






20
Apr
EAE:自编码器 + BN + 最大熵 = 生成模型
By 苏剑林 | 2020-04-20 | 79908位读者 | 引用生成模型一直是笔者比较关注的主题,不管是NLP和CV的生成模型都是如此。这篇文章里,我们介绍一个新颖的生成模型,来自论文《Batch norm with entropic regularization turns deterministic autoencoders into generative models》,论文中称之为EAE(Entropic AutoEncoder)。它要做的事情给变分自编码器(VAE)基本一致,最终效果其实也差不多(略优),说它新颖并不是它生成效果有多好,而是思路上的新奇,颇有别致感。此外,借着这个机会,我们还将学习一种统计量的估计方法——$k$邻近方法,这是一种很有用的非参数估计方法。
自编码器vs生成模型
普通的自编码器是一个“编码-解码”的重构过程,如下图所示:
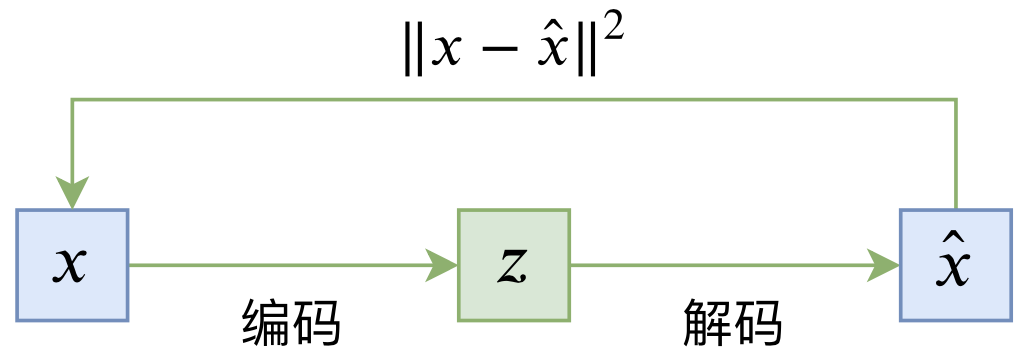
典型自编码器示意图
其loss一般为
\begin{equation}L_{AE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - \hat{x}\right\Vert^2\right] = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(E(x))\right\Vert^2\right]\end{equation}
13
Feb
Designing GANs:又一个GAN生产车间
By 苏剑林 | 2020-02-13 | 42768位读者 | 引用在2018年的文章里《f-GAN简介:GAN模型的生产车间》笔者介绍了f-GAN,并评价其为GAN模型的“生产车间”,顾名思义,这是指它能按照固定的流程构造出很多不同形式的GAN模型来。前几天在arxiv上看到了新出的一篇论文《Designing GANs: A Likelihood Ratio Approach》(后面简称Designing GANs或原论文),发现它在做跟f-GAN同样的事情,但走的是一条截然不同的路(不过最后其实是殊途同归),整篇论文颇有意思,遂在此分享一番。
f-GAN回顾
从《f-GAN简介:GAN模型的生产车间》中我们可以知道,f-GAN的首要步骤是找到满足如下条件的函数$f$:
1、$f$是非负实数到实数的映射($\mathbb{R}^* \to \mathbb{R}$);
2、$f(1)=0$;
3、$f$是凸函数。
26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 109259位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
1
Dec
级联抑制:提升GAN表现的一种简单有效的方法
By 苏剑林 | 2019-12-01 | 41765位读者 | 引用昨天刷arxiv时发现了一篇来自星星韩国的论文,名字很直白,就叫做《A Simple yet Effective Way for Improving the Performance of GANs》。打开一看,发现内容也很简练,就是提出了一种加强GAN的判别器的方法,能让GAN的生成指标有一定的提升。
作者把这个方法叫做Cascading Rejection,我不知道咋翻译,扔到百度翻译里边显示“级联抑制”,想想看好像是有这么点味道,就暂时这样叫着了。介绍这个方法倒不是因为它有多强大,而是觉得它的几何意义很有趣,而且似乎有一定的启发性。
正交分解
GAN的判别器一般是经过多层卷积后,通过flatten或pool得到一个固定长度的向量$\boldsymbol{v}$,然后再与一个权重向量$\boldsymbol{w}$做内积,得到一个标量打分(先不考虑偏置项和激活函数等末节):
\begin{equation}D(\boldsymbol{x})=\langle \boldsymbol{v},\boldsymbol{w}\rangle\end{equation}
也就是说,用$\boldsymbol{v}$作为输入图片的表征,然后通过$\boldsymbol{v}$和$\boldsymbol{w}$的内积大小来判断出这个图片的“真”的程度。
31
Oct
从去噪自编码器到生成模型
By 苏剑林 | 2019-10-31 | 151253位读者 | 引用在我看来,几大顶会之中,ICLR的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是《Learning Generative Models using Denoising Density Estimators》和《Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces》。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。

