






3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 198367位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
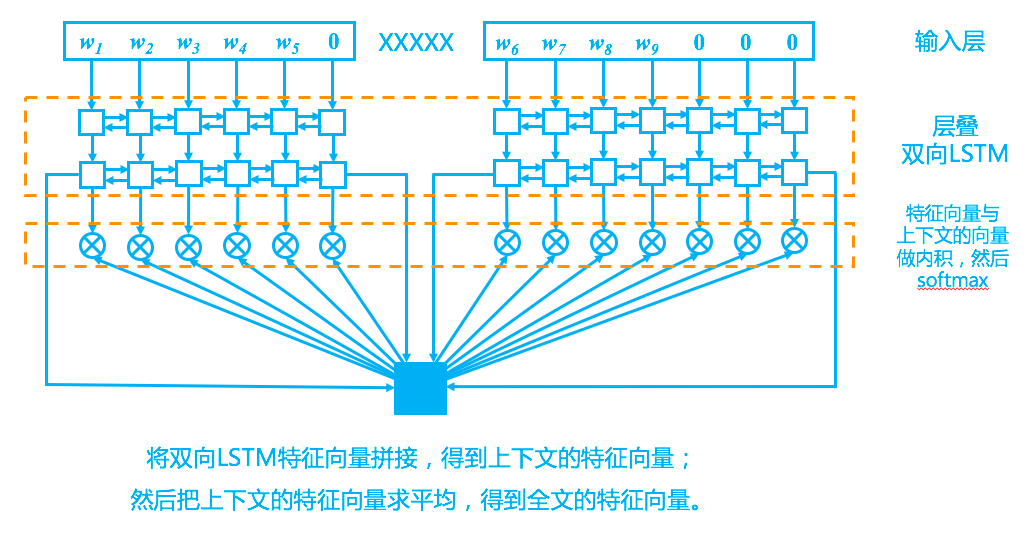
完形填空模型
19
Nov
更别致的词向量模型(六):代码、分享与结语
By 苏剑林 | 2017-11-19 | 91299位读者 | 引用
25
Nov
果壳中的条件随机场(CRF In A Nutshell)
By 苏剑林 | 2017-11-25 | 110227位读者 | 引用本文希望用尽可能简短的语言把CRF(条件随机场,Conditional Random Field)的原理讲清楚,这里In A Nutshell在英文中其实有“导论”、“科普”等意思(霍金写过一本《果壳中的宇宙》,这里东施效颦一下)。
网上介绍CRF的文章,不管中文英文的,基本上都是先说一些概率图的概念,然后引入特征的指数公式,然后就说这是CRF。所谓“概率图”,只是一个形象理解的说法,然而如果原理上说不到点上,你说太多形象的比喻,反而让人糊里糊涂,以为你只是在装逼。(说到这里我又想怼一下了,求解神经网络,明明就是求一下梯度,然后迭代一下,这多好理解,偏偏还弄个装逼的名字叫“反向传播”,如果不说清楚它的本质是求导和迭代求解,一下子就说反向传播,有多少读者会懂?)
好了,废话说完了,来进入正题。
逐标签Softmax
CRF常见于序列标注相关的任务中。假如我们的模型输入为$Q$,输出目标是一个序列$a_1,a_2,\dots,a_n$,那么按照我们通常的建模逻辑,我们当然是希望目标序列的概率最大
$$P(a_1,a_2,\dots,a_n|Q)$$
不管用传统方法还是用深度学习方法,直接对完整的序列建模是比较艰难的,因此我们通常会使用一些假设来简化它,比如直接使用朴素假设,就得到
$$P(a_1,a_2,\dots,a_n|Q)=P(a_1|Q)P(a_2|Q)\dots P(a_n|Q)$$
18
Apr
最小熵原理(一):无监督学习的原理
By 苏剑林 | 2018-04-18 | 83835位读者 | 引用话在开头
在深度学习等端到端方案已经逐步席卷NLP的今天,你是否还愿意去思考自然语言背后的基本原理?我们常说“文本挖掘”,你真的感受到了“挖掘”的味道了吗?
