






18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 442911位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
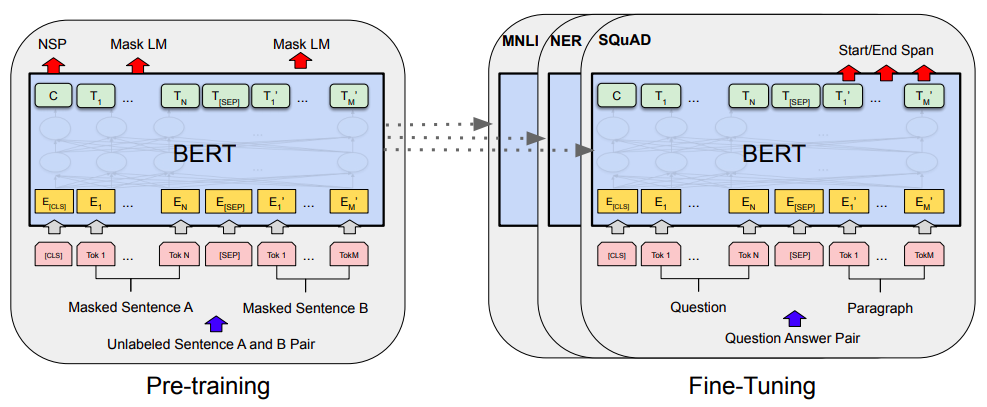
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
1
Mar
对抗训练浅谈:意义、方法和思考(附Keras实现)
By 苏剑林 | 2020-03-01 | 237406位读者 | 引用当前,说到深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。本博客里以前所涉及的对抗话题,都是前一种含义,而今天,我们来聊聊后一种含义中的“对抗训练”。
本文包括如下内容:
1、对抗样本、对抗训练等基本概念的介绍;
2、介绍基于快速梯度上升的对抗训练及其在NLP中的应用;
3、给出了对抗训练的Keras实现(一行代码调用);
4、讨论了对抗训练与梯度惩罚的等价性;
5、基于梯度惩罚,给出了一种对抗训练的直观的几何理解。
11
Dec
从动力学角度看优化算法(六):为什么SimSiam不退化?
By 苏剑林 | 2020-12-11 | 85335位读者 | 引用自SimCLR以来,CV中关于无监督特征学习的工作层出不穷,让人眼花缭乱。这些工作大多数都是基于对比学习的,即通过适当的方式构造正负样本进行分类学习的。然而,在众多类似的工作中总有一些特立独行的研究,比如Google的BYOL和最近的SimSiam,它们提出了单靠正样本就可以完成特征学习的方案,让人觉得耳目一新。但是没有负样本的支撑,模型怎么不会退化(坍缩)为一个没有意义的常数模型呢?这便是这两篇论文最值得让人思考和回味的问题了。
其中SimSiam给出了让很多人都点赞的答案,但笔者觉得SimSiam也只是把问题换了种说法,并没有真的解决这个问题。笔者认为,像SimSiam、GAN等模型的成功,很重要的原因是使用了基于梯度的优化器(而非其他更强或者更弱的优化器),所以不结合优化动力学的答案都是不完整的。在这里,笔者尝试结合动力学来分析SimSiam不会退化的原因。
SimSiam
