






7
Feb
视频演示:费曼的茶杯
By 苏剑林 | 2014-02-07 | 19762位读者 | 引用
18
Apr
最小熵原理(一):无监督学习的原理
By 苏剑林 | 2018-04-18 | 91207位读者 | 引用话在开头
在深度学习等端到端方案已经逐步席卷NLP的今天,你是否还愿意去思考自然语言背后的基本原理?我们常说“文本挖掘”,你真的感受到了“挖掘”的味道了吗?
无意中的邂逅
前段时间看了一篇关于无监督句法分析的文章,继而从它的参考文献中发现了论文《Redundancy Reduction as a Strategy for Unsupervised Learning》,这篇论文介绍了如何从去掉空格的英文文章中将英文单词复原。对应到中文,这不就是词库构建吗?于是饶有兴致地细读了一番,发现论文思路清晰、理论完整、结果漂亮,让人赏心悦目。
尽管现在看来,这篇论文的价值不是很大,甚至其结果可能已经被很多人学习过了,但是要注意:这是一篇1993年的论文!在PC机还没有流行的年代,就做出了如此前瞻性的研究。虽然如今深度学习流行,NLP任务越做越复杂,这确实是一大进步,但是我们对NLP原理的真正了解,还不一定超过几十年前的前辈们多少。
这篇论文是通过“去冗余”(Redundancy Reduction)来实现无监督地构建词库的,从信息论的角度来看,“去冗余”就是信息熵的最小化。无监督句法分析那篇文章也指出“信息熵最小化是无监督的NLP的唯一可行的方案”。我进而学习了一些相关资料,并且结合自己的理解思考了一番,发现这个评论确实是耐人寻味。我觉得,不仅仅是NLP,信息熵最小化很可能是所有无监督学习的根本。
10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 246456位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
\begin{equation}L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\label{eq:base}\end{equation}
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现($f(z)$对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于$z$的连续性,它对应不同的形式:
\begin{equation}\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\end{equation}
当然,离散情况下我们更喜欢将记号$z$换成$y$或者$c$。
24
Jun
生成扩散模型漫谈(十九):作为扩散ODE的GAN
By 苏剑林 | 2023-06-24 | 35708位读者 | 引用在文章《生成扩散模型漫谈(十六):W距离 ≤ 得分匹配》中,我们推导了Wasserstein距离与扩散模型得分匹配损失之间的一个不等式,表明扩散模型的优化目标与WGAN的优化目标在某种程度上具有相似性。而在本文,我们将探讨《MonoFlow: Rethinking Divergence GANs via the Perspective of Wasserstein Gradient Flows》中的研究成果,它进一步展示了GAN与扩散模型之间的联系:GAN实际上可以被视为在另一个时间维度上的扩散ODE!
这些发现表明,尽管GAN和扩散模型表面上是两种截然不同的生成式模型,但它们实际上存在许多相似之处,并在许多方面可以相互借鉴和参考。
思路简介
我们知道,GAN所训练的生成器是从噪声$\boldsymbol{z}$到真实样本的一个直接的确定性变换$\boldsymbol{g}_{\boldsymbol{\theta}}(\boldsymbol{z})$,而扩散模型的显著特点是“渐进式生成”,它的生成过程对应于从一系列渐变的分布$p_0(\boldsymbol{x}_0),p_1(\boldsymbol{x}_1),\cdots,p_T(\boldsymbol{x}_T)$中采样(注:在前面十几篇文章中,$\boldsymbol{x}_T$是噪声,$\boldsymbol{x}_0$是目标样本,采样过程是$\boldsymbol{x}_T\to \boldsymbol{x}_0$,但为了便于下面的表述,这里反过来改为$\boldsymbol{x}_0\to \boldsymbol{x}_T$)。看上去确实找不到多少相同之处,那怎么才能将两者联系起来呢?
