






16
Feb
Google新搜出的优化器Lion:效率与效果兼得的“训练狮”
By 苏剑林 | 2023-02-16 | 82612位读者 |昨天在Arixv上发现了Google新发的一篇论文《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。
先说结果 #
本文主要关心搜索出来的优化器本身,所以关于搜索过程的细节就不讨论了,对此有兴趣读者自行看原论文就好。Lion优化器的更新过程为
\begin{equation}\text{Lion}:=\left\{\begin{aligned}
&\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\
&\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t
\end{aligned}\right.\end{equation}
其中$\boldsymbol{g}_t = \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{t-1})$是损失函数的梯度,$\text{sign}$是符号函数,即正数变为1、负数变为-1。我们可以对比一下目前的主流优化器AdamW的更新过程
\begin{equation}\text{Adam}\color{skyblue}{\text{W}}:=\left\{\begin{aligned}
&\boldsymbol{m}_t = \beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\\
&\boldsymbol{v}_t = \beta_2 \boldsymbol{v}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t^2\\
&\hat{\boldsymbol{m}}_t = \boldsymbol{m}_t\left/\left(1 - \beta_1^t\right)\right.\\
&\hat{\boldsymbol{v}}_t = \boldsymbol{v}_t\left/\left(1 - \beta_2^t\right)\right.\\
&\boldsymbol{u}_t =\hat{\boldsymbol{m}}_t\left/\left(\sqrt{\hat{\boldsymbol{v}}_t} + \epsilon\right)\right.\\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}})
\end{aligned}\right.\end{equation}
对比很明显,Lion相比AdamW参数更少(少了个$\epsilon$),少缓存了一组参数$\boldsymbol{v}$(所以更省显存),并且去掉了AdamW更新过程中计算量最大的除法和开根号运算(所以更快)。
在此之前,跟Lion最相似的优化器应该是SIGNUM,其更新过程为
\begin{equation}\text{SIGNUM}:=\left\{\begin{aligned}
&\boldsymbol{m}_t = \beta \boldsymbol{m}_{t-1} + \left(1 - \beta\right) \boldsymbol{g}_t \\
&\boldsymbol{u}_t = \text{sign}\big(\boldsymbol{m}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t \boldsymbol{u}_t \end{aligned}\right.\end{equation}
跟Lion一样,SIGNUM也用到了符号函数处理更新量,而且比Lion更加简化(等价于Lion在$\beta_1=\beta_2$和$\lambda_t=0$的特例),但是很遗憾,SIGNUM并没有取得更好的效果,它的设计初衷只是降低分布式计算中的传输成本。Lion的更新规则有所不同,尤其是动量的更新放在了变量的更新之后,并且在充分的实验中显示出了它在效果上的优势。
论文实验 #
本文开头就说了,Lion在相当多的任务上都做了实验,实验结果很多,下面罗列一些笔者认为比较关键的结果。
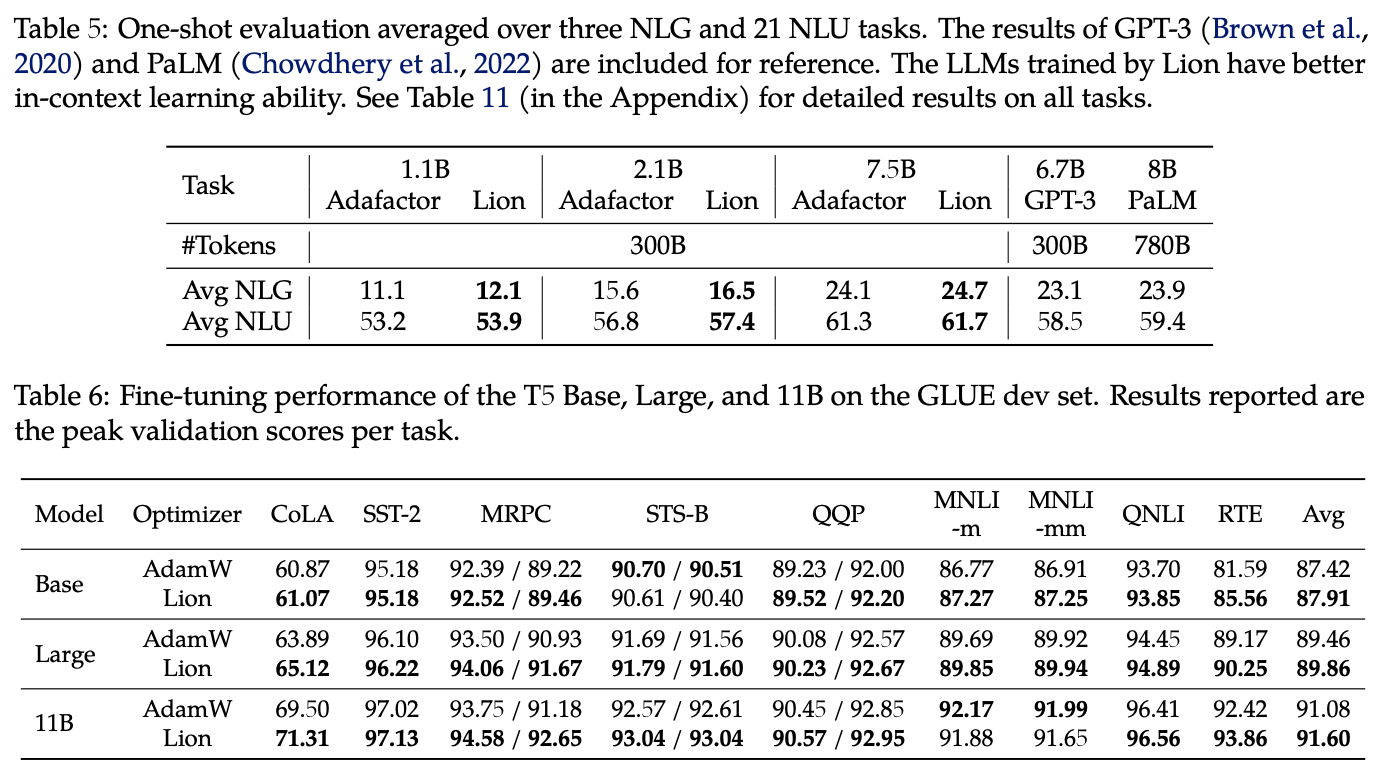
Lion在NLU和NLG任务上的结果,大部分都比AdamW、Adafactor优秀
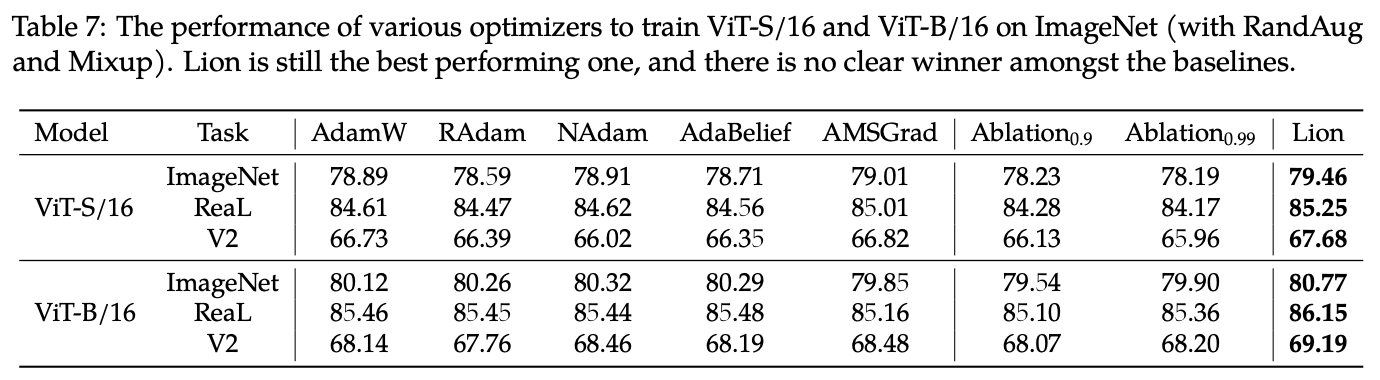
在视觉Transformer上Lion与众多优化器的对比
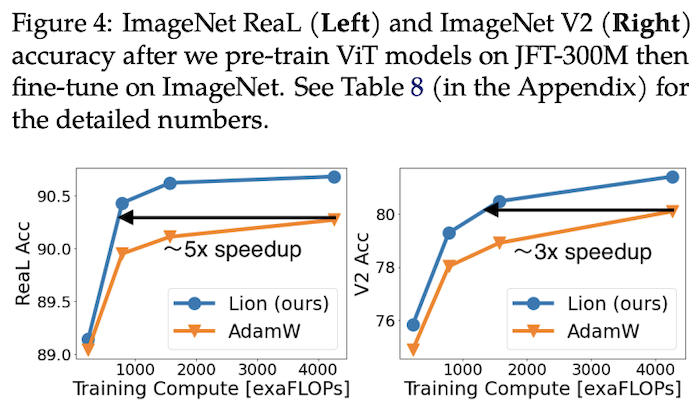
在CV的分类任务上,Lion收敛速度更快
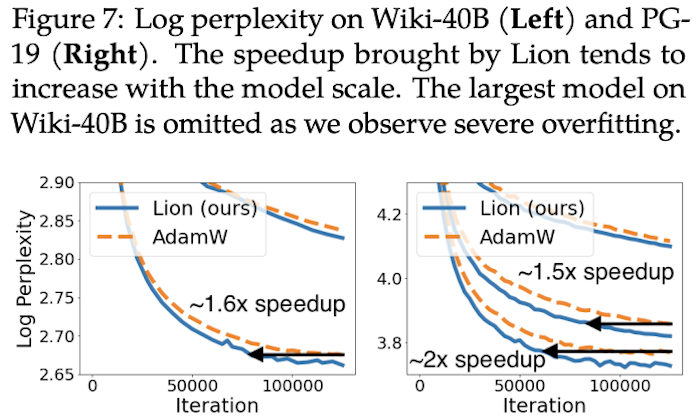
在NLP的自回归生成上,Lion的收敛速度更快
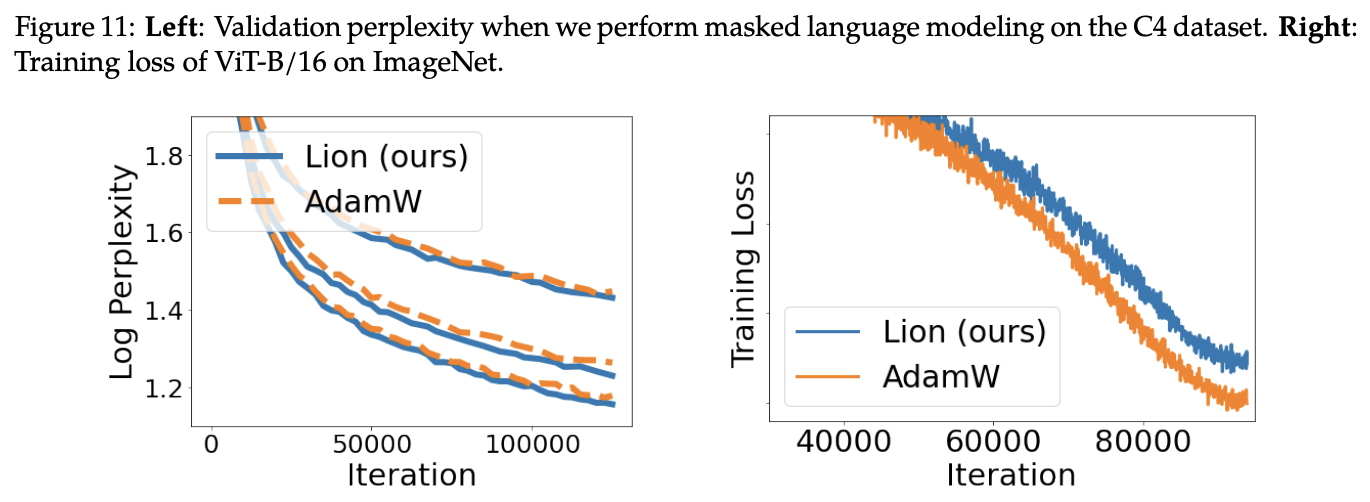
上右图是ImageNet上的训练曲线,显示Lion尽管验证集效果更好,但训练集上的效果未必会优于AdamW
超参设置 #
看到论文效果如此惊人,笔者也跃跃欲试。在跑实验之前,自然需要了解一下各个超参的设置。首先是$\beta_1,\beta_2$,原论文自动搜索出来的结果是$\beta_1=0.9,\beta=0.99$,并在大部分实验中复用了这个组合,但是在NLP的任务上则使用了$\beta_1=0.95,\beta_2=0.98$这个组合(论文的详细实验配置在最后一页的Table 12)。
比较关键的学习率$\eta$和权重衰减率$\lambda$,由于Lion的更新量$\boldsymbol{u}$每个分量的绝对值都是1,这通常比AdamW要大,所以学习率要缩小10倍以上,才能获得大致相同的更新幅度;而由于学习率降低了,那么为了使权重衰减的幅度保持不变,权重衰减率应该要放大相应的倍数。原论文的最后一页给出了各个实验的超参数参考值,其中小模型(Base级别)上使用的是$\eta = 3\times 10^{-4}$和$\lambda=0.01$,大模型(参数10亿以上)则适当降低了学习率到$\eta = 2\times 10^{-4}$甚至$\eta = 10^{-4}$。
事实上,之前我们在《基于Amos优化器思想推导出来的一些“炼丹策略”》就推导过学习率和权重衰减率的一个组合方案,参考这个方案来设置是最方便的。在该方案中,更新量写为(记号跟前面的描述略有不同,但不至于混淆,应该就不强行统一了)
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - (\alpha_t \boldsymbol{u}_t + \rho_t\boldsymbol{\theta}_t)\end{equation}
其中
\begin{equation}\alpha_t \approx \frac{\alpha_0\Vert\boldsymbol{\varepsilon}_0\Vert}{\Vert\boldsymbol{u}_t\Vert} \frac{1}{\kappa t + 1},\quad \rho_t \approx \frac{\alpha_0^2}{2q} \frac{1}{\kappa t + 1}\end{equation}
其中$\boldsymbol{u}_t$是原本的更新量;$\alpha_0$是(初始阶段)参数变化的相对大小,一般是$10^{-3}$级别,表示每步更新后参数模长的变化幅度大致是千分之一;$q$是一个超参数,没什么特殊情况可以设为1;$\kappa$是控制学习率衰减速度的超参数,可以根据训练数据大小等设置。
由于$\boldsymbol{u}_t$经过了$\text{sign}$运算,因此$\Vert\boldsymbol{u}_t\Vert=\sqrt{k}$,$k$是参数的维度;$\Vert\boldsymbol{\varepsilon}_0\Vert\approx\sqrt{k}\sigma$,这我们在《基于Amos优化器思想推导出来的一些“炼丹策略”》已经推导过了,其中$\sigma$是参数的变化尺度,对于乘性矩阵,$\sigma^2$就是它的初始化方差。所以,经过一系列简化之后,有
\begin{equation}\alpha_t \approx \frac{\alpha_0\sigma}{\kappa t + 1},\quad \rho_t \approx \frac{\alpha_0^2}{2(\kappa t + 1)}\end{equation}
这里的$\alpha_t$就是前面的$\eta_t$,而$\lambda_t = \rho_t / \alpha_t = \alpha_0 / 2\sigma$。按照BERT base的$d=768$来算,初始化方差的量级大致在$1/d$左右,于是$\sigma = \sqrt{1/d}\approx 0.036$,假设$\alpha_0$取$1.11 \times 10^{-3}$(为了给结果凑个整),那么按照上式学习率大约是$4\times 10^{-5}$、衰减率大约是$0.015$。在笔者自己的MLM预训练实验中,选取这两个组合效果比较好。
延伸思考 #
总体来看,Lion表现可圈可点,不管是原论文还是笔者自己的实验中,跟AdamW相比都有一战之力,再加上Lion更快以及更省显存的特点,或者可以预见未来的主流优化器将有它的一席之地。
自Adam提出以来,由于其快速收敛的特性成为了很多模型的默认优化器。甚至有学者提出,这个现象将反过来导致一个进化效应:所有的模型改进都在往Adam有利的方向发展,换句话说,由于我们选择了Adam作为优化器,那么就有可能将很多实际有效、但是在Adam优化器上无效的改动都抛弃了,剩下的都是对Adam有利的改进,详细的评价可以参考《NEURAL NETWORKS (MAYBE) EVOLVED TO MAKE ADAM THE BEST OPTIMIZER》。所以,在此大背景之下,能够发现比Adam更简单且更有效的优化器,是一件很了不起的事情,哪怕它是借助大量算力搜索出来的。
可能读者会有疑问:Lion凭啥可以取得更好的泛化性能呢?原论文的解释是$\text{sign}$这个操作引入了额外的噪声(相比于准确的浮点值),它使得模型进入了Loss更平坦(但未必更小)的区域,从而泛化性能更好。为了验证这一点,作者比较了AdamW和Lion训练出来的模型权重的抗干扰能力,结果显示Lion的抗干扰能力更好。然而,理论上来说,这只能证明Lion确实进入到了更平坦的区域,但无法证明该结果是$\text{sign}$操作造成的。不过,Adam发表这么多年了,关于它的机理也还没有彻底研究清楚,而Lion只是刚刚提出,就不必过于吹毛求疵了。
