






28
Jun
积分梯度:一种新颖的神经网络可视化方法
By 苏剑林 | 2020-06-28 | 90490位读者 | 引用本文介绍一种神经网络的可视化方法:积分梯度(Integrated Gradients),它首先在论文《Gradients of Counterfactuals》中提出,后来《Axiomatic Attribution for Deep Networks》再次介绍了它,两篇论文作者都是一样的,内容也大体上相同,后一篇相对来说更易懂一些,如果要读原论文的话,建议大家优先读后一篇。当然,它已经是2016~2017年间的工作了,“新颖”说的是它思路上的创新有趣,而不是指最近发表。

笔者在中文情感分类上对积分梯度的实验效果(越红的token越重要)
所谓可视化,简单来说就是对于给定的输入$x$以及模型$F(x)$,我们想办法指出$x$的哪些分量对模型的决策有重要影响,或者说对$x$各个分量的重要性做个排序,用专业的话术来说那就是“归因”。一个朴素的思路是直接使用梯度$\nabla_x F(x)$来作为$x$各个分量的重要性指标,而积分梯度是对它的改进。然而,笔者认为,很多介绍积分梯度方法的文章(包括原论文),都过于“生硬”(形式化),没有很好地突出积分梯度能比朴素梯度更有效的本质原因。本文试图用自己的思路介绍一下积分梯度方法。
4
Jul
线性Attention的探索:Attention必须有个Softmax吗?
By 苏剑林 | 2020-07-04 | 218475位读者 | 引用众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是$\mathcal{O}(n^2)$级别的,$n$是序列长度,所以当$n$比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到$\mathcal{O}(n\log n)$甚至$\mathcal{O}(n)$。
前几天笔者读到了论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,了解到了线性化Attention(Linear Attention)这个探索点,继而阅读了一些相关文献,有一些不错的收获,最后将自己对线性化Attention的理解汇总在此文中。
Attention
当前最流行的Attention机制当属Scaled-Dot Attention,形式为
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\label{eq:std-att}\end{equation}
这里的$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}$,一般场景下都有$n > d$甚至$n\gg d$(BERT base里边$d=64$)。
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 91350位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
19
Jul
通过互信息思想来缓解类别不平衡问题