19
Dec
让炼丹更科学一些(一):SGD的平均损失收敛
By 苏剑林 | 2023-12-19 | 38515位读者 | 引用很多时候我们将深度学习模型的训练过程戏称为“炼丹”,因为整个过程跟古代的炼丹术一样,看上去有一定的科学依据,但整体却给人一种“玄之又玄”的感觉。尽管本站之前也关注过一些优化器相关的工作,甚至也写过《从动力学角度看优化算法》系列,但都是比较表面的介绍,并没有涉及到更深入的理论。为了让以后的炼丹更科学一些,笔者决定去补习一些优化相关的理论结果,争取让炼丹之路多点理论支撑。
在本文中,我们将学习随机梯度下降(SGD)的一个非常基础的收敛结论。虽然现在看来,该结论显得很粗糙且不实用,但它是优化器收敛性证明的一次非常重要的尝试,特别是它考虑了我们实际使用的是随机梯度下降(SGD)而不是全量梯度下降(GD)这一特性,使得结论更加具有参考意义。
问题设置
设损失函数是$L(\boldsymbol{x},\boldsymbol{\theta})$,其实$\boldsymbol{x}$是训练集,而$\boldsymbol{\theta}\in\mathbb{R}^d$是训练参数。受限于算力,我们通常只能执行随机梯度下降(SGD),即每步只能采样一个训练子集来计算损失函数并更新参数,假设采样是独立同分布的,第$t$步采样到的子集为$\boldsymbol{x}_t$,那么我们可以合理地认为实际优化的最终目标是
\begin{equation}L(\boldsymbol{\theta}) = \lim_{T\to\infty}\frac{1}{T}\sum_{t=1}^T L(\boldsymbol{x}_t,\boldsymbol{\theta})\label{eq:loss}\end{equation}
19
Sep
Softmax后传:寻找Top-K的光滑近似
By 苏剑林 | 2024-09-19 | 32103位读者 | 引用Softmax,顾名思义是“soft的max”,是$\max$算子(准确来说是$\text{argmax}$)的光滑近似,它通过指数归一化将任意向量$\boldsymbol{x}\in\mathbb{R}^n$转化为分量非负且和为1的新向量,并允许我们通过温度参数来调节它与$\text{argmax}$(的one hot形式)的近似程度。除了指数归一化外,我们此前在《通向概率分布之路:盘点Softmax及其替代品》也介绍过其他一些能实现相同效果的方案。
我们知道,最大值通常又称Top-1,它的光滑近似方案看起来已经相当成熟,那读者有没有思考过,一般的Top-$k$的光滑近似又是怎么样的呢?下面让我们一起来探讨一下这个问题。
问题描述
设向量$\boldsymbol{x}=(x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$,简单起见我们假设它们两两不相等,即$i\neq j \Leftrightarrow x_i\neq x_j$。记$\Omega_k(\boldsymbol{x})$为$\boldsymbol{x}$最大的$k$个分量的下标集合,即$|\Omega_k(\boldsymbol{x})|=k$以及$\forall i\in \Omega_k(\boldsymbol{x}), j \not\in \Omega_k(\boldsymbol{x})\Rightarrow x_i > x_j$。我们定义Top-$k$算子$\mathcal{T}_k$为$\mathbb{R}^n\mapsto\{0,1\}^n$的映射:
\begin{equation}
[\mathcal{T}_k(\boldsymbol{x})]_i = \left\{\begin{aligned}1,\,\, i\in \Omega_k(\boldsymbol{x}) \\ 0,\,\, i \not\in \Omega_k(\boldsymbol{x})\end{aligned}\right.