无意中的邂逅
前段时间看了一篇关于无监督句法分析的文章,继而从它的参考文献中发现了论文《Redundancy Reduction as a Strategy for Unsupervised Learning》,这篇论文介绍了如何从去掉空格的英文文章中将英文单词复原。对应到中文,这不就是词库构建吗?于是饶有兴致地细读了一番,发现论文思路清晰、理论完整、结果漂亮,让人赏心悦目。
尽管现在看来,这篇论文的价值不是很大,甚至其结果可能已经被很多人学习过了,但是要注意:这是一篇1993年的论文!在PC机还没有流行的年代,就做出了如此前瞻性的研究。虽然如今深度学习流行,NLP任务越做越复杂,这确实是一大进步,但是我们对NLP原理的真正了解,还不一定超过几十年前的前辈们多少。
这篇论文是通过“去冗余”(Redundancy Reduction)来实现无监督地构建词库的,从信息论的角度来看,“去冗余”就是信息熵的最小化。无监督句法分析那篇文章也指出“信息熵最小化是无监督的NLP的唯一可行的方案”。我进而学习了一些相关资料,并且结合自己的理解思考了一番,发现这个评论确实是耐人寻味。我觉得,不仅仅是NLP,信息熵最小化很可能是所有无监督学习的根本。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 244571位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
