






27
Jan
“让Keras更酷一些!”:随意的输出和灵活的归一化
By 苏剑林 | 2019-01-27 | 107804位读者 | 引用继续“让Keras更酷一些!”系列,让Keras来得更有趣些吧~
这次围绕着Keras的loss、metric、权重和进度条进行展开。
可以不要输出
一般我们用Keras定义一个模型,是这样子的:
x_in = Input(shape=(784,))
x = x_in
x = Dense(100, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='categorical_crossentropy ',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
13
Nov
n维空间下两个随机向量的夹角分布
By 苏剑林 | 2019-11-13 | 149516位读者 | 引用昨天群里大家讨论到了$n$维向量的一些反直觉现象,其中一个话题是“一般$n$维空间下两个随机向量几乎都是垂直的”,这就跟二维/三维空间的认知有明显出入了。要从理论上认识这个结论,我们可以考虑两个随机向量的夹角$\theta$分布,并算算它的均值方差。
概率密度
首先,我们来推导$\theta$的概率密度函数。呃,其实也不用怎么推导,它是$n$维超球坐标的一个直接结论。
要求两个随机向量之间的夹角分布,很显然,由于各向同性,所以我们只需要考虑单位向量,而同样是因为各向同性,我们只需要固定其中一个向量,考虑另一个向量随机变化。不是一般性,考虑随机向量为
\begin{equation}\boldsymbol{x}=(x_1,x_2,\dots,x_n)\end{equation}
而固定向量为
\begin{equation}\boldsymbol{y}=(1,0,\dots,0)\end{equation}
1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 103445位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如$L_1, L_2$惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为$f(x)$,$\mathcal{D}$为训练数据集合,$l(f(x), y)$为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
$\theta$是$f(x)$里边的可训练参数。假如往模型输入添加噪声$\varepsilon$,其分布为$q(\varepsilon)$,那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重$\theta$,甚至可以是输出$y$(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,$q(\varepsilon)$的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布$U([0,1])$或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
1
Dec
Performer:用随机投影将Attention的复杂度线性化
