






7
Jun
通过msign来计算奇异值裁剪mclip(上)
By 苏剑林 | 2025-06-07 | 16676位读者 | 引用前面我们用了两篇文章《msign算子的Newton-Schulz迭代(上)》和《msign算子的Newton-Schulz迭代(下)》讨论了矩阵的$\newcommand{msign}{\mathop{\text{msign}}}\newcommand{sign}{\mathop{\text{sign}}}\newcommand{clip}{\mathop{\text{clip}}}\newcommand{mclip}{\mathop{\text{mclip}}}\msign$算子的数值计算,这篇文章我们来关注“奇异值裁剪(Singular Value Clipping)”运算,它最近在 @_arohan_ 的推特上引起了热议,我们此前在《高阶MuP:更简明但更高明的谱条件缩放》也提到过,接下来我们简称为$\mclip$。
基本概念
对于标量$x$,$\clip$运算定义为
\begin{equation}\clip(x) = \max(\min(x, 1), -1) = \left\{\begin{aligned}1, &\quad x\geq 1 \\
x, &\quad x\in(-1, 1)\\
-1, &\quad x\leq -1
\end{aligned}\right.\end{equation}
5
Jun
msign算子的Newton-Schulz迭代(下)
By 苏剑林 | 2025-06-05 | 21684位读者 | 引用在上文《msign算子的Newton-Schulz迭代(上)》中,我们试图为$\mathop{\text{msign}}$算子寻找更好的Newton-Schulz迭代,以期在有限迭代步数内能达到尽可能高的近似程度,这一过程又可以转化为标量函数$\mathop{\text{sign}}(x)$寻找同样形式的多项式迭代。当时,我们的求解思路是用Adam优化器端到端地求一个局部最优解,虽然有效但稍显粗暴。
而在几天前,arXiv新出了一篇论文《The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm》,作者运用了一系列精妙的数学结论,以优雅且硬核的方式给出了更漂亮的答案。本文让我们一起欣赏和学习一番这篇精彩的论文。
问题描述
相关背景和转化过程我们就不再重复了,直接给出我们要求解的问题是
\begin{equation}\mathop{\text{argmin}}_f d(f(x),1)\end{equation}
2
Jun
等值振荡定理:最优多项式逼近的充要条件
By 苏剑林 | 2025-06-02 | 15143位读者 | 引用最近在阅读时,遇到了一个关于最优多项式逼近的“等值振荡定理(Equioscillation Theorem)”,证明过程还涉及到无穷范数求导,感觉结论和证明都颇为新奇,特来记录一番。
参考资料:《Notes on how to prove Chebyshev’s equioscillation theorem》和《Approximation Theory – Lecture 5》。
等值振荡
我们先展示一下结论:
等值振荡定理 设$f(x)$是不超过$n$阶的多项式,$g(x)$是区间$[a,b]$上的连续函数,那么
\begin{equation}f^* = \mathop{\text{argmin}}_f \max_{x\in[a,b]} |f(x) - g(x)|\end{equation}
的充要条件是存在$a\leq x_0 < x_1 < \cdots < x_{n+1} \leq b$以及$\sigma\in\{0,1\}$,使得
\begin{equation}f^*(x_k) - g(x_k) = (-1)^{k+\sigma} \max_{x\in[a,b]} |f^*(x) - g(x)|\end{equation}
11
May
msign算子的Newton-Schulz迭代(上)
By 苏剑林 | 2025-05-11 | 29295位读者 | 引用在之前的《Muon优化器赏析:从向量到矩阵的本质跨越》、《Muon续集:为什么我们选择尝试Muon?》等文章中,我们介绍了一个极具潜力、有望替代Adam的新兴优化器——“Muon”。随着相关研究的不断深入,Muon优化器受到的关注度也在日益增加。
了解过Muon的读者都知道,Muon的核心运算是$\newcommand{msign}{\mathop{\text{msign}}}\msign$算子,为其寻找更高效的计算方法是学术社区的一个持续目标。本文将总结一下它的最新进展。
写在前面
$\msign$的定义跟SVD密切相关。假设矩阵$\boldsymbol{M}\in\mathbb{R}^{n\times m}$,那么
\begin{equation}\boldsymbol{U},\boldsymbol{\Sigma},\boldsymbol{V}^{\top} = \text{SVD}(\boldsymbol{M}) \quad\Rightarrow\quad \msign(\boldsymbol{M}) = \boldsymbol{U}_{[:,:r]}\boldsymbol{V}_{[:,:r]}^{\top}\end{equation}
其中$\boldsymbol{U}\in\mathbb{R}^{n\times n},\boldsymbol{\Sigma}\in\mathbb{R}^{n\times m},\boldsymbol{V}\in\mathbb{R}^{m\times m}$,$r$是$\boldsymbol{M}$的秩。简单来说,$\msign$就是把矩阵的所有非零奇异值都变成1后所得的新矩阵。
30
Apr
一道概率不等式:盯着它到显然成立为止!
