






11
Aug
细水长flow之NICE:流模型的基本概念与实现
By 苏剑林 | 2018-08-11 | 213911位读者 | 引用前言:自从在机器之心上看到了glow模型之后(请看《下一个GAN?OpenAI提出可逆生成模型Glow》),我就一直对其念念不忘。现在机器学习模型层出不穷,我也经常关注一些新模型动态,但很少像glow模型那样让我怦然心动,有种“就是它了”的感觉。更意外的是,这个效果看起来如此好的模型,居然是我以前完全没有听说过的。于是我翻来覆去阅读了好几天,越读越觉得有意思,感觉通过它能将我之前的很多想法都关联起来。在此,先来个阶段总结。
背景
本文主要是《NICE: Non-linear Independent Components Estimation》一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。
艰难的分布
众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。

glow模型生成的高清人脸
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 241941位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 90204位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
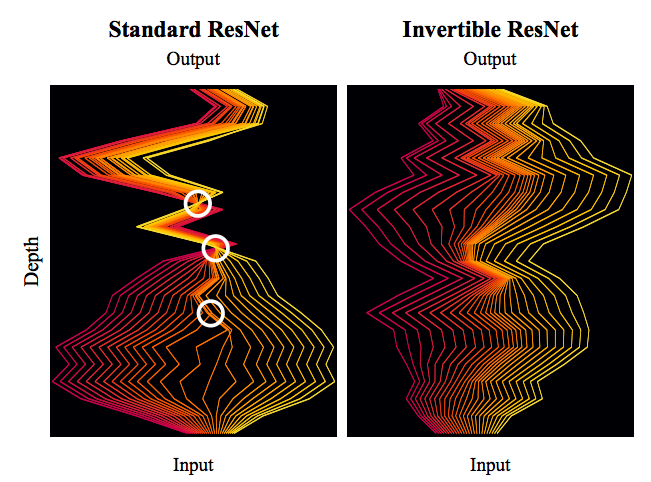
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
21
Sep
细水长flow之f-VAEs:Glow与VAEs的联姻
By 苏剑林 | 2018-09-21 | 112136位读者 | 引用这篇文章是我们前几天挂到arxiv上的论文的中文版。在这篇论文中,我们给出了结合流模型(如前面介绍的Glow)和变分自编码器的一种思路,称之为f-VAEs。理论可以证明f-VAEs是囊括流模型和变分自编码器的更一般的框架,而实验表明相比于原始的Glow模型,f-VAEs收敛更快,并且能在更小的网络规模下达到同样的生成效果。
原文地址:《f-VAEs: Improve VAEs with Conditional Flows》
近来,生成模型得到了广泛关注,其中变分自编码器(VAEs)和流模型是不同于生成对抗网络(GANs)的两种生成模型,它们亦得到了广泛研究。然而它们各有自身的优势和缺点,本文试图将它们结合起来。

由f-VAEs实现的两个真实样本之间的线性插值
基础
设给定数据集的证据分布为$\tilde{p}(x)$,生成模型的基本思路是希望用如下的分布形式来拟合给定数据集分布
$$\begin{equation}q(x)=\int q(z)q(x|z) dz\end{equation}$$
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 154070位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 106939位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
28
Sep
生成扩散模型漫谈(十二):“硬刚”扩散ODE
By 苏剑林 | 2022-09-28 | 42973位读者 | 引用在《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们从SDE的角度理解了生成扩散模型,然后在《生成扩散模型漫谈(六):一般框架之ODE篇》中,我们知道SDE对应的扩散模型中,实际上隐含了一个ODE模型。无独有偶,在《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中我们也知道原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE。
细想上述过程,可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。
微分方程
像GAN这样的生成模型,它本质上是希望找到一个确定性变换,能将从简单分布(如标准正态分布)采样出来的随机变量,变换为特定数据分布的样本。flow模型也是生成模型之一,它的思路是反过来,先找到一个能将数据分布变换简单分布的可逆变换,再求解相应的逆变换来得到一个生成模型。
27
May
【不可思议的Word2Vec】5. Tensorflow版的Word2Vec
By 苏剑林 | 2017-05-27 | 94839位读者 | 引用本文封装了一个比较完整的Word2Vec,其模型部分使用tensorflow实现。本文的目的并非只是再造一次Word2Vec这个轮子,而是通过这个例子来熟悉tensorflow的写法,并且测试笔者设计的一种新的softmax loss的效果,为后面研究语言模型的工作做准备。
不同的地方
Word2Vec的基本的数学原理,请移步到《【不可思议的Word2Vec】 1.数学原理》一文查看。本文的主要模型还是CBOW或者Skip-Gram,但在loss设计上有所不同。本文还是使用了完整的softmax结构,而不是huffmax softmax或者负采样方案,但是在训练softmax时,使用了基于随机负采样的交叉熵作为loss。这种loss与已有的nce_loss和sampled_softmax_loss都不一样,这里姑且命名为random softmax loss。
另外,在softmax结构中,一般是$\text{softmax}(Wx+b)$这样的形式,考虑到$W$矩阵的形状事实上跟词向量矩阵的形状是一样的,因此本文考虑了softmax层与词向量层共享权重的模型(这时候直接让$b$为0),这种模型等效于原有的Word2Vec的负采样方案,也类似于glove词向量的词共现矩阵分解,但由于使用了交叉熵损失,理论上收敛更快,而且训练结果依然具有softmax的预测概率意义(相比之下,已有的Word2Vec负样本模型训练完之后,最后模型的输出值是没有意义的,只有词向量是有意义的。)。同时,由于共享了参数,因此词向量的更新更为充分,读者不妨多多测试这种方案。

最近评论