在看SimSiam之前,我们可以先看看BYOL,来自论文《Bootstrap your own latent: A new approach to self-supervised Learning》,其学习过程很简单,就是维护两个编码器Student和Teacher,其中Teacher是Student的滑动平均,Student则又反过来向Teacher学习,有种“左脚踩右脚”就可以飞起来的感觉。示意图如下:
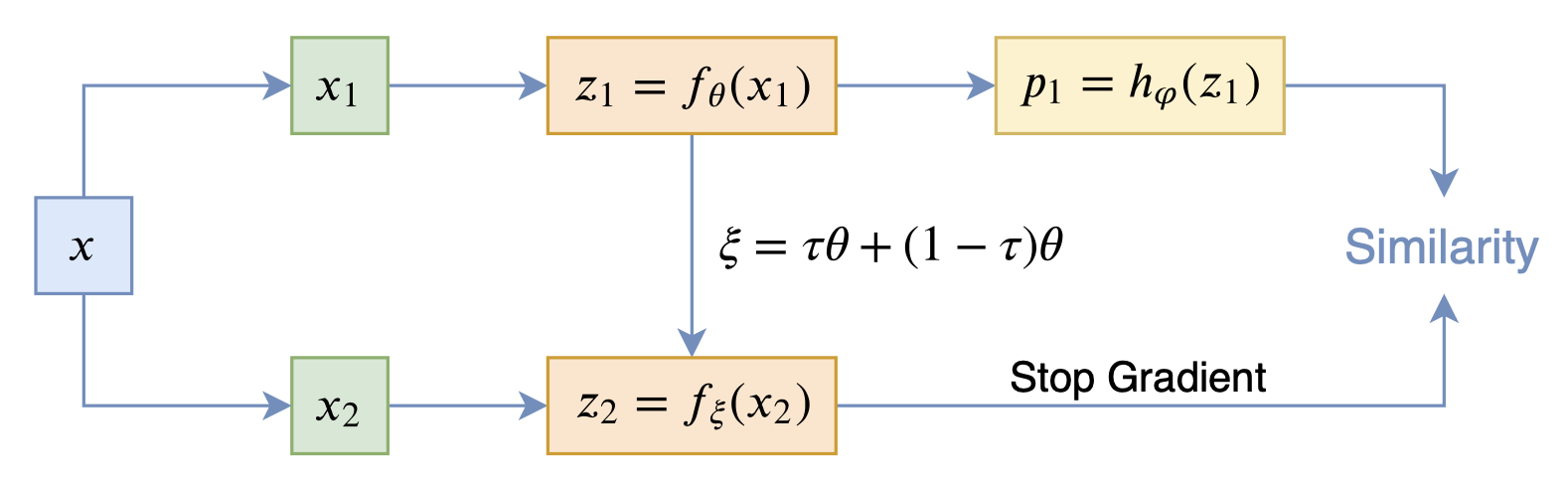
BYOL示意图
22
Apr
GAU-α:尝鲜体验快好省的下一代Attention
By 苏剑林 | 2022-04-22 | 51173位读者 | 引用在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了GAU(Gated Attention Unit,门控线性单元),在这里笔者愿意称之为“目前最有潜力的下一代Attention设计”,因为它真正达到了“更快(速度)、更好(效果)、更省(显存)”的特点。
然而,有些读者在自己的测试中得到了相反的结果,比如收敛更慢、效果更差等,这与笔者的测试结果大相径庭。本文就来分享一下笔者自己的训练经验,并且放出一个尝鲜版“GAU-α”供大家测试。
GAU-α
首先介绍一下开源出来的“GAU-α”在CLUE任务上的成绩单:
$$\small{\begin{array}{c|ccccccccccc}
\hline
& \text{iflytek} & \text{tnews} & \text{afqmc} & \text{cmnli} & \text{ocnli} & \text{wsc} & \text{csl} & \text{cmrc2018} & \text{c3} & \text{chid} & \text{cluener}\\
\hline
\text{BERT} & 60.06 & 56.80 & 72.41 & 79.56 & 73.93 & 78.62 & 83.93 & 56.17 & 60.54 & 85.69 & 79.45 \\
\text{RoBERTa} & 60.64 & \textbf{58.06} & 74.05 & 81.24 & 76.00 & \textbf{87.50} & 84.50 & 56.54 & 67.66 & 86.71 & 79.47\\
