






26
Feb
非对抗式生成模型GLANN的简单介绍
By 苏剑林 | 2019-02-26 | 72757位读者 | 引用前段时间看到facebook发表了一个非对抗的生成模型GLANN(去年12月挂在arxiv上),号称用非对抗的方式也能生成1024的高清人脸,于是饶有兴致地阅读了一番,确实有点收获,但也有点失望。至于为啥失望,大家阅读下去就明白了。
原论文:《Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors》
机器之心介绍:《为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN》
效果图:

GLANN效果图
26
Mar
科学空间浏览指南(FAQ)
By 苏剑林 | 2019-03-26 | 141690位读者 | 引用事实上,除了写博客内容,在这几年里,笔者是花了相当一部分时间来做科学空间的“表面功夫”,为此还专门学了一点php、css和js。虽然不敢说精益求精,但总体来说网站的浏览体验应该比前几年要好得多。
考虑到有些读者可能需要的功能,但一时半会未必能留意到,遂来整理一些站内技巧。
文章篇
什么环境阅读文章最佳?
两年前科学空间就已经加入了响应式设计,自动适应不同分辨率的屏幕。因此,不管哪个分辨率的环境应该都能看清文字内容,唯一的问题是,在小屏幕手机下公式可能会显示不全或者错位。为了较好地阅读公式,最好在7寸以上的屏幕上阅读。如果一定要用小屏幕的手机,可以考虑横屏阅读。
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 122875位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
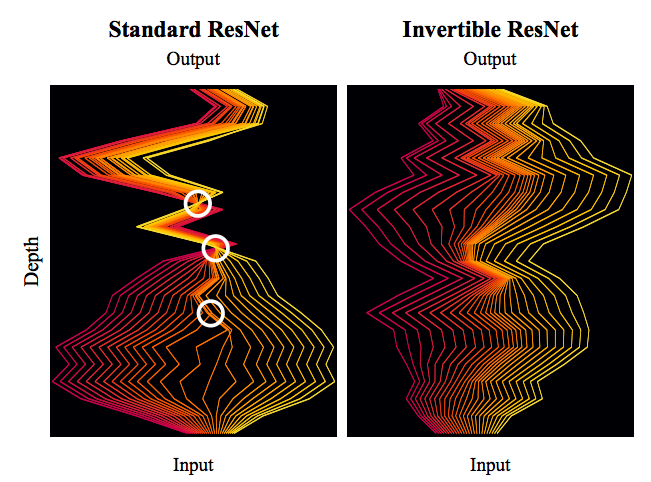
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 94649位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
6
Nov
Keras:Tensorflow的黄金标准
By 苏剑林 | 2019-11-06 | 81240位读者 | 引用这两周投入了比较多的精力去做bert4keras的开发,除了一些API的规范化工作外,其余的主要工作量是构建预训练部分的代码。在昨天,预训练代码基本构建完毕,并同时在TPU/多GPU环境下测试通过,从而有志(有算力)改进预训练模型的同学多了一个选择。——这可能是目前最为清晰易懂的bert及其预训练代码。
预训练代码链接: https://github.com/bojone/bert4keras/tree/master/pretraining
经过这两周的开发(填坑),笔者的最大感想就是:Keras已经成为了tensorflow的黄金标准了。只要你的代码按照Keras的标准规范写,那可以轻松迁移到tf.keras中去,继而可以非常轻松地在TPU或多GPU环境下训练,真正的几乎是一劳永逸。相反,如果你的写法过于灵活,包括像笔者之前介绍的很多“移花接木”式的Keras技巧,就可能会有不少问题,甚至可能出现的一种情况是:就算你已经在多GPU上跑通了,在TPU上你也死活调不通。

Keras和Tensorflow
19
Apr
从DCGAN到SELF-MOD:GAN的模型架构发展一览
By 苏剑林 | 2019-04-19 | 85478位读者 | 引用事实上,O-GAN的发现,已经达到了我对GAN的理想追求,使得我可以很惬意地跳出GAN的大坑了。所以现在我会试图探索更多更广的研究方向,比如NLP中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的GAN的学习结果都记录下来。
这篇文章中,我们来梳理一下GAN的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是GAN在图像方面的模型架构发展,跟NLP的SeqGAN没什么关系。
此外,关于GAN的基本科普,本文就不再赘述了。

棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章《Deconvolution and Checkerboard Artifacts》
1
Dec
级联抑制:提升GAN表现的一种简单有效的方法
By 苏剑林 | 2019-12-01 | 35589位读者 | 引用昨天刷arxiv时发现了一篇来自星星韩国的论文,名字很直白,就叫做《A Simple yet Effective Way for Improving the Performance of GANs》。打开一看,发现内容也很简练,就是提出了一种加强GAN的判别器的方法,能让GAN的生成指标有一定的提升。
作者把这个方法叫做Cascading Rejection,我不知道咋翻译,扔到百度翻译里边显示“级联抑制”,想想看好像是有这么点味道,就暂时这样叫着了。介绍这个方法倒不是因为它有多强大,而是觉得它的几何意义很有趣,而且似乎有一定的启发性。
正交分解
GAN的判别器一般是经过多层卷积后,通过flatten或pool得到一个固定长度的向量$\boldsymbol{v}$,然后再与一个权重向量$\boldsymbol{w}$做内积,得到一个标量打分(先不考虑偏置项和激活函数等末节):
\begin{equation}D(\boldsymbol{x})=\langle \boldsymbol{v},\boldsymbol{w}\rangle\end{equation}
也就是说,用$\boldsymbol{v}$作为输入图片的表征,然后通过$\boldsymbol{v}$和$\boldsymbol{w}$的内积大小来判断出这个图片的“真”的程度。
10
May
能量视角下的GAN模型(三):生成模型=能量模型
By 苏剑林 | 2019-05-10 | 58270位读者 | 引用
本文的模型在ImageNet(128x128)上的条件生成效果
今天要介绍的结果还是跟能量模型相关,来自论文《Implicit Generation and Generalization in Energy-Based Models》。当然,它已经跟GAN没有什么关系了,但是跟本系列第二篇所介绍的能量模型关系较大,所以还是把它放到这个系列好了。
我当初留意到这篇论文,是因为机器之心的报导《MIT本科学神重启基于能量的生成模型,新框架堪比GAN》,但是说实在的,这篇文章没什么意思,说句不中听的,就是炒冷饭系列,媒体的标题也算中肯,是“重启”。这篇文章就是指出能量模型实际上就是某个特定的Langevin方程的静态解,然后就用这个Langevin方程来实现采样,有了采样过程也就可以完成能量模型的训练,这些理论都是现成的,所以这个过程我在学习随机微分方程的时候都想过,我相信很多人也都想过。因此,我觉得作者的贡献就是把这个直白的想法通过一系列炼丹技巧实现了。
但不管怎样,能训练出来也是一件很不错的事情,另外对于之前没了解过相关内容的读者来说,这确实也算是一个不错的能量模型案例,所以我论文的整体思路整理一下,让读者能够更全面地理解能量模型。

最近评论