






17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 95795位读者 |两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
检索任务 #
说到检索任务,想必大家都不陌生,除了常规的相似问检索外,NLP中还有很多任务都可以视为检索,比如抽取式阅读理解、实体链接甚至基于知识图谱的问答,等等。
以相似问检索为例,常规的检索系统的流程为:
1、训练句子编码模型,这通常包含复杂的负样本构建流程,负样本质量直接影响到最终效果;
2、将每个句子编码为向量,存到诸如Faiss的向量检索库中,这一步通常需要消耗相当大的空间;
3、将查询句子编码为向量,然后进行检索,返回Topk结果及其相似度。
如果现在告诉你,有一个做检索的新方案,可以不用花心思挑选负样本,也不用消耗极大内存的向量检索库,最终效果和速度也不差于旧方案,那你会不会迫不及待想要尝试一下?没错,这就是本文的主角“Seq2Seq+前缀树”了。
Seq2Seq #
首先,让我们抛开各种繁琐的细枝末节,想一想检索任务究竟在做什么。对于相似问检索来说,我们输入一个问句,希望输出数据库中与之最相近的句子;对于实体链接来说,我们输入一个包含该实体的句子,希望输出知识库中能正确诠释该实体的实体名或者编号;等等。
抛开某些约束规则不说,可以发现这些任务本质上都可以抽象为:
输入一个句子,输出另一个句子。
这不正是Seq2Seq最擅长的工作了嘛!所以用Seq2Seq做不是一件很自然的事情?当然,有读者会说我要输出的是数据库里边已有的一个句子呀,Seq2Seq要是“溢出”(解码出了数据库不存在的句子)了怎么办?这时该前缀树上场了,我们可以利用前缀树约束解码过程,保证生成的结果在数据库中,这一点我们等会细说。
没有了“溢出”的顾虑,我们将会发现Seq2Seq的做法真的是集诸多优点于一身,比如:
1、训练Seq2Seq模型只需要输入和目标,这也就是说我们只需要正样本,免除了构建负样本的烦恼,或者说它是将所有其他句子都当成负样本了;
2、Seq2Seq是直接解码出目标句子,省去了句向量的储存和检索,也就免除了Faiss等工具的使用了;
3、Seq2Seq包含了目标句子与输入句子之间Token级别的交互,理论上比基于内积的向量检索能做到更精细的对比,从而有更好的检索效果。
