






30
Oct
缅怀金庸 | 愿你登上10930小行星继续翱翔
By 苏剑林 | 2018-10-30 | 22298位读者 | 引用
金庸大师
金庸走了,享年94岁。
虽然说这些高龄大师们,不管是科学家还是文学家,他们在晚年基本上都不会有什么产出,过于理性的话会有“去了就去了,好像也没有什么损失”的感觉。然而,事实是大师的逝去总让我们有一种悲伤的震撼感,总让我们觉得似乎一个时代又逝去了。霍金是这样,金庸也是这样。
对于金老爷子来说,是一个武侠时代过去了,是一个江湖过去了。
飞雪连天射白鹿,笑书神侠倚碧鸳。
这个对联描述了金庸的14部作品,加上《越女剑》,就构成了他的15部武侠小说。金庸用这15部小说,描述了一个个活灵活现的江湖,不,说江湖好象都太小了,读完这15部作品,你会感觉他描述了整个中国几千年的历史、整个社会。
15
Nov
又一道川菜!媲美“开水白菜”的瓜燕穗肚
By 苏剑林 | 2018-11-15 | 35904位读者 | 引用
1
Mar
构造一个显式的、总是可逆的矩阵
By 苏剑林 | 2019-03-01 | 44144位读者 | 引用从《恒等式 det(exp(A)) = exp(Tr(A)) 赏析》一文我们得到矩阵$\exp(\boldsymbol{A})$总是可逆的,它的逆就是$\exp(-\boldsymbol{A})$。问题是$\exp(\boldsymbol{A})$只是一个理论定义,单纯这样写没有什么价值,因为它要把每个$\boldsymbol{A}^n$都算出来。
有没有什么具体的例子呢?有,本文来构造一个显式的、总是可逆的矩阵。
其实思路非常简单,假设$\boldsymbol{x},\boldsymbol{y}$是两个$k$维列向量,那么$\boldsymbol{x}\boldsymbol{y}^{\top}$就是一个$k\times k$的矩阵,我们就来考虑
\begin{equation}\begin{aligned}\exp\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)=&\sum_{n=0}^{\infty}\frac{\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)^n}{n!}\\
=&\boldsymbol{I}+\boldsymbol{x}\boldsymbol{y}^{\top}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{2}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{6}+\dots\end{aligned}\end{equation}
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 102852位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
26
Feb
非对抗式生成模型GLANN的简单介绍
By 苏剑林 | 2019-02-26 | 70200位读者 | 引用前段时间看到facebook发表了一个非对抗的生成模型GLANN(去年12月挂在arxiv上),号称用非对抗的方式也能生成1024的高清人脸,于是饶有兴致地阅读了一番,确实有点收获,但也有点失望。至于为啥失望,大家阅读下去就明白了。
原论文:《Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors》
机器之心介绍:《为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN》
效果图:

