






2
Nov
利用CUR分解加速交互式相似度模型的检索
By 苏剑林 | 2022-11-02 | 55482位读者 |文本相似度有“交互式”和“特征式”两种做法,想必很多读者对此已经不陌生,之前笔者也写过一篇文章《CoSENT(二):特征式匹配与交互式匹配有多大差距?》来对比两者的效果。总的来说,交互式相似度效果通常会好些,但直接用它来做大规模检索是不现实的,而特征式相似度则有着更快的检索速度,以及稍逊一筹的效果。
因此,如何在保证交互式相似度效果的前提下提高它的检索速度,是学术界一直都有在研究的课题。近日,论文《Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization》提出了一份新的答卷:CUR分解。
问题分析 #
在检索场景下,我们一般有一个数量巨大的待检索集$\mathcal{K}$,不失一般性,我们可以假设$\mathcal{K}$是恒定不变的。检索的任务是对于任意的请求$q\in\mathcal{Q}$,找出$\mathcal{K}$中与$q$最相关的若干个结果$k$。交互式相似度模型是直接训练了一个相关性的打分函数$s(q,k)$,理论上我们可以对任意$k\in\mathcal{K}$计算$s(q,k)$,然后进行降序排列。但这意味着每次检索的计算量都是$\mathcal{O}(|\mathcal{K}|)$,而且中间计算结果无法缓存,所以成本是难以接受的。
计算量可以接受的是具有矩阵分解形式的相似度,对于单个样本来说,就是基于内积的相似度及其变体,经典的实现是$q,k$经过编码器$\boldsymbol{E}$编码为两个向量$\boldsymbol{E}(q),\boldsymbol{E}(k)$,然后算内积$\boldsymbol{E}(q)^{\top}\boldsymbol{E}(k)$,这就是特征式相似度。这样的方案有几个特点:1、所有的$\boldsymbol{E}(k)$可以实现算好并缓存;2、$\boldsymbol{E}(q)$跟所有的$\boldsymbol{E}(k)$算内积可以转化为矩阵乘法,可以充分并行快速计算;3、还可以通过Faiss等工具借助近似算法进一步检索速度。
所以,要加速交互式相似度的检索速度的思路,就是将它转化为矩阵分解的形式,比较经典的实现方案就是用一个特征式相似度模型去蒸馏学习交互式相似度的效果。Google这篇论文的精巧之处在于,不引入任何新的模型,直接在原本交互式相似度模型的基础上利用CUR分解来实现加速,该方案被命名为ANNCUR。
矩阵分解 #
CUR分解是矩阵分解的一种,而说到矩阵分解,很多读者第一反应可能是SVD,但事实上大家对SVD如此敏感的原因,不是SVD有多么通俗易懂,而是SVD被介绍得多。要说到直观易懂,CUR分解明显更胜一筹。
其实,我们也可以用统一的视角去理解SVD和CUR分解:对于一个打分函数$s(q,k)$,我们希望构造如下近似
\begin{equation}s(q,k) \approx \sum_{u\in\mathcal{U},v\in\mathcal{V}} f(q, u) g(u, v) h(v, k)\label{eq:decom}\end{equation}
一般情况下有限制$|\mathcal{U}|,|\mathcal{V}|\ll |\mathcal{Q}|,|\mathcal{K}|$,使得它成为一个压缩分解。我们可以将$\mathcal{U}$看成是$\mathcal{K}$的一个“代表集”(或者“聚类中心”,反正都只是形象理解,可以随意),相应地$\mathcal{V}$看成是$\mathcal{Q}$的一个“代表集”,那么上述分解就会变得很形象:
$q,k$的打分$s(q,k)$,近似于先将$q$与$\mathcal{K}$的“代表”$u\in \mathcal{U}$算打分$f(q, u)$,然后将$k$与$\mathcal{Q}$的“代表”$v\in \mathcal{V}$算打分$h(v, k)$,然后通过权重$g(u, v)$加权求和。
也就是说,$q$与$k$的直接交互,转化为它们分别与“代表”进行交互,然后再将结果进行加权。这样做的好处很明显,就是当$f,g,h$都确定后,所有的$g(u,v)$、$h(v,k)$都可以事先算好,作为一个矩阵缓存起来,然后每次检索,我们都只需要算$|\mathcal{U}|$次$f(q,u)$,然后再执行一次矩阵乘法(基于内积检索),所以检索的计算量从$\mathcal{O}(|\mathcal{K}|)$转化为$\mathcal{O}(|\mathcal{U}|)$(借助Faiss等工具,基于内积的检索可以近似优化到$\mathcal{O}(1)$,因此可以忽略)。
假设请求集$\mathcal{Q}$也是有限的,那么所有的$s(q,k)$就构成一个$|\mathcal{Q}|\times |\mathcal{K}|$的矩阵$\boldsymbol{S}$,而相应地$f(q, u),g(u, v),h(v, k)$分别对应于$|\mathcal{Q}|\times |\mathcal{U}|$的矩阵$\boldsymbol{F}$、$|\mathcal{U}|\times |\mathcal{V}|$的矩阵$\boldsymbol{G}$、$|\mathcal{V}|\times |\mathcal{K}|$的矩阵$\boldsymbol{H}$,式$\eqref{eq:decom}$就变成矩阵分解:
\begin{equation}\begin{array}{ccccc}
\boldsymbol{S} & \approx & \boldsymbol{F} & \boldsymbol{G} & \boldsymbol{H} \\
\in\mathbb{R}^{|\mathcal{Q}|\times |\mathcal{K}|} & & \in\mathbb{R}^{|\mathcal{Q}|\times |\mathcal{U}|} & \in\mathbb{R}^{|\mathcal{U}|\times |\mathcal{V}|} & \in\mathbb{R}^{|\mathcal{V}|\times |\mathcal{K}|}
\end{array}\label{eq:m-decom}\end{equation}
CUR分解 #
如果将$\boldsymbol{G}$限制为对角矩阵,而$\boldsymbol{F}$、$\boldsymbol{H}$不做特殊限制,那么对应的分解就是SVD。SVD相当于虚拟出了若干个“代表”出来,使得最终的拟合效果会比较好,但这样由算法自行构造出来的“代表”,我们很难理解它的具体含义,也就是可解释性差点。
CUR分解则更直观一些,它认为“代表”应该是原来群体之一,也就是从$\mathcal{Q},\mathcal{K}$的“代表”应该从它们自身集合挑出来的子集,即$\mathcal{U}\subset \mathcal{K}, \mathcal{V}\subset\mathcal{Q}$。这样一来,$(q,u)$、$(v,k)$就是原来的$(q,k)$之一,因此可以沿用$(q,k)$的打分函数$s$,即