By 苏剑林 | 2020-12-01 | 88819位读者 | 引用Attention机制的$\mathcal{O}(n^2)$复杂度是一个老大难问题了,改变这一复杂度的思路主要有两种:一是走稀疏化的思路,比如我们以往介绍过的Sparse Attention以及Google前几个月搞出来的Big Bird,等等;二是走线性化的思路,这部分工作我们之前总结在《线性Attention的探索:Attention必须有个Softmax吗?》中,读者可以翻看一下。本文则介绍一项新的改进工作Performer,出自Google的文章《Rethinking Attention with Performers》,它的目标相当霸气:通过随机投影,在不损失精度的情况下,将Attention的复杂度线性化。
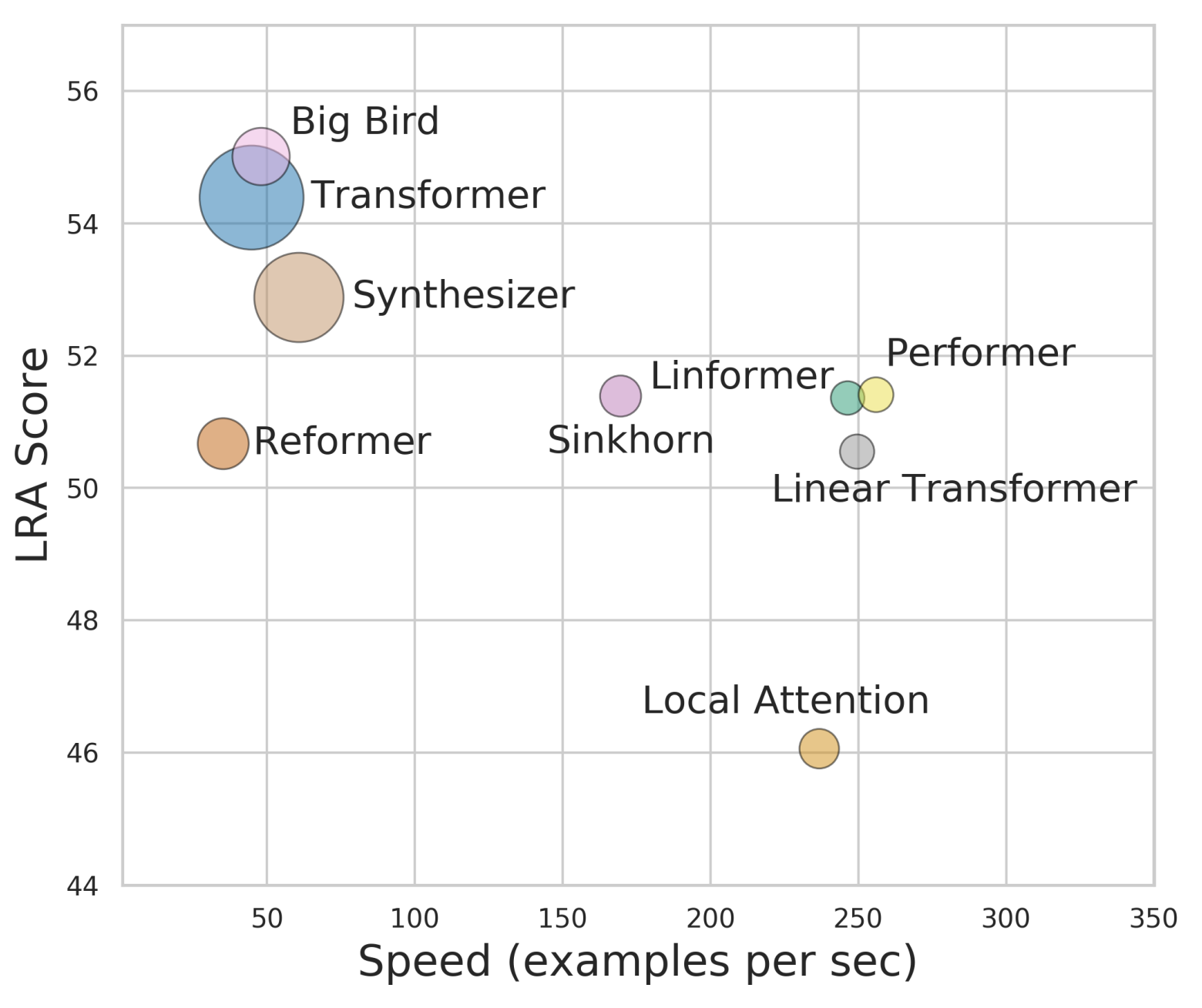
各个Transformer模型的“效果-速度-显存”图,纵轴是效果,横轴是速度,圆圈的大小代表所需要的显存。理论上来说,越靠近右上方的模型越好,圆圈越小的模型越好
说直接点,就是理想情况下我们可以不用重新训练模型,输出结果也不会有明显变化,但是复杂度降到了$\mathcal{O}(n)$!看起来真的是“天上掉馅饼”般的改进了,真的有这么美好吗?
25
Oct
圆内随机n点在同一个圆心角为θ的扇形的概率
By 苏剑林 | 2022-10-25 | 41537位读者 | 引用
16
Sep
随机分词浅探:从Viterbi Decoding到Viterbi Sampling
By 苏剑林 | 2023-09-16 | 22508位读者 | 引用上一篇文章《大词表语言模型在续写任务上的一个问题及对策》发布后,很快就有读者指出可以在训练阶段引入带有随机性的分词结果来解决同样的问题,并且已经有论文和实现。经过进一步查阅学习,笔者发现这是一个名为Subword Regularization的技巧,最早应用在NMT(机器翻译)中,目前SentencePiece也有相应的实现。看起来这个技巧确实能缓解前述问题,甚至有助于增强语言模型的容错能力,所以就有了将它加进去BytePiece的想法。
那么问题来了,如何将确定性分词改为随机性分词呢?BytePiece是基于Unigram模型的,它通过Viterbi算法找最大概率的分词方案,既然有概率,是否就可以自然地导出随机采样?本文来讨论这个问题,并分享自己的解决方案。
14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 34474位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入$n$倍的算力,那么达到同样效果的时间则缩短为$1/n$,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
15
Oct
让MathJax的数学公式随窗口大小自动缩放
By 苏剑林 | 2024-10-15 | 17246位读者 | 引用随着MathJax的出现和流行,在网页上显示数学公式便逐渐有了标准答案。然而,MathJax(包括其竞品KaTeX)只是负责将网页LaTeX代码转化为数学公式,对于自适应分辨率方面依然没有太好的办法。像本站一些数学文章,因为是在PC端排版好的,所以在PC端浏览效果尚可,但转到手机上看就可能有点难以入目了。
经过测试,笔者得到了一个方案,让MathJax的数学公式也能像图片一样,随着窗口大小而自适应缩放,从而尽量保证移动端的显示效果,在此跟大家分享一波。
背景思路
这个问题的起源是,即便在PC端进行排版,有时候也会遇到一些单行公式的长度超出了网页宽度,但又不大好换行的情况,这时候一个解决方案是用HTML代码手动调整一下公式的字体大小,比如
<span style="font-size:90%">
\begin{equation}一个超长的数学公式\end{equation}
</span>
最近评论