前缀解码 #
现在我们来细说一下利用前缀树来约束解码的过程,看一下它是如何保证输出结果在数据库中的。我们假设数据库有如下几句话:
明月几时有
明天会更好
明天下雨
明天下午开会
明天下午放假
明年见
今夕是何年
今天去哪里玩
那么我们将用如下的前缀树来存储这些句子:
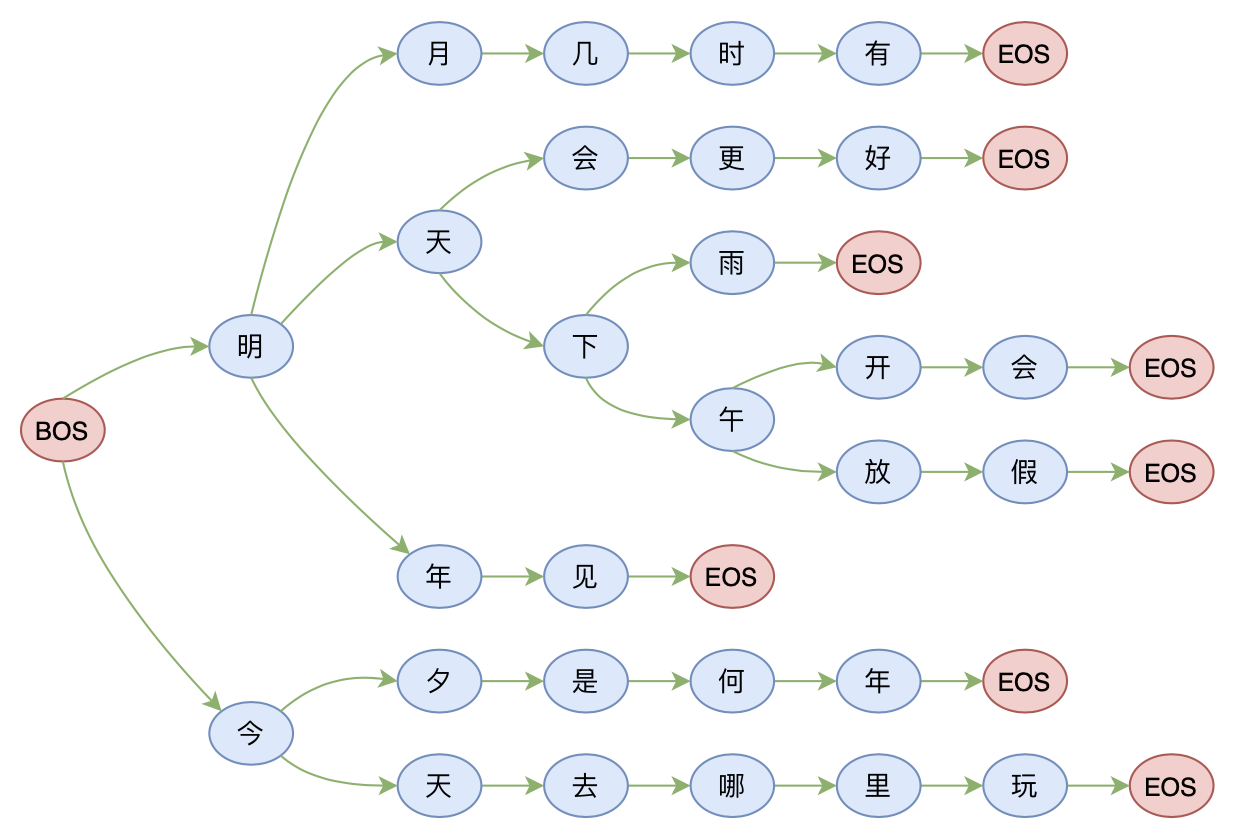
前缀树示意图:本质上是序列的一种压缩表示
其实就是从左往右地把相同位置的相同token聚合起来,树上的每一条完整路径(以[BOS]开头、[EOS]结尾)都代表数据库中的一个句子。之所以叫“前缀树”,是因为利用这种树状结构,我们可以很快地查找到以某个前缀开头的字/句有哪些。比如从上图中我们可以看到,第一个字只可能是“明”或“今”,“明”后面只能接“月”、“天”或“年”,“明天”后面只能接“会”或“下”,等等。
有了前缀树,我们约束Seq2Seq解码就不困难了,比如第一个字只能是“明”或“今”,那么在预测第一个字的时候,我们可以把模型预测其他字的概率都置零,这样模型只可能从这两个字中二选一;如果已经确定了第一个字,比如“明”,那么我们在预测第二个字的时候,同样可以将“月”、“天”或“年”以外的字的概率都置零,这样模型只可能从这三个字中选一个,结果必然是“明月”、“明天”、“明年”之一;依此类推,通过将不在前缀树上的候选token置零,保证解码过程只走前缀树的分支,而且必须走到最后,这样解码出来的结果必然是数据库中已有的句子。
相比常规的向量检索方案,“Seq2Seq+前缀树”的方案用前缀树代替了要储存的检索向量,而前缀树本质上是原始句子的一种“压缩表示”,所以不难想象前缀树所需要的储存空间要比稠密的检索向量要少得多。在Python中,实现前缀树比较简单的方案就是利用字典结构来实现嵌套,具体例子可以参考后面的KgCLUE的代码。
KgCLUE #
实践是检验真理的唯一标准,现在我们就利用“Seq2Seq+前缀树”的方案实现一个KgCLUE的baseline,以检验它的有效性。
任务简介 #
KgCLUE是CLUE组织最近推出的一个中文知识图谱问答的评测任务,数据比较规范,适合科研实验测试。具体来说,它以约2000万个三元组为知识库,每个三元组是$(S, P, O)$的格式(Subject-Predicate-Object),如下图:

KgCