






17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 73227位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
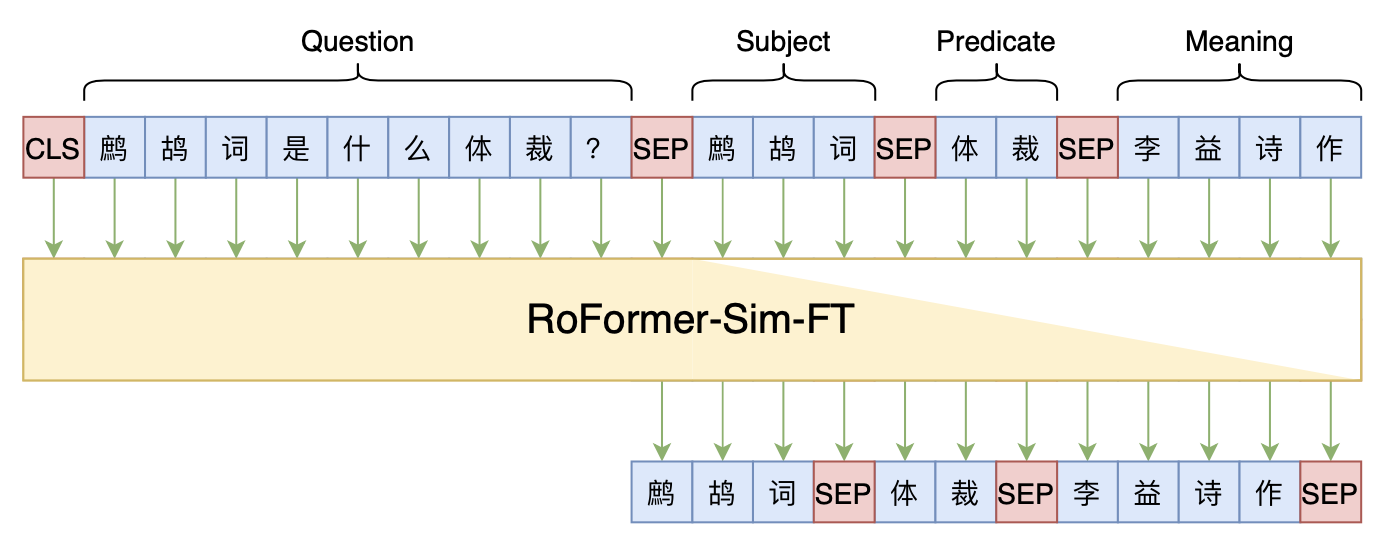
本文baseline模型示意图
30
Jan
GPLinker:基于GlobalPointer的实体关系联合抽取
By 苏剑林 | 2022-01-30 | 134842位读者 | 引用在将近三年前的百度“2019语言与智能技术竞赛”(下称LIC2019)中,笔者提出了一个新的关系抽取模型(参考《基于DGCNN和概率图的轻量级信息抽取模型》),后被进一步发表和命名为“CasRel”,算是当时关系抽取的SOTA。然而,CasRel提出时笔者其实也是首次接触该领域,所以现在看来CasRel仍有诸多不完善之处,笔者后面也有想过要进一步完善它,但也没想到特别好的设计。
后来,笔者提出了GlobalPointer以及近日的Efficient GlobalPointer,感觉有足够的“材料”来构建新的关系抽取模型了。于是笔者从概率图思想出发,参考了CasRel之后的一些SOTA设计,最终得到了一版类似TPLinker的模型。
基础思路
关系抽取乍看之下是三元组$(s,p,o)$(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”$(s_h,s_t,p,o_h,o_t)$的抽取,其中$s_h,s_t$分别是$s$的首、尾位置,而$o_h,o_t$则分别是$o$的首、尾位置。
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 68261位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 155908位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
\begin{equation}\text{编码:}\,\,x\to z\,,\quad \text{生成:}\,\,z\to x\end{equation}
27
Jul
生成扩散模型漫谈(四):DDIM = 高观点DDPM
By 苏剑林 | 2022-07-27 | 267623位读者 | 引用相信很多读者都听说过甚至读过克莱因的《高观点下的初等数学》这套书,顾名思义,这是在学到了更深入、更完备的数学知识后,从更高的视角重新审视过往学过的初等数学,以得到更全面的认知,甚至达到温故而知新的效果。类似的书籍还有很多,比如《重温微积分》、《复分析:可视化方法》等。
回到扩散模型,目前我们已经通过三篇文章从不同视角去解读了DDPM,那么它是否也存在一个更高的理解视角,让我们能从中得到新的收获呢?当然有,《Denoising Diffusion Implicit Models》介绍的DDIM模型就是经典的案例,本文一起来欣赏它。
思路分析
在《生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪》中,我们提到过该文章所介绍的推导跟DDIM紧密相关。具体来说,文章的推导路线可以简单归纳如下:
\begin{equation}p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{推导}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{推导}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\xrightarrow{\text{近似}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)\end{equation}
28
Mar
Google新作试图“复活”RNN:RNN能否再次辉煌?