By 苏剑林 | 2025-04-30 | 25587位读者 | 引用前两天,QQ群里有群友抛出了一道不等式求证:
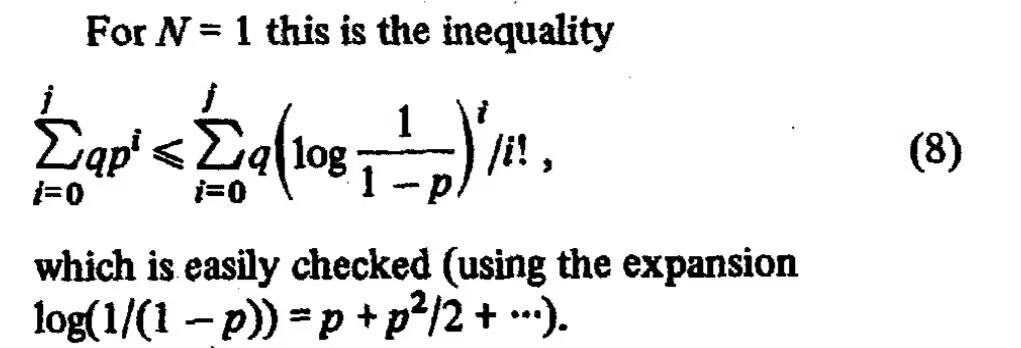
一道概率相关的不等式,出自《There is no fast single hashing algorithm》
简短的题目,加上“easily”的提示,让人觉得这似乎是显然成立的结果,然而提问者却表示尝试了很久仍未果。那么实际情况如何呢?是否真的是显然成立呢?
初步尝试
题目等价于证
\begin{equation}\sum_{i=0}^j p^i \leq \sum_{i=0}^j \left(\log\frac{1}{1-p}\right)^i/i!,\qquad p\in[0, 1)\label{eq:q}\end{equation}
SVD(Singular Value Decomposition,奇异值分解)是常见的矩阵分解算法,相信很多读者都已经对它有所了解,此前我们在《低秩近似之路(二):SVD》也专门介绍过它。然而,读者是否想到,SVD竟然还可以求导呢?笔者刚了解到这一结论时也颇感意外,因为直觉上“分解”往往都是不可导的。但事实是,SVD在一般情况下确实可导,这意味着理论上我们可以将SVD嵌入到模型中,并用基于梯度的优化器来端到端训练。
问题来了,既然SVD可导,那么它的导函数长什么样呢?接下来,我们将参考文献《Differentiating the Singular Value Decomposition》,逐步推导SVD的求导公式。
推导基础
假设$\boldsymbol{W}$是满秩的$n\times n$矩阵,且全体奇异值两两不等,这是比较容易讨论的情形,后面我们也会讨论哪些条件可以放宽一点。接着,我们设$\boldsymbol{W}$的SVD为:
\begin{equation}\boldsymbol{W} = \boldsymbol{U}\boldsymbol{\Sigma}\boldsymbol{V}^{\top}\end{equation}
18
Apr
Transformer升级之路:19、第二类旋转位置编码
By 苏剑林 | 2025-04-18 | 53042位读者 | 引用持续将“Transformer升级之路”系列关注到本篇的读者,想必都已经对旋转位置编码(RoPE)有所了解。简单来说,RoPE是施加在Attention的Query($\boldsymbol{Q}$)和Key($\boldsymbol{K}$)上的旋转变换,形式上属于绝对位置编码,但结合Attention的内积(Dot-Product)特性,能够自动实现相对位置的效果。
那么,RoPE可以加在Value($\boldsymbol{V}$)上吗?看上去不可以,因为对$\boldsymbol{V}$旋转后就不是相对位置编码了。然而事情并没有那么绝对,本文就来讨论加在$\boldsymbol{V}$上RoPE,我们可以称之为“第二类旋转位置编码”。
基础回顾
我们将Dot-Product Attention分解为
\begin{equation}\boldsymbol{o}_i = \sum_j a_{i,j}\boldsymbol{v}_j,\qquad a_{i,j} = \frac{e^{s_{i,j}}}{\sum\limits_j e^{s_{i,j}}},\qquad s_{i,j} = \boldsymbol{q}_i^{\top}\boldsymbol{k}_j\end{equation}
10
Apr
矩阵的有效秩(Effective Rank)
By 苏剑林 | 2025-04-10 | 34640位读者 | 引用秩(Rank)是线性代数中的重要概念,它代表了矩阵的内在维度。然而,数学上对秩的严格定义,很多时候并不完全适用于数值计算场景,因为秩等于非零奇异值的个数,而数学上对“等于零”这件事的理解跟数值计算有所不同,数学上的“等于零”是绝对地、严格地等于零,哪怕是$10^{-100}$也是不等于零,但数值计算不一样,很多时候$10^{-10}$就可以当零看待。
因此,我们希望将秩的概念推广到更符合数值计算特性的形式,这便是有效秩(Effective Rank)概念的由来。
误差截断
需要指出的是,目前学术界对有效秩并没有统一的定义,接下来我们介绍的是一些从不同角度切入来定义有效秩的思路。对于实际问题,读者可以自行选择适合的定义来使用。

最近评论