






20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 79155位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
28
Apr
在bert4keras中使用混合精度和XLA加速训练
By 苏剑林 | 2022-04-28 | 30836位读者 | 引用之前笔者一直都是聚焦于模型的构思和实现,鲜有关注模型的训练加速,像混合精度和XLA这些技术,虽然也有听过,但没真正去实践过。这两天折腾了一番,成功在bert4keras中使用了混合精度和XLA来加速训练,在此做个简单的总结,供大家参考。
本文的多数经验结论并不只限于bert4keras中使用,之所以在标题中强调bert4keras,只不过bert4keras中的模型实现相对较为规整,因此启动这些加速技巧所要做的修改相对更少。
实验环境
本文的实验显卡为3090,使用的docker镜像为nvcr.io/nvidia/tensorflow:21.09-tf1-py3,其中自带的tensorflow版本为1.15.5。另外,实验所用的bert4keras版本为0.11.3。其他环境也可以参考着弄,要注意有折腾精神,不要指望着无脑调用。
顺便提一下,3090、A100等卡只能用cuda11,而tensorflow官网的1.15版本是不支持cuda11的,如果还想用tensorflow 1.x,那么只能用nvidia亲自维护的nvidia-tensorflow,或者用其构建的docker镜像。用nvidia而不是google维护的tensorflow,除了能让你在最新的显卡用上1.x版本外,还有nvidia专门做的一些额外优化,具体文档可以参考这里。
6
Aug
【不可思议的Word2Vec】6. Keras版的Word2Vec
By 苏剑林 | 2017-08-06 | 153196位读者 | 引用前言
看过我之前写的TF版的Word2Vec后,Keras群里的Yin神问我有没有Keras版的。事实上在做TF版之前,我就写过Keras版的,不过没有保留,所以重写了一遍,更高效率,代码也更好看了。纯Keras代码实现Word2Vec,原理跟《【不可思议的Word2Vec】5. Tensorflow版的Word2Vec》是一样的,现在放出来,我想,会有人需要的。(比如,自己往里边加一些额外输入,然后做更好的词向量模型?)