\begin{equation}s(q,k) \approx \sum_{u\in\mathcal{U},v\in\mathcal{V}} s(q, u) g(u, v) s(v, k)\end{equation}
于是,待定的函数就只有$g(u,v)$了。从矩阵分解的角度来看,此时式$\eqref{eq:m-decom}$中的$\boldsymbol{F}$就是$\boldsymbol{S}$的若干列组成的子矩阵,$\boldsymbol{H}$就是$\boldsymbol{S}$的若干行组成的子矩阵,要计算的就剩下矩阵$\boldsymbol{G}$。$\boldsymbol{G}$的计算也很直观,我们先考虑一个非常特殊的情形,$\mathcal{U}=\mathcal{K},\mathcal{V}=\mathcal{Q}$且$|\mathcal{Q}|=|\mathcal{K}|$,此时CUR分解为$\boldsymbol{S}\approx \boldsymbol{S}\boldsymbol{G}\boldsymbol{S}$,$\boldsymbol{S}$、$\boldsymbol{G}$都是方阵。由于此时已经取了$\mathcal{Q},\mathcal{K}$全体作为代表,我们自然希望此时是$=$而不是$\approx$,取$=$的话,可以直接解得$\boldsymbol{G} = \boldsymbol{S}^{-1}$。
然而,这意味着$\boldsymbol{S}$要是可逆的,但一般情况下未必成立。这时候要将矩阵的逆运算进行推广,我们称为“伪逆”,记为$\boldsymbol{G}=\boldsymbol{S}^{\dagger}$。特别地,伪逆对于非方阵也有定义,因此当$|\mathcal{Q}|\neq|\mathcal{K}|$时,同样可以解得$\boldsymbol{G}=\boldsymbol{S}^{\dagger}$。最后,当$\mathcal{U}\neq\mathcal{K}$或$\mathcal{V}\neq\mathcal{Q}$时,结果也类似的,只不过求伪逆的矩阵换成$\boldsymbol{F}$与$\boldsymbol{H}$的交集矩阵$\boldsymbol{F}\cap\boldsymbol{H}$(即$\boldsymbol{S}$的若干行、若干列交集的元素拼成的$\mathcal{U}\times \mathcal{V}$矩阵):
\begin{equation}
\boldsymbol{S} \approx \boldsymbol{F} (\boldsymbol{F}\cap \boldsymbol{H})^{\dagger}\boldsymbol{H}\end{equation}
整个过程如下图所示:

CUR分解示意图
加速检索 #
其实本文也不是第一次涉及CUR分解,去年初的文章《Nyströmformer:基于矩阵分解的线性化Attention方案》介绍的Nyströmformer,其实也是基于CUR分解思想来设计的,原始论文还花了不少的篇幅来介绍CUR分解。ANNCUR则是利用CUR分解来做检索加速,由此可见CUR的应用也很广泛。
加速的原理刚才已经稍微提及过了,现在再来总结一下。首先,我们分别挑若干个有代表的$q\in \mathcal{V}\subset \mathcal{Q}$和$k\in \mathcal{U}\subset \mathcal{K}$,算出它们两两打分构成矩阵$\boldsymbol{F}\cap\boldsymbol{H}$,求伪逆后得到矩阵$\boldsymbol{G}$,然后提前算好$q\in \mathcal{V}$与$k\in \mathcal{K}$的打分矩阵$\boldsymbol{G}$,把$\boldsymbol{G}\boldsymbol{H}$存起来。最后,对于每一个需要查询的$q$,与每一个$k\in \mathcal{U}$都算打分,得到一个$|\mathcal{U}|$维向量,然后将这个向量与缓存起来的矩阵$\boldsymbol{G}\boldsymbol{H}$相乘,就得到了$q$与每一个$k\in \mathcal{K}$的打分向量了。