By 苏剑林 | 2020-07-19 | 154380位读者 | 引用类别不平衡问题,也叫“长尾问题”,是机器学习面临的常见问题之一,尤其是来源于真实场景下的数据集,几乎都是类别不平衡的。大概在两年前,笔者也思考过这个问题,当时正好对“互信息”相关的内容颇有心得,所以构思了一种基于互信息思想的解决办法,但又想了一下,那思路似乎过于平凡,所以就没有深究。然而,前几天在arxiv上刷到Google的一篇文章《Long-tail learning via logit adjustment》,意外地发现里边包含了跟笔者当初的构思几乎一样的方法,这才意识到当初放弃的思路原来还能达到SOTA的水平~于是结合这篇论文,将笔者当初的构思过程整理于此,希望不会被读者嫌弃“马后炮”。
问题描述
这里主要关心的是单标签的多分类问题,假设有$1,2,\cdots,K$共$K$个候选类别,训练数据为$(x,y)\sim\mathcal{D}$,建模的分布为$p_{\theta}(y|x)$,那么我们的优化目标是最大似然,或者说最小化交叉熵,即
\begin{equation}\mathop{\text{argmin}}_{\theta}\,\mathbb{E}_{(x,y)\sim\mathcal{D}}[-\log p_{\theta}(y|x)]\end{equation}
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 53395位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
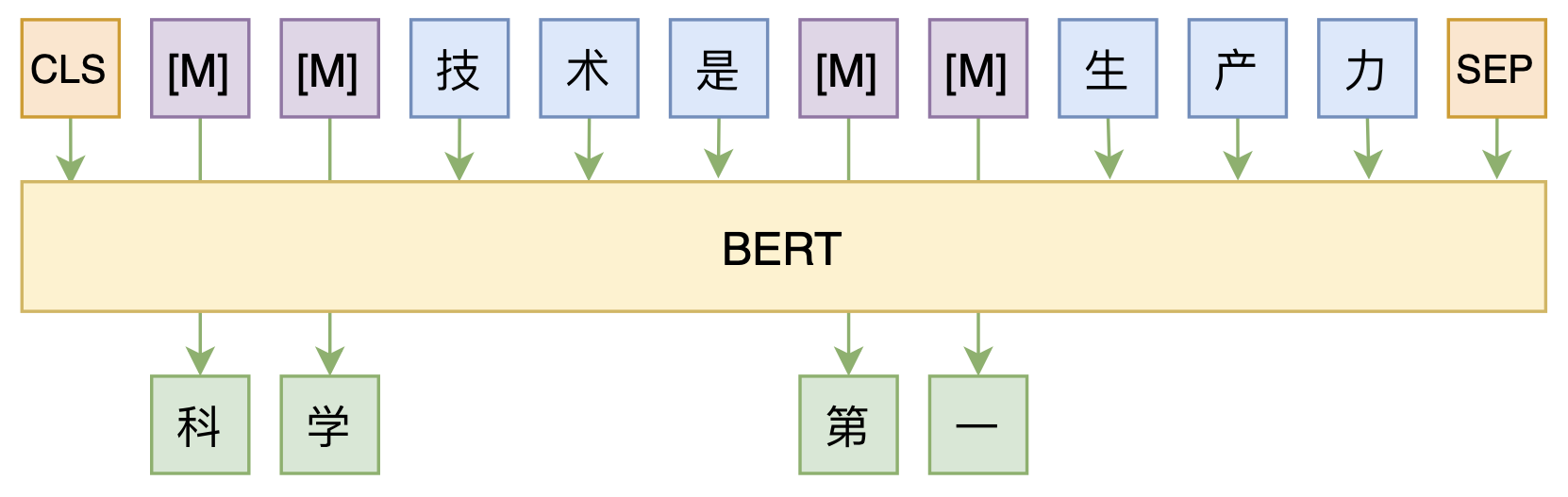
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
14
Aug
L2正则没有想象那么好?可能是“权重尺度偏移”惹的祸
By 苏剑林 | 2020-08-14 | 35727位读者 | 引用L2正则是机器学习常用的一种防止过拟合的方法(应该也是一道经常遇到的面试题)。简单来说,它就是希望权重的模长尽可能小一点,从而能抵御的扰动多一点,最终提高模型的泛化性能。但是读者可能也会发现,L2正则的表现通常没有理论上说的那么好,很多时候加了可能还有负作用。最近的一篇文章《Improve Generalization and Robustness of Neural Networks via Weight Scale Shifting Invariant Regularizations》从“权重尺度偏移”这个角度分析了L2正则的弊端,并提出了新的WEISSI正则项。整个分析过程颇有意思,在这里与大家分享一下。
相关内容
这一节中我们先简单回顾一下L2正则,然后介绍它与权重衰减的联系以及与之相关的AdamW优化器。
L2正则的理解
为什么要添加L2正则?这个问题可能有多个答案。有从Ridge回归角度回答的,有从贝叶斯推断角度回答的,这里给出从扰动敏感性的角度的理解。
27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 151051位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
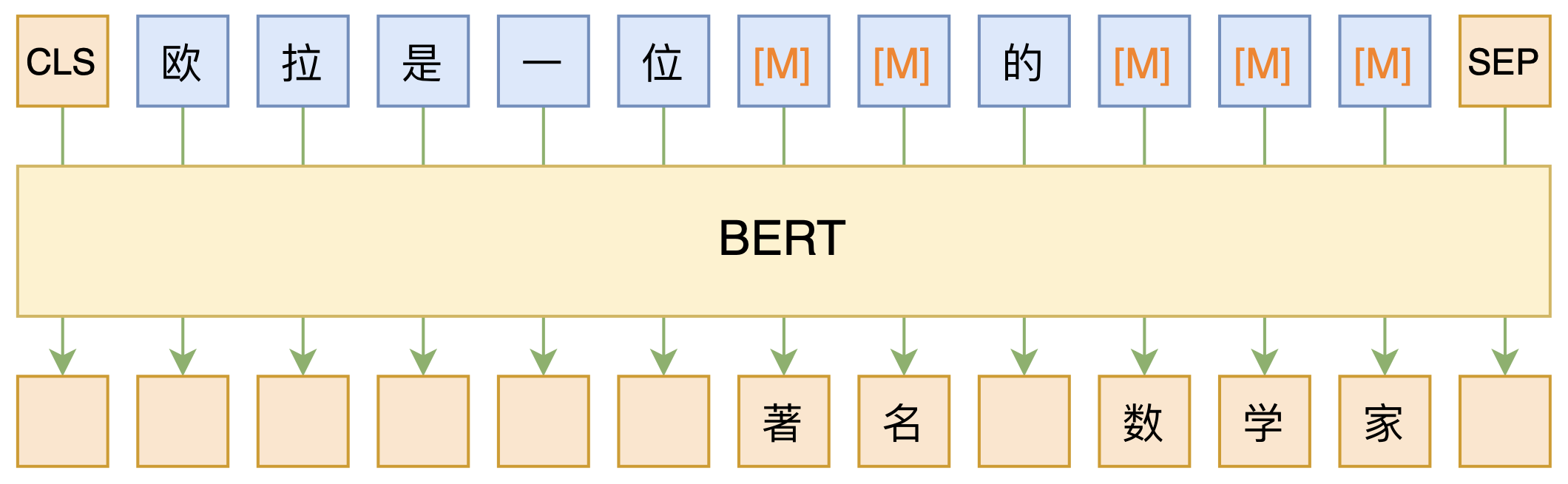
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 67487位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。

最近评论