\end{equation}
说白了,如果$x_i$属于最大的$k$个元素之一,那么对应的位置变成1,否则变成0,最终结果是一个Multi-Hot向量,比如$\mathcal{T}_2([3,2,1,4]) = [1,0,0,1]$。
22
Nov
生成扩散模型漫谈(二十六):基于恒等式的蒸馏(下)
By 苏剑林 | 2024-11-22 | 24345位读者 | 引用继续回到我们的扩散系列。在《生成扩散模型漫谈(二十五):基于恒等式的蒸馏(上)》中,我们介绍了SiD(Score identity Distillation),这是一种不需要真实数据、也不需要从教师模型采样的扩散模型蒸馏方案,其形式类似GAN,但有着比GAN更好的训练稳定性。
SiD的核心是通过恒等变换来为学生模型构建更好的损失函数,这一点是开创性的,同时也遗留了一些问题。比如,SiD对损失函数的恒等变换是不完全的,如果完全变换会如何?如何从理论上解释SiD引入的$\lambda$的必要性?上个月放出的《Flow Generator Matching》(简称FGM)成功从更本质的梯度角度解释了$\lambda=0.5$的选择,而受到FGM启发,笔者则进一步发现了$\lambda = 1$的一种解释。
接下来我们将详细介绍SiD的上述理论进展。
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 25077位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
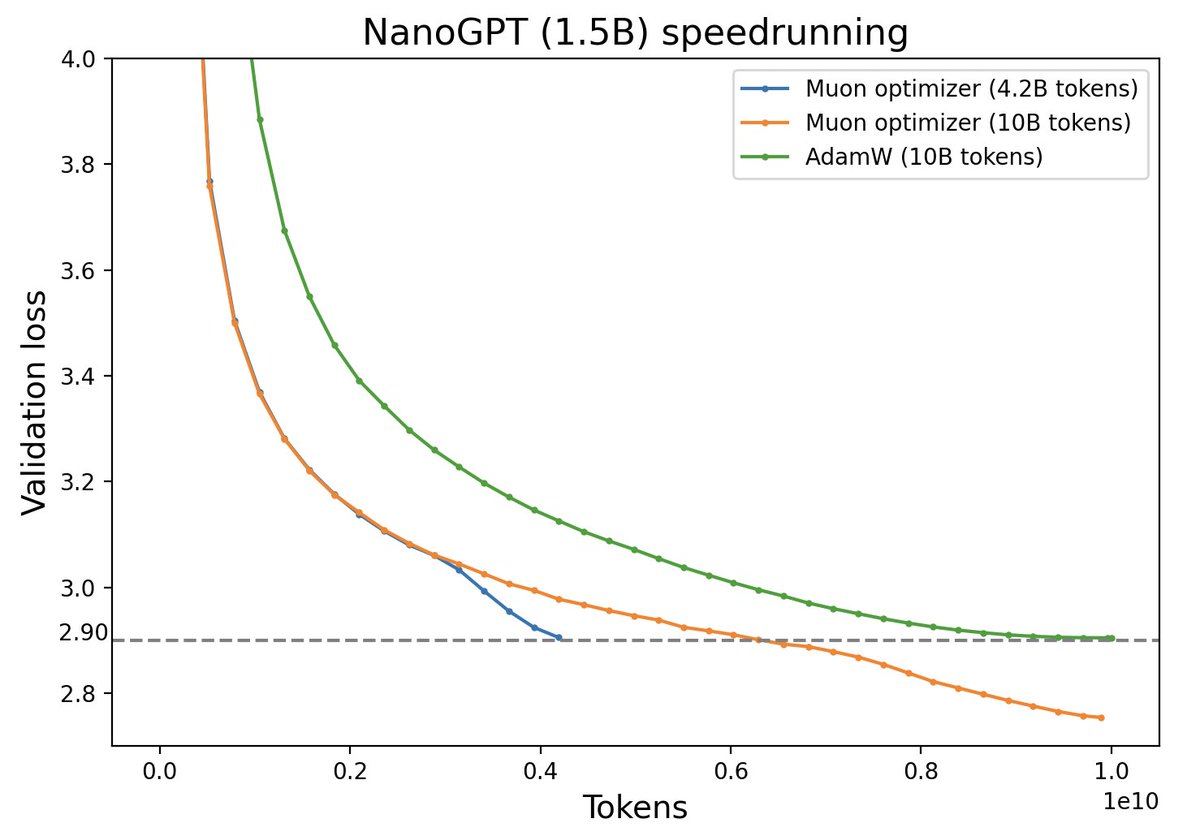
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)

最近评论