由于Keras同时支持tensorflow、theano、cntk等多个后端,这就等价于实现了多个框架的Word2Vec了。嗯,这样想就高大上了,哈哈~
代码
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 475020位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 361050位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
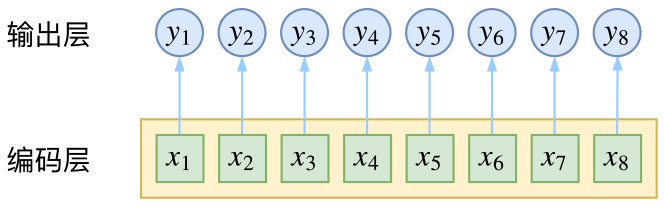
逐帧softmax并没有直接考虑输出的上下文关联
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 285999位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
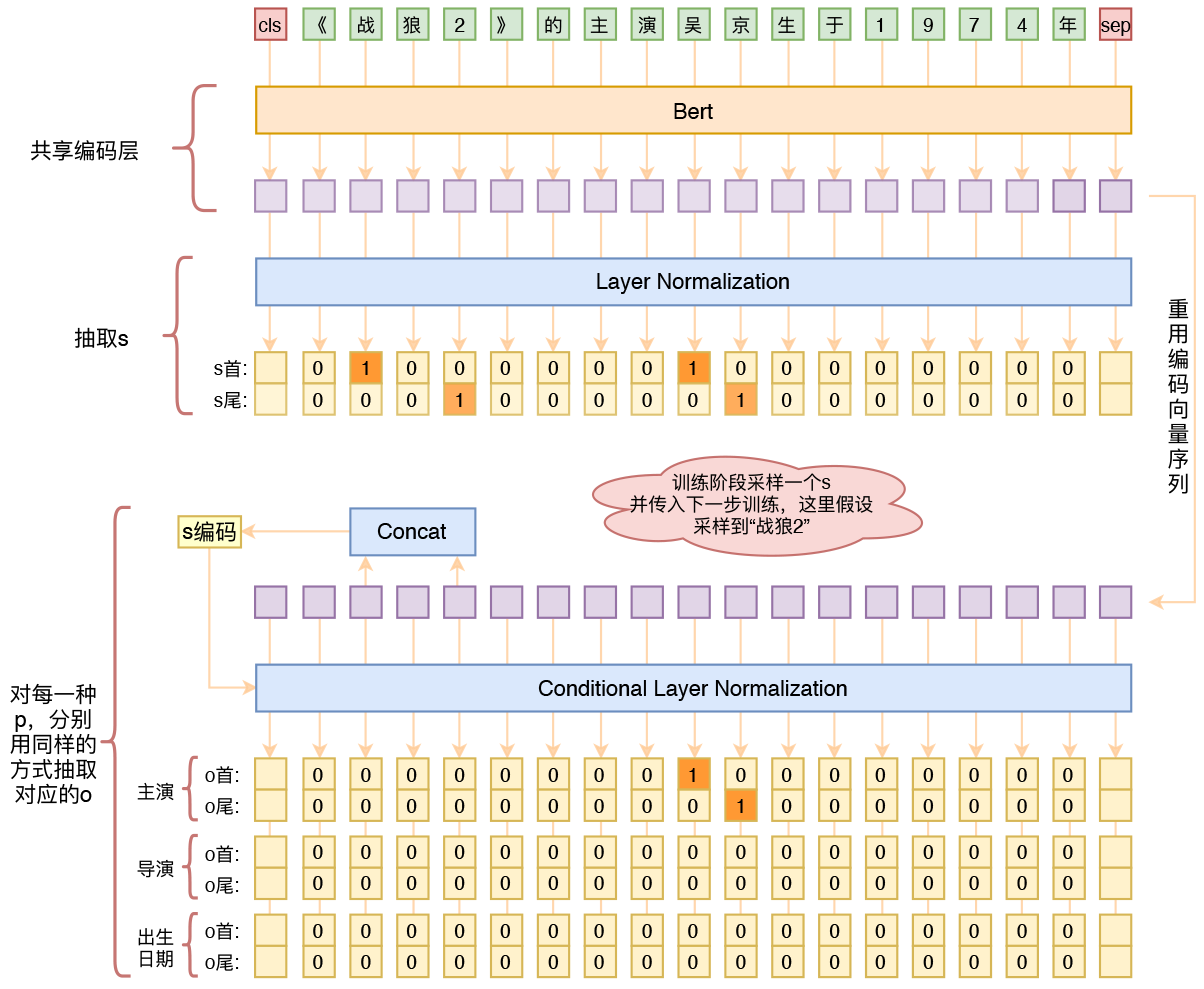
基于Bert的三元组抽取模型结构示意图
2
Apr
bert4keras在手,baseline我有:百度LIC2020
By 苏剑林 | 2020-04-02 | 103159位读者 | 引用百度的“2020语言与智能技术竞赛”开赛了,今年有五个赛道,分别是机器阅读理解、推荐任务对话、语义解析、关系抽取、事件抽取。每个赛道中,主办方都给出了基于PaddlePaddle的baseline模型,这里笔者也基于bert4keras给出其中三个赛道的个人baseline,从中我们可以看到用bert4keras搭建baseline模型的方便快捷与简练。
思路简析
这里简单分析一下这三个赛道的任务特点以及对应的baseline设计。
27
Aug
自己实现了一个bert4keras
By 苏剑林 | 2019-08-27 | 193465位读者 | 引用分享个人实现的bert4keras:
关于站长
智能搜索
支持整句搜索!网站自动使用结巴分词进行分词,并结合ngrams排序算法给出合理的搜索结果。

最近评论