






17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 69714位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
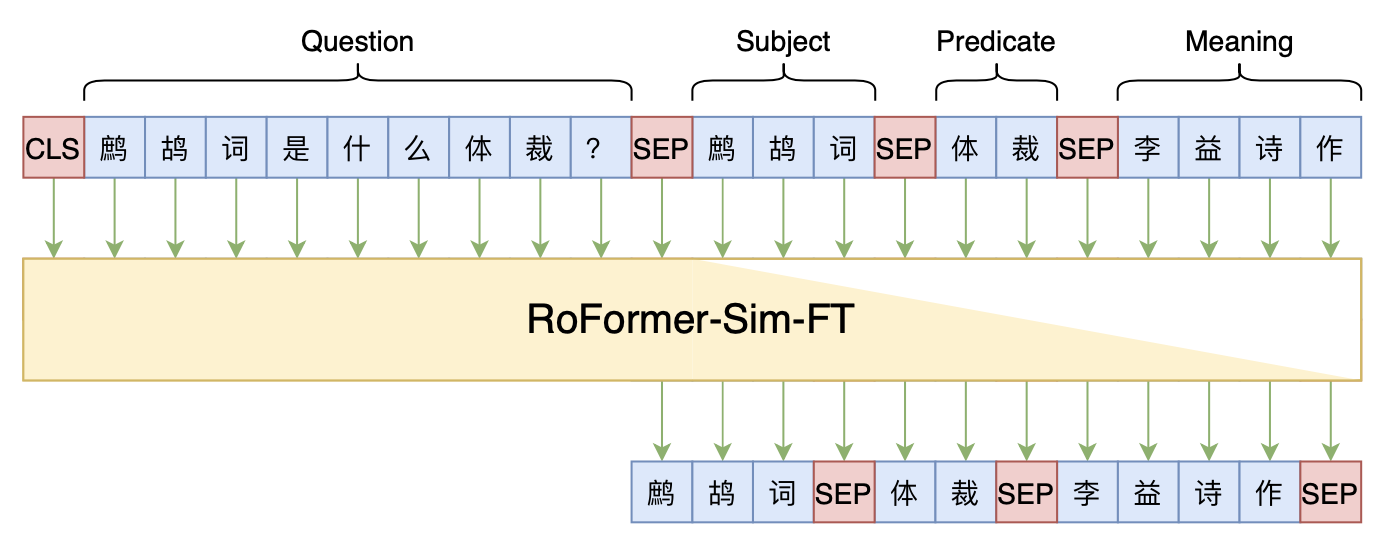
本文baseline模型示意图
18
Jan
多任务学习漫谈(一):以损失之名
By 苏剑林 | 2022-01-18 | 165153位读者 | 引用能提升模型性能的方法有很多,多任务学习(Multi-Task Learning)也是其中一种。简单来说,多任务学习是希望将多个相关的任务共同训练,希望不同任务之间能够相互补充和促进,从而获得单任务上更好的效果(准确率、鲁棒性等)。然而,多任务学习并不是所有任务堆起来就能生效那么简单,如何平衡每个任务的训练,使得各个任务都尽量获得有益的提升,依然是值得研究的课题。
最近,笔者机缘巧合之下,也进行了一些多任务学习的尝试,借机也学习了相关内容,在此挑部分结果与大家交流和讨论。
加权求和
从损失函数的层面看,多任务学习就是有多个损失函数$\mathcal{L}_1,\mathcal{L}_2,\cdots,\mathcal{L}_n$,一般情况下它们有大量的共享参数、少量的独立参数,而我们的目标是让每个损失函数都尽可能地小。为此,我们引入权重$\alpha_1,\alpha_2,\cdots,\alpha_n\geq 0$,通过加权求和的方式将它转化为如下损失函数的单任务学习
\begin{equation}\mathcal{L} = \sum_{i=1}^n \alpha_i \mathcal{L}_i\label{eq:w-loss}\end{equation}
在这个视角下,多任务学习的主要难点就是如何确定各个$\alpha_i$了。
14
Feb
多任务学习漫谈(三):分主次之序
By 苏剑林 | 2022-02-14 | 37854位读者 | 引用多任务学习是一个很宽泛的命题,不同场景下多任务学习的目标不尽相同。在《多任务学习漫谈(一):以损失之名》和《多任务学习漫谈(二):行梯度之事》中,我们将多任务学习的目标理解为“做好每一个任务”,具体表现是“尽量平等地处理每一个任务”,我们可以称之为“平行型多任务学习”。然而,并不是所有多任务学习的目标都是如此,在很多场景下,我们主要还是想学好某一个主任务,其余任务都只是辅助,希望通过增加其他任务的学习来提升主任务的效果罢了,此类场景我们可以称为“主次型多任务学习”。
在这个背景下,如果还是沿用平行型多任务学习的“做好每一个任务”的学习方案,那么就可能会明显降低主任务的效果了。所以本文继续沿着“行梯度之事”的想法,探索主次型多任务学习的训练方案。
目标形式
在这篇文章中,我们假设读者已经阅读并且基本理解《多任务学习漫谈(二):行梯度之事》里边的思想和方法,那么在梯度视角下,让某个损失函数保持下降的必要条件是更新量与其梯度夹角至少大于90度,这是贯穿全文的设计思想。
25
May
从重参数的角度看离散概率分布的构建
By 苏剑林 | 2022-05-25 | 17778位读者 | 引用一般来说,神经网络的输出都是无约束的,也就是值域为$\mathbb{R}$,而为了得到有约束的输出,通常是采用加激活函数的方式。例如,如果我们想要输出一个概率分布来代表每个类别的概率,那么通常在最后加上Softmax作为激活函数。那么一个紧接着的疑问就是:除了Softmax,还有什么别的操作能生成一个概率分布吗?