By 苏剑林 | 2023-03-28 | 67929位读者 | 引用当前,像ChatGPT之类的LLM可谓是“风靡全球”。有读者留意到,几乎所有LLM都还是用最初的Multi-Head Scaled-Dot Attention,近年来大量的Efficient工作如线性Attention、FLASH等均未被采用。是它们版本效果太差,还是根本没有必要考虑效率?其实答案笔者在《线性Transformer应该不是你要等的那个模型》已经分析过了,只有序列长度明显超过hidden size时,标准Attention才呈现出二次复杂度,在此之前它还是接近线性的,它的速度比很多Efficient改进都快,而像GPT3用到了上万的hidden size,这意味着只要你的LLM不是面向数万长度的文本生成,那么用Efficient改进是没有必要的,很多时候速度没提上去,效果还降低了。
那么,真有数万甚至数十万长度的序列处理需求时,我们又该用什么模型呢?近日,Google的一篇论文《Resurrecting Recurrent Neural Networks for Long Sequences》重新优化了RNN模型,特别指出了RNN在处理超长序列场景下的优势。那么,RNN能否再次辉煌?
28
Aug
Lion/Tiger优化器训练下的Embedding异常和对策
By 苏剑林 | 2023-08-28 | 37242位读者 | 引用打从在《Tiger:一个“抠”到极致的优化器》提出了Tiger优化器之后,Tiger就一直成为了我训练模型的“标配”优化器。最近笔者已经尝试将Tiger用到了70亿参数模型的预训练之中,前期效果看上来尚可,初步说明Tiger也是能Scale Up的。不过,在查看训练好的模型权重时,笔者发现Embedding出现了一些异常值,有些Embedding的分量达到了$\pm 100$的级别。
经过分析,笔者发现类似现象并不会在Adam中出现,这是Tiger或者Lion这种带符号函数$\text{sign}$的优化器特有的问题,对此文末提供了两种参考解决方案。本文将记录笔者的分析过程,供大家参考。
现象
接下来,我们的分析都以Tiger优化器为例,但分析过程和结论同样适用于Lion。
14
Feb
生成扩散模型漫谈(二十九):用DDPM来离散编码
By 苏剑林 | 2025-02-14 | 22488位读者 | 引用笔者前两天在arXiv刷到了一篇新论文《Compressed Image Generation with Denoising Diffusion Codebook Models》,实在为作者的天马行空所叹服,忍不住来跟大家分享一番。
如本文标题所述,作者提出了一个叫DDCM(Denoising Diffusion Codebook Models)的脑洞,它把DDPM的噪声采样限制在一个有限的集合上,然后就可以实现一些很奇妙的效果,比如像VQVAE一样将样本编码为离散的ID序列并重构回来。注意这些操作都是在预训练好的DDPM上进行的,无需额外的训练。
有限集合
由于DDCM只需要用到一个预训练好的DDPM模型来执行采样,所以这里我们就不重复介绍DDPM的模型细节了,对DDPM还不大了解的读者可以回顾我们《生成扩散模型漫谈》系列的(一)、(二)、(三)篇。

最近评论