ANNCUR的大致原理就是这样,具体的细节大家可以自行阅读原论文,比如交互式相似度模型换成论文说的 [EMB]-CE 版本效果会更好等。可能有读者想问“有代表的$q,k$要怎么选?”,事实上,大多数情况下都是随机选的,这就留下了一些提升空间,比如可以聚类后选最接近聚类中心的那个,这些就看大家自由发挥了。另外要指出的是,CUR分解本身只是一种近似,它肯定有误差,所以该加速方案主要是为检索场景设计的,检索场景的特点是比较在乎topk的召回率,而不是特别要求top1的精确率,我们可以用CUR分解加速来召回若干个结果后,再用精确的$s(q,k)$做一次重排序来提高准确度。
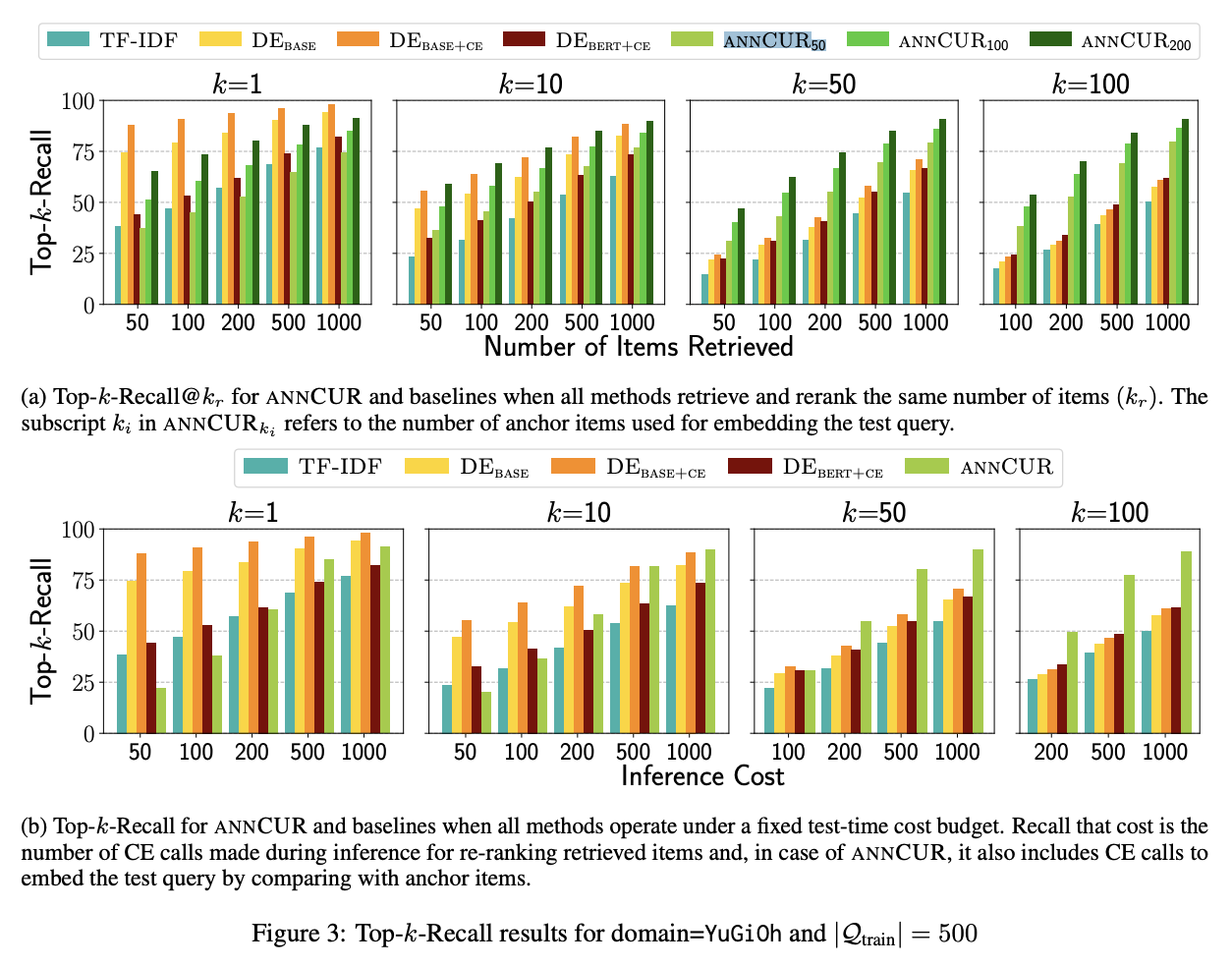
ANNCUR的部分实验结果图
文章小结 #
本文回顾了矩阵分解中的CUR分解,并介绍了它在加速交互式相似度检索方面的应用。
转载到请包括本文地址:https://kexue.fm/archives/9336
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Nov. 02, 2022). 《利用CUR分解加速交互式相似度模型的检索 》[Blog post]. Retrieved from https://kexue.fm/archives/9336
@online{kexuefm-9336,
title={利用CUR分解加速交互式相似度模型的检索},
author={苏剑林},
year={2022},
month={Nov},
url={\url{https://kexue.fm/archives/9336}},
}

November 4th, 2022
为什么不可以将K作为矩阵存储起来,这样就可以直接进行矩阵计算加速了
你怕是对交互式相似度有什么误会?
November 9th, 2022
不错
November 9th, 2022
在线检索是直接q和GH相乘么,当item很多的时候是不是性能也不太行呢。看原文说可以『along with an off-theshelf nearest-neighbor search method for maximum
inner-product search』,不过不太懂具体要怎么应用mips呢
好像懂了,假设k个种子item,N个候选item,GH就是k*N,按列来看,就是N个k维向量,相当于N个item向量,扔到annlib里去就行了,而输入的q也是一个k维向量,就可以ann了
是的
November 10th, 2022
F∩H(即S的若干行、若干列交集的元素拼成的矩阵)矩阵的交集该怎么算呢
本文的“CUR分解示意图”,应该体现得很清楚了吧?$\boldsymbol{F}$(橙色)与$\boldsymbol{H}$(黄色)的交集就是紫色部分,很直观呀。
November 26th, 2022
[...]利用CUR分解加速交互式相似度模型的检索[...]
June 29th, 2023
[...]利用CUR分解加速交互式相似度模型的检索[...]
September 20th, 2023
[...]利用CUR分解加速交互式相似度模型的检索[...]