loss。STE倒是没啥问题,它可以说是给离散化运算设计梯度的标准方式了,但Aux Loss的存在总让人有种不够端到端的感觉,同时还引入了额外的超参要调。
幸运的是,这个局面可能要结束了,上周的论文《DiVeQ: Differentiable Vector Quantization Using the Reparameterization Trick》提出了一个新的STE技巧,它最大亮点是不需要Aux Loss,这让它显得特别简洁漂亮!
5
Oct
为什么线性注意力要加Short Conv?
By 苏剑林 | 2025-10-05 | 47102位读者 | Kimi 引用如果读者有关注模型架构方面的进展,那么就会发现,比较新的线性Attention(参考《线性注意力简史:从模仿、创新到反哺》)模型都给$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$加上了Short Conv,比如下图所示的DeltaNet:
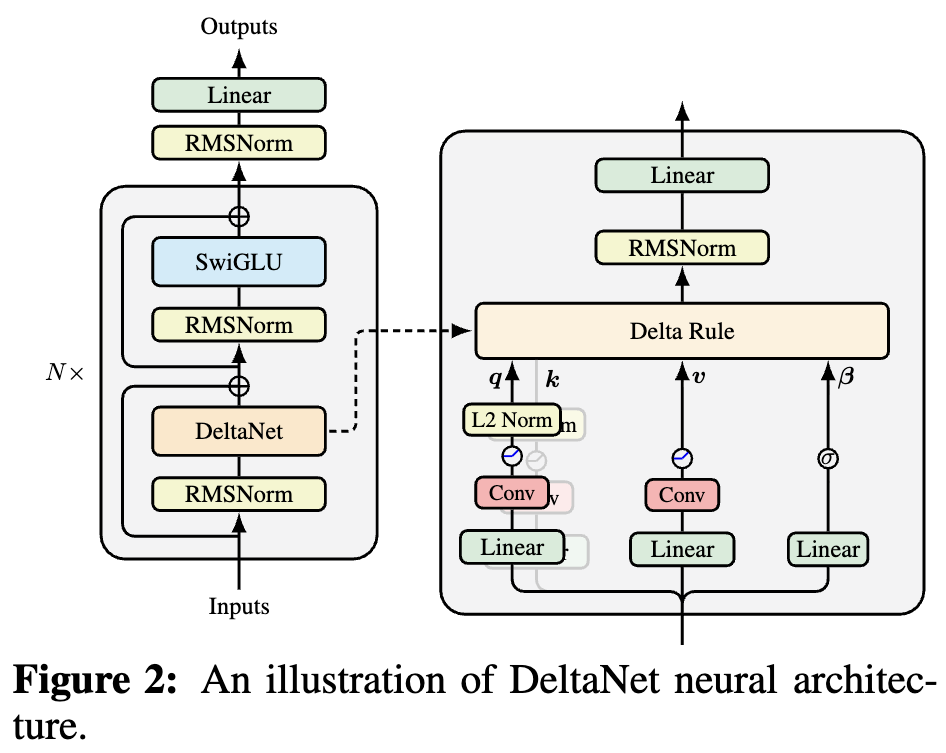
DeltaNet中的Short Conv
为什么要加这个Short Conv呢?直观理解可能是增加模型深度、增强模型的Token-Mixing能力等,说白了就是补偿线性化导致的表达能力下降。这个说法当然是大差不差,但它属于“万能模版”式的回答,我们更想对它的生效机制有更准确的认知。
接下来,笔者将给出自己的一个理解(更准确说应该是猜测)。

最近评论