在《漫谈重参数:从正态分布到Gumbel Softmax》中,我们介绍了Softmax的重参数操作,本文将这个过程反过来,即先定义重参数操作,然后去反推对应的概率分布,从而得到一个理解概率分布构建的新视角。
问题定义
假设模型的输出向量为$\boldsymbol{\mu}=[\mu_1,\cdots,\mu_n]\in\mathbb{R}^n$,不失一般性,这里假设$\mu_i$两两不等。我们希望通过某个变换$\mathcal{T}$将$\boldsymbol{\mu}$转换为$n$元概率分布$\boldsymbol{p}=[p_1,\cdots,p_n]$,并保持一定的性质。比如,最基本的要求是:
\begin{equation}{\color{red}1.}\,p_i\geq 0 \qquad {\color{red}2.}\,\sum_i p_i = 1 \qquad {\color{red}3.}\,p_i \geq p_j \Leftrightarrow \mu_i \geq \mu_j\end{equation}
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 42570位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
25
Oct
圆内随机n点在同一个圆心角为θ的扇形的概率
By 苏剑林 | 2022-10-25 | 41403位读者 | 引用
17
Apr
梯度视角下的LoRA:简介、分析、猜测及推广
By 苏剑林 | 2023-04-17 | 82077位读者 | 引用随着ChatGPT及其平替的火热,各种参数高效(Parameter-Efficient)的微调方法也“水涨船高”,其中最流行的方案之一就是本文的主角LoRA了,它出自论文《LoRA: Low-Rank Adaptation of Large Language Models》。LoRA方法上比较简单直接,而且也有不少现成实现,不管是理解还是使用都很容易上手,所以本身也没太多值得细写的地方了。
然而,直接实现LoRA需要修改网络结构,这略微麻烦了些,同时LoRA给笔者的感觉是很像之前的优化器AdaFactor,所以笔者的问题是:能否从优化器角度来分析和实现LoRA呢?本文就围绕此主题展开讨论。
方法简介
以往的一些结果(比如《Exploring Aniversal Intrinsic Task Subspace via Prompt Tuning》)显示,尽管预训练模型的参数量很大,但每个下游任务对应的本征维度(Intrinsic Dimension)并不大,换句话说,理论上我们可以微调非常小的参数量,就能在下游任务取得不错的效果。
LoRA借鉴了上述结果,提出对于预训练的参数矩阵$W_0\in\mathbb{R}^{n\times m}$,我们不去直接微调$W_0$,而是对增量做低秩分解假设:
\begin{equation}W = W_0 + A B,\qquad A\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m}\end{equation}
14
Mar
缓解交叉熵过度自信的一个简明方案
By 苏剑林 | 2023-03-14 | 36269位读者 | 引用众所周知,分类问题的常规评估指标是正确率,而标准的损失函数则是交叉熵,交叉熵有着收敛快的优点,但它并非是正确率的光滑近似,这就带来了训练和预测的不一致性问题。另一方面,当训练样本的预测概率很低时,交叉熵会给出一个非常巨大的损失(趋于$-\log 0^{+}=\infty$),这意味着交叉熵会特别关注预测概率低的样本——哪怕这个样本可能是“脏数据”。所以,交叉熵训练出来的模型往往有过度自信现象,即每个样本都给出较高的预测概率,这会带来两个副作用:一是对脏数据的过度拟合带来的效果下降,二是预测的概率值无法作为不确定性的良好指标。
围绕交叉熵的改进,学术界一直都有持续输出,目前这方面的研究仍处于“八仙过海,各显神通”的状态,没有标准答案。在这篇文章中,我们来学习一下论文《Tailoring Language Generation Models under Total Variation Distance》给出的该问题的又一种简明的候选方案。

最近评论