






22
Feb
巧断梯度:单个loss实现GAN模型
By 苏剑林 | 2019-02-22 | 57315位读者 | 引用我们知道普通的模型都是搭好架构,然后定义好loss,直接扔给优化器训练就行了。但是GAN不一样,一般来说它涉及有两个不同的loss,这两个loss需要交替优化。现在主流的方案是判别器和生成器都按照1:1的次数交替训练(各训练一次,必要时可以给两者设置不同的学习率,即TTUR),交替优化就意味我们需要传入两次数据(从内存传到显存)、执行两次前向传播和反向传播。
如果我们能把这两步合并起来,作为一步去优化,那么肯定能节省时间的,这也就是GAN的同步训练。
(注:本文不是介绍新的GAN,而是介绍GAN的新写法,这只是一道编程题,不是一道算法题~)
如果在TF中
27
Jan
“让Keras更酷一些!”:随意的输出和灵活的归一化
By 苏剑林 | 2019-01-27 | 129164位读者 | 引用继续“让Keras更酷一些!”系列,让Keras来得更有趣些吧~
这次围绕着Keras的loss、metric、权重和进度条进行展开。
可以不要输出
一般我们用Keras定义一个模型,是这样子的:
x_in = Input(shape=(784,))
x = x_in
x = Dense(100, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='categorical_crossentropy ',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
8
Sep
“让Keras更酷一些!”:小众的自定义优化器
By 苏剑林 | 2018-09-08 | 111847位读者 | 引用沿着之前的《“让Keras更酷一些!”:精巧的层与花式的回调》写下去~
今天我们来看一个小众需求:自定义优化器。
细想之下,不管用什么框架,自定义优化器这个需求可谓真的是小众中的小众。一般而言,对于大多数任务我们都可以无脑地直接上Adam,而调参炼丹高手一般会用SGD来调出更好的效果,换言之不管是高手新手,都很少会有自定义优化器的需求。
那这篇文章还有什么价值呢?有些场景下会有一点点作用。比如通过学习Keras中的优化器写法,你可以对梯度下降等算法有进一步的认识,你还可以顺带看到Keras的源码是多么简洁优雅。此外,有时候我们可以通过自定义优化器来实现自己的一些功能,比如给一些简单的模型(例如Word2Vec)重写优化器(直接写死梯度,而不是用自动求导),可以使得算法更快;自定义优化器还可以实现诸如“软batch”的功能。
Keras优化器
我们首先来看Keras中自带优化器的代码,位于:
https://github.com/keras-team/keras/blob/master/keras/optimizers.py
1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 449259位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
6
Aug
“让Keras更酷一些!”:精巧的层与花式的回调
By 苏剑林 | 2018-08-06 | 209099位读者 | 引用Keras伴我走来
回想起进入机器学习领域的这两三年来,Keras是一直陪伴在笔者的身边。要不是当初刚掉进这个坑时碰到了Keras这个这么易用的框架,能快速实现我的想法,我也不确定我是否能有毅力坚持下来,毕竟当初是theano、pylearn、caffe、torch等的天下,哪怕在今天它们对我来说仍然像天书一般。
后来为了拓展视野,我也去学习了一段时间的tensorflow,用纯tensorflow写过若干程序,但不管怎样,仍然无法割舍Keras。随着对Keras的了解的深入,尤其是花了一点时间研究过Keras的源码后,我发现Keras并没有大家诟病的那样“欠缺灵活性”。事实上,Keras那精巧的封装,可以让我们轻松实现很多复杂的功能。我越来越感觉,Keras像是一件非常精美的艺术品,充分体现了Keras的开发者们深厚的创作功力。
本文介绍Keras中自定义模型的一些内容,相对而言,这属于Keras进阶的内容,刚入门的朋友请暂时忽略。
层的自定义
这里介绍Keras中自定义层及其一些运用技巧,在这之中我们可以看到Keras层的精巧之处。
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 435212位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
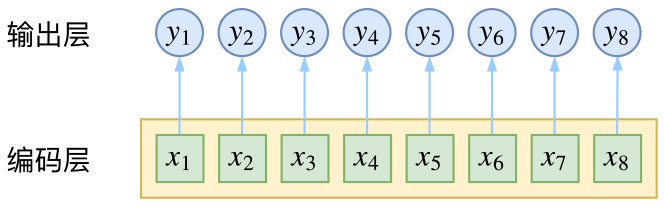
逐帧softmax并没有直接考虑输出的上下文关联
6
Aug
【不可思议的Word2Vec】6. Keras版的Word2Vec
By 苏剑林 | 2017-08-06 | 183948位读者 | 引用前言
看过我之前写的TF版的Word2Vec后,Keras群里的Yin神问我有没有Keras版的。事实上在做TF版之前,我就写过Keras版的,不过没有保留,所以重写了一遍,更高效率,代码也更好看了。纯Keras代码实现Word2Vec,原理跟《【不可思议的Word2Vec】5. Tensorflow版的Word2Vec》是一样的,现在放出来,我想,会有人需要的。(比如,自己往里边加一些额外输入,然后做更好的词向量模型?)
由于Keras同时支持tensorflow、theano、cntk等多个后端,这就等价于实现了多个框架的Word2Vec了。嗯,这样想就高大上了,哈哈~
代码
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 567013位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。

最近评论