






1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 378111位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 292969位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
22
Feb
巧断梯度:单个loss实现GAN模型
By 苏剑林 | 2019-02-22 | 47969位读者 | 引用我们知道普通的模型都是搭好架构,然后定义好loss,直接扔给优化器训练就行了。但是GAN不一样,一般来说它涉及有两个不同的loss,这两个loss需要交替优化。现在主流的方案是判别器和生成器都按照1:1的次数交替训练(各训练一次,必要时可以给两者设置不同的学习率,即TTUR),交替优化就意味我们需要传入两次数据(从内存传到显存)、执行两次前向传播和反向传播。
如果我们能把这两步合并起来,作为一步去优化,那么肯定能节省时间的,这也就是GAN的同步训练。
(注:本文不是介绍新的GAN,而是介绍GAN的新写法,这只是一道编程题,不是一道算法题~)
如果在TF中
10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 89913位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
26
Feb
非对抗式生成模型GLANN的简单介绍
By 苏剑林 | 2019-02-26 | 71853位读者 | 引用前段时间看到facebook发表了一个非对抗的生成模型GLANN(去年12月挂在arxiv上),号称用非对抗的方式也能生成1024的高清人脸,于是饶有兴致地阅读了一番,确实有点收获,但也有点失望。至于为啥失望,大家阅读下去就明白了。
原论文:《Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors》
机器之心介绍:《为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN》
效果图:

GLANN效果图
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 120683位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
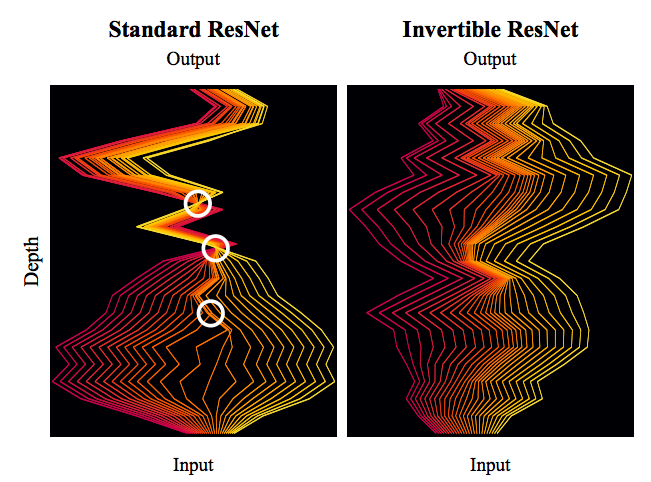
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
19
Oct
最小熵原理(五):“层层递进”之社区发现与聚类
By 苏剑林 | 2019-10-19 | 163357位读者 | 引用让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为InfoMap,或者MapEquation。事实上InfoMap已经是2007年的成果了,最早的论文是《Maps of random walks on complex networks reveal community structure》,虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
一个复杂有向图网络示意图。图片来自InfoMap最早的论文《Maps of random walks on complex networks reveal community structure》
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富。(还可以参考《什么是社区发现?》)
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 105043位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。

最近评论