\text{RoFormer} & 60.91 & 57.54 & 73.52 & 80.92 & \textbf{76.07} & 86.84 & 84.63 & 56.26 & 67.24 & 86.57 & 79.72\\
\text{RoFormerV2}^* & 60.87 & 56.54 & 72.75 & 80.34 & 75.36 & 80.92 & 84.67 & 57.91 & 64.62 & 85.09 & \textbf{81.08}\\
\hline
\text{GAU-}\alpha & \textbf{61.41} & 57.76 & \textbf{74.17} & \textbf{81.82} & 75.86 & 79.93 & \textbf{85.67} & \textbf{58.09} & \textbf{68.24} & \textbf{87.91} & 80.01\\
\hline
\end{array}}$$
16
Feb
Google新搜出的优化器Lion:效率与效果兼得的“训练狮”
By 苏剑林 | 2023-02-16 | 54593位读者 | 引用昨天在Arixv上发现了Google新发的一篇论文《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。
先说结果
本文主要关心搜索出来的优化器本身,所以关于搜索过程的细节就不讨论了,对此有兴趣读者自行看原论文就好。Lion优化器的更新过程为
\begin{equation}\text{Lion}:=\left\{\begin{aligned}
&\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\
&\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t
\end{aligned}\right.\end{equation}
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 68752位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
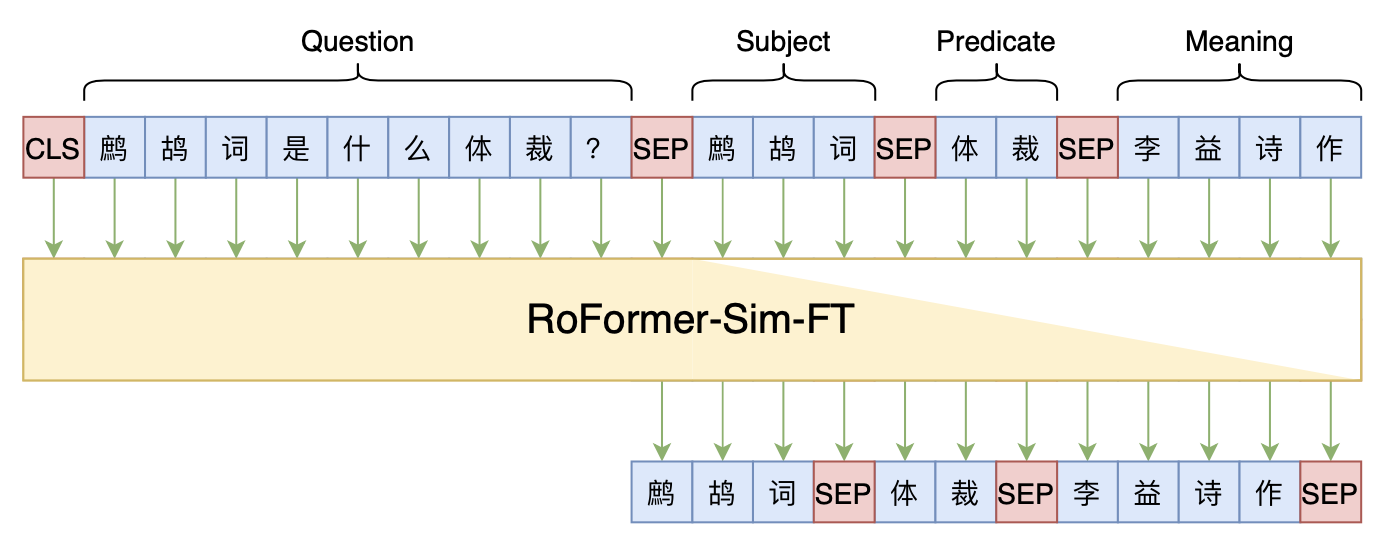
本文baseline模型示意图
27
Jun
哈哈,我的“《圣经》”到了
By 苏剑林 | 2013-06-27 | 56918位读者 | 引用
7
Jul


最近评论