GLANN效果图
14
Mar
圆周率节快乐!|| 原来已经写了十年博客~
By 苏剑林 | 2019-03-14 | 79066位读者 | 引用
28
Apr
“让Keras更酷一些!”:中间变量、权重滑动和安全生成器
By 苏剑林 | 2019-04-28 | 104624位读者 | 引用继续“让Keras更酷一些”之旅。
今天我们会用Keras实现灵活地输出任意中间变量,还有无缝地进行权重滑动平均,最后顺便介绍一下生成器的进程安全写法。
首先是输出中间变量。在自定义层时,我们可能希望查看中间变量,这些需求有些是比较容易实现的,比如查看中间某个层的输出,只需要将截止到这个层的部分模型保存为一个新模型即可,但有些需求是比较困难的,比如在使用Attention层时我们可能希望查看那个Attention矩阵的值,如果用构建新模型的方法则会非常麻烦。而本文则给出一种简单的方法,彻底满足这个需求。
接着是权重滑动平均。权重滑动平均是稳定、加速模型训练甚至提升模型效果的一种有效方法,很多大型模型(尤其是GAN)几乎都用到了权重滑动平均。一般来说权重滑动平均是作为优化器的一部分,所以一般需要重写优化器才能实现它。本文介绍一个权重滑动平均的实现,它可以无缝插入到任意Keras模型中,不需要自定义优化器。
至于生成器的进程安全写法,则是因为Keras读取生成器的时候,用到了多进程,如果生成器本身也包含了一些多进程操作,那么可能就会导致异常,所以需要解决这个这个问题。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 265653位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
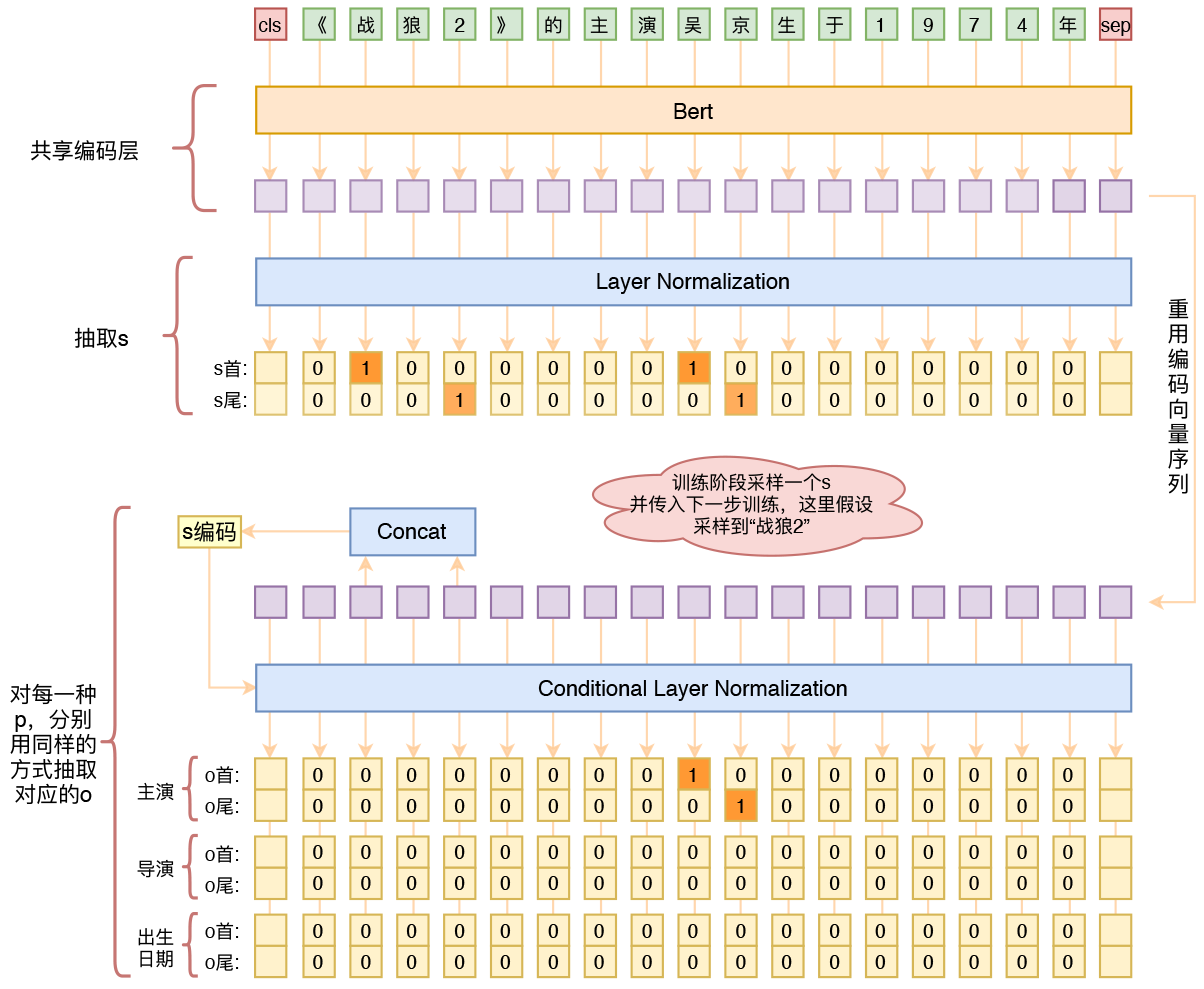
基于Bert的三元组抽取模型结构示意图

最近评论