






29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 76813位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
1
Jul
又是Dropout两次!这次它做到了有监督任务的SOTA
By 苏剑林 | 2021-07-01 | 219129位读者 | 引用关注NLP新进展的读者,想必对四月份发布的SimCSE印象颇深,它通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。无独有偶,最近的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。此外,笔者在自己的实验还发现,它在半监督任务上也能有不俗的表现。
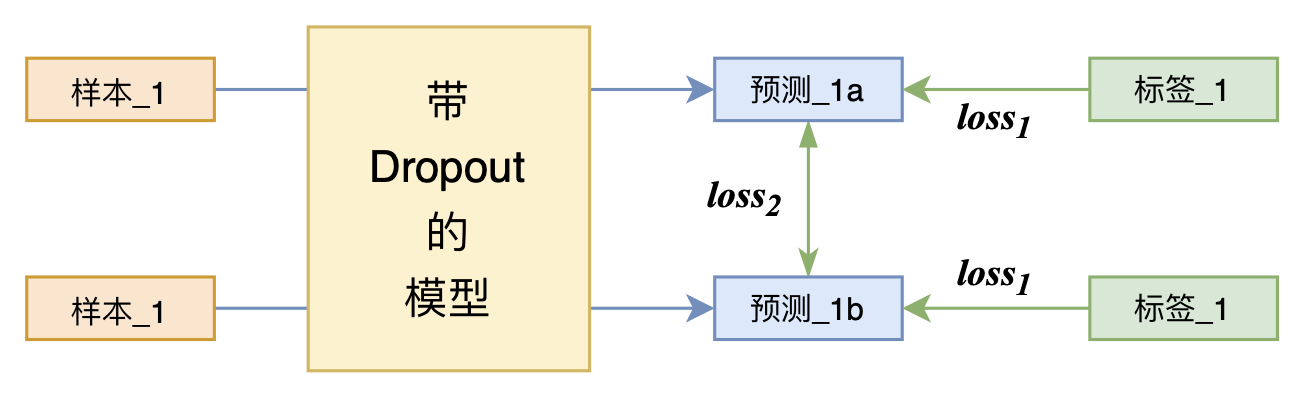
R-Drop示意图
小小的“Dropout两次”,居然跑出了“五项全能”的感觉,不得不令人惊讶。本文来介绍一下R-Drop,并分享一下笔者对它背后原理的思考。
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 67608位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。
8
Jul
网站本次改版感悟...
By 苏剑林 | 2009-07-08 | 41274位读者 | 引用
14
Jul
2009.7.22日全食各地区模拟(Flash)
By 苏剑林 | 2009-07-14 | 17961位读者 | 引用
12
Sep
欢迎注册@spaces.ac.cn的邮箱(更新!)
By 苏剑林 | 2009-09-12 | 772783位读者 | 引用注:目前QQ域名邮箱已经不允许新增新账号,因此暂停申请。(2020年02月17日)
简介
科学空间与腾讯公司联合推出以@spaces.ac.cn为后缀的QQ邮箱,欢迎QQ用户申请注册。
腾讯公司可以说越来越强大了,之前已经提供了即时通讯软件(QQ)、电子邮箱、个人空间等让人喜爱的功能,现在还提供了个性化域名邮箱服务,只要有域名,就可以使用自己域名的邮箱了,而这个邮箱空间就是你现在的QQ邮箱,这个功能跟Google和微软提供的功能差不多,不过在中国,微软的邮箱慢得出奇,Google不支持Com,Net和Org以外的域名,所以还是QQ Mail好。本站已经使用了域名spaces.ac.cn开通了这个个性邮箱服务。
30
Aug
上学了,更新放缓......
By 苏剑林 | 2009-08-30 | 16300位读者 | 引用
19
Sep

最近评论