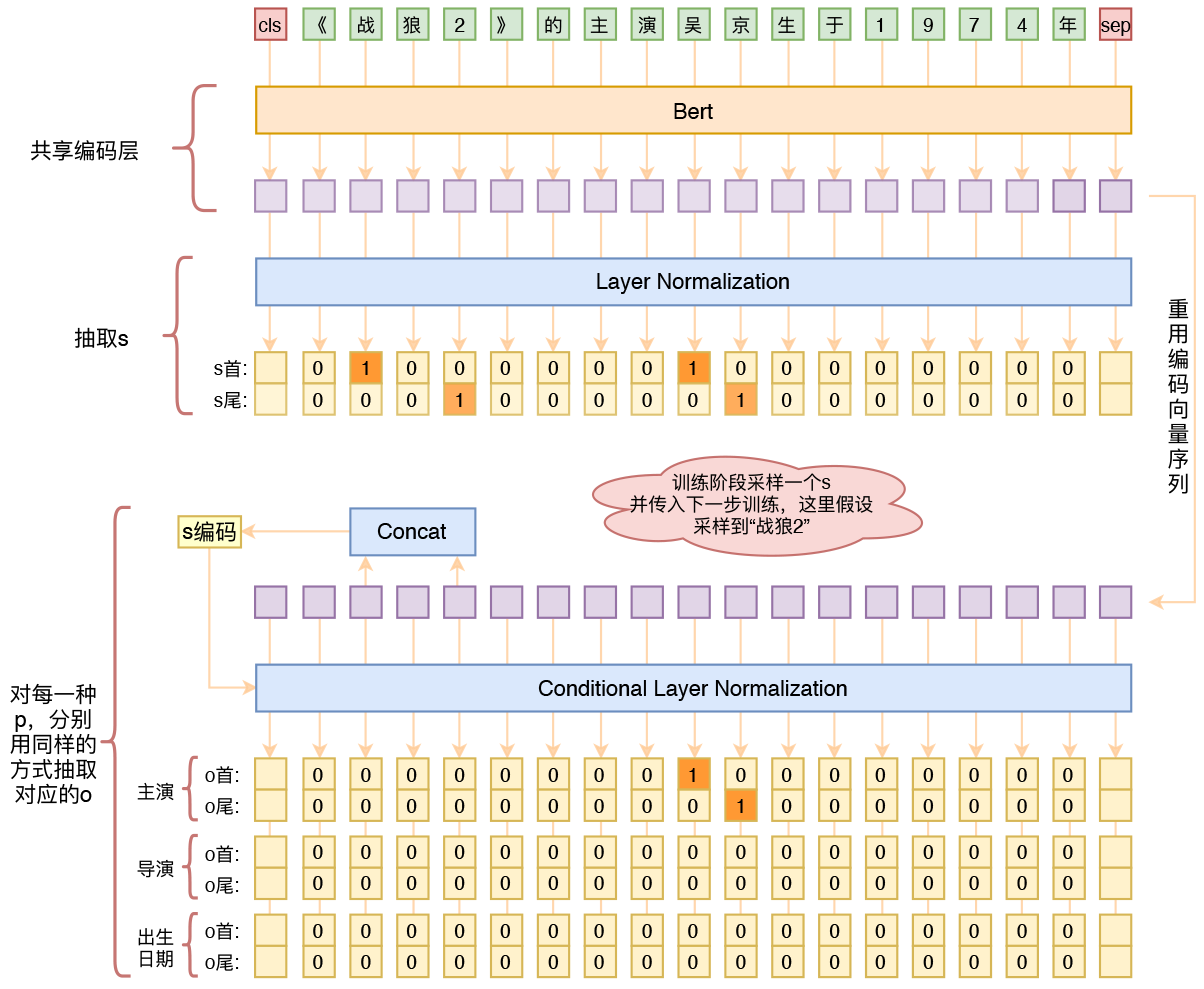
基于Bert的三元组抽取模型结构示意图
3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 395580位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 409035位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
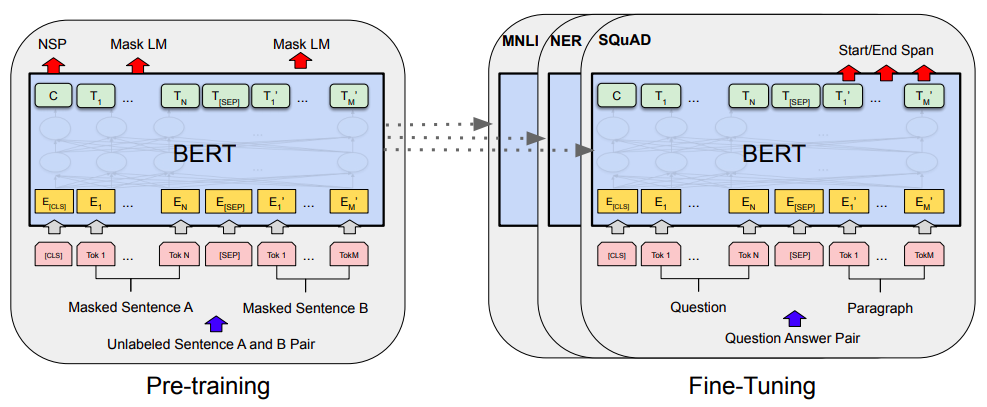
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 146907位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
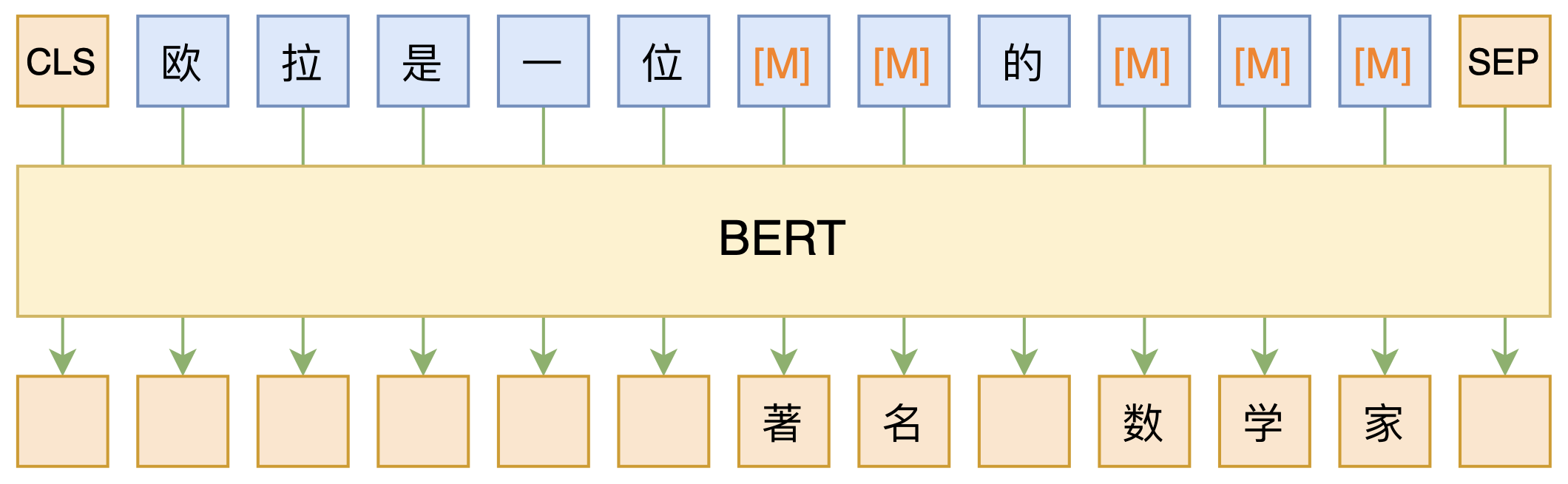
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。

最近评论