笔者的猜测是,Lion通过$\text{sign}$操作平等地对待了每一个分量,使得模型充分地发挥了每一个分量的作用,从而有更好的泛化性能。如果是SGD,那么更新的大小正比于它的梯度,然而有些分量梯度小,可能仅仅是因为它没初始化好,而并非它不重要,所以Lion的$\text{sign}$操作算是为每个参数都提供了“恢复活力”甚至“再创辉煌”的机会。事实上可以证明,Adam早期的更新量也接近于$\text{sign}$,只是随着训练步数的增加才逐渐偏离。
Lion是不是足够完美呢?显然不是,比如原论文就指出它在小batch_size(小于64)的时候效果不如AdamW,这也不难理解,本来$\text{sign}$已经带来了噪声,而小batch_size则进一步增加了噪声,噪声这个东西,必须适量才好,所以两者叠加之下,很可能有噪声过量导致效果恶化。另外,也正因为$\text{sign}$加剧了优化过程的噪声,所以参数设置不当时容易出现损失变大等发散情况,这时候可以尝试引入Warmup,或者增加Warmup步数。还有,Lion依旧需要缓存动量参数,所以它的显存占用多于AdaFactor,能不能进一步优化这部分参数量呢?暂时还不得而知。
文章小结 #
本文介绍了Google新提出的优化器Lion,它通过大量算力搜索并结合人工干预得出,相比主流的AdamW,有着速度更快且更省内存的特点,并且大量实验结果显示,它在多数任务上都有着不逊色于甚至优于AdamW的表现。
转载到请包括本文地址:https://kexue.fm/archives/9473
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Feb. 16, 2023). 《Google新搜出的优化器Lion:效率与效果兼得的“训练狮” 》[Blog post]. Retrieved from https://kexue.fm/archives/9473
@online{kexuefm-9473,
title={Google新搜出的优化器Lion:效率与效果兼得的“训练狮”},
author={苏剑林},
year={2023},
month={Feb},
url={\url{https://kexue.fm/archives/9473}},
}

February 20th, 2023
那是不是可以使用梯度累积的方式满足batch_size > 64的要求呢?