fashion mnist、CelebA、cifar10上的生成效果
24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 484284位读者 | 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。
10
May
能量视角下的GAN模型(三):生成模型=能量模型
By 苏剑林 | 2019-05-10 | 71437位读者 | 引用
本文的模型在ImageNet(128x128)上的条件生成效果
今天要介绍的结果还是跟能量模型相关,来自论文《Implicit Generation and Generalization in Energy-Based Models》。当然,它已经跟GAN没有什么关系了,但是跟本系列第二篇所介绍的能量模型关系较大,所以还是把它放到这个系列好了。
我当初留意到这篇论文,是因为机器之心的报导《MIT本科学神重启基于能量的生成模型,新框架堪比GAN》,但是说实在的,这篇文章没什么意思,说句不中听的,就是炒冷饭系列,媒体的标题也算中肯,是“重启”。这篇文章就是指出能量模型实际上就是某个特定的Langevin方程的静态解,然后就用这个Langevin方程来实现采样,有了采样过程也就可以完成能量模型的训练,这些理论都是现成的,所以这个过程我在学习随机微分方程的时候都想过,我相信很多人也都想过。因此,我觉得作者的贡献就是把这个直白的想法通过一系列炼丹技巧实现了。
但不管怎样,能训练出来也是一件很不错的事情,另外对于之前没了解过相关内容的读者来说,这确实也算是一个不错的能量模型案例,所以我论文的整体思路整理一下,让读者能够更全面地理解能量模型。
3
May
从动力学角度看优化算法(四):GAN的第三个阶段
By 苏剑林 | 2019-05-03 | 131071位读者 | 引用在对GAN的学习和思考过程中,我发现我不仅学习到了一种有效的生成模型,而且它全面地促进了我对各种模型各方面的理解,比如模型的优化和理解视角、正则项的意义、损失函数与概率分布的联系、概率推断等等。GAN不单单是一个“造假的玩具”,而是具有深刻意义的概率模型和推断方法。
作为事后的总结,我觉得对GAN的理解可以粗糙地分为三个阶段:
1、样本阶段:在这个阶段中,我们了解了GAN的“鉴别者-造假者”诠释,懂得从这个原理出发来写出基本的GAN公式(如原始GAN、LSGAN),比如判别器和生成器的loss,并且完成简单GAN的训练;同时,我们知道GAN有能力让图片更“真”,利用这个特性可以把GAN嵌入到一些综合模型中。
2、分布阶段:在这个阶段中,我们会从概率分布及其散度的视角来分析GAN,典型的例子是WGAN和f-GAN,同时能基本理解GAN的训练困难问题,比如梯度消失和mode collapse等,甚至能基本地了解变分推断,懂得自己写出一些概率散度,继而构造一些新的GAN形式。
3、动力学阶段:在这个阶段中,我们开始结合优化器来分析GAN的收敛过程,试图了解GAN是否能真的达到理论的均衡点,进而理解GAN的loss和正则项等因素如何影响的收敛过程,由此可以针对性地提出一些训练策略,引导GAN模型到达理论均衡点,从而提高GAN的效果。

最近评论