这个自然可以。
February 21st, 2023
请问"超参设置"小节里衰减率≈0.015是怎么算出来的呢?我算的是:(1.11e-3)**2/2=6.160500000000001e-07
根据习惯$\theta_{t+1} = \theta_t -\alpha_t(u_t+\lambda_t \theta_t)= \theta_t -\alpha_t u_t-\rho_t\theta_t$,衰减率一般指代$\lambda_t=\rho_t/\alpha_t$。
是的,一般称衰减率指的是$\lambda_t$。
February 21st, 2023
感谢苏神!我通过可视化对比了Lion与Adam优化器,可以看到Lion优化器趋向于在大范围进行搜索解空间以后再进行小范围搜索,与adam不同,adam趋向于直接使用小范围局部的梯度直接走向局部最小值,此外SGD也有类似的表现,而SIGNUM则与Lion相近,但是由于其没有衰减系数,无法快速的锁定大致范围。此外Lion优化器必须搭配学习率衰减。
github地址:https://github.com/nengwp/Lion-vs-Adam
February 21st, 2023
lr的schedule有什么讲究吗?warmup和decay的策略
这个网上有很多参考工作了,我自己没有太好的经验可以分享。
March 2nd, 2023
Hi, I found that the LION optimizer is related to the paper "Noise Is Not the Main Factor Behind the Gap Between Sgd and Adam on Transformers, But Sign Descent Might Be" (https://openreview.net/pdf?id=a65YK0cqH8g). This paper empirically showed that Sign-SGD behaves more like Adam and benefits from noise.
I appreciate your idea that "Lion通过sign操作平等地对待了每一个分量,使得模型充分地发挥了每一个分量的作用,从而有更好的泛化性能". Also, I am curious about the idea of "事实上可以证明,Adam早期的更新量也接近于sign,只是随着训练步数的增加才逐渐偏离". I wonder what is the intuition behind the idea.
Thank you.
Thank you for sharing the paper! It is indeed valuable work.
It is easy to prove that $\hat{\boldsymbol{m}}_1 = \boldsymbol{g}_1$ and $\hat{\boldsymbol{v}}_1 = |\boldsymbol{g}_1|$. Therefore we have $\boldsymbol{u}_1 = \boldsymbol{g}_1 / |\boldsymbol{g}_1|=\text{sign}(\boldsymbol{g}_1)$ for Adam. At the beginning of training, $\boldsymbol{g}_2,\boldsymbol{g}_3,\cdots$ still has a direction similar to $\boldsymbol{g}_1$, so the result still holds approximately.
April 4th, 2023
Noise Is Not the Main Factor Behind the Gap Between Sgd and Adam on Transformers, But Sign Descent Might Be 這篇 paper 有從理論角度闡明 sign 對梯度下降的優缺點。
谢谢。之前已经找到过这篇文献。
April 9th, 2023
有个没想通的地方
> Lion的更新规则有所不同,尤其是动量的更新放在了变量的更新之后,并且在充分的实验中显示出了它在效果上的优势。
在公式(1)中,LION在更新动量$m_t$时, $g_t$是在新的参数下重新算出来的吗?
- 如果是的话,那么公式(1)中的第一个公式计算$u_t$时,$g_t$是不是应该改为$g_{t-1}$?
- 如果不是的话,那么动量更新放在前后好像也没什么差异了?
看原论文中的伪代码,也是没有重新算$g_t$的,那么动量更新在变量更新之前还是之后,会有什么不同吗?
这里跟具体的实现有关系,就是如果先更新了$\boldsymbol{m}_t$,那么$\boldsymbol{m}_{t-1}$就被覆盖了,无法直接算更新量了(或者只能间接从$\boldsymbol{m}_t$倒推出来)。
May 31st, 2023
请教一个问题,Lion这个优化器适用于Embedding的训练吗?我发现使用Lion之后,Embedding的norm2会越来越大,最后就炸了(即便配合weight_decay也是杯水车薪,很难控制住)。
我测试下来发现Adam类的优化器在embedding更新的时候,embedding的norm2会非常稳定,增长非常缓慢。
目前我摸索出来比较稳定的策略是,先全部用NAdam小学习率初始化一个epoch,然后主干用Lion,embedding还是用NAdam,配合warmup+decay。
我后面都是用Tiger了(可以理解为Lion的一个case):https://kexue.fm/archives/9512
里边的关键之一是用权重的RMS来自适应调节学习率,我这边直接从零预训练的表现都不错(最大尝试过3亿参数量的模型训练)。
July 26th, 2023
苏神,前一段同时接触到两个今年出的优化器lion和adan,在我的数据集上后者较优,不知道您对adan怎么看。Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models
看了看,增加了两组缓存变量($\boldsymbol{g}_{k-1}$和$\boldsymbol{n}_{k-1}$),看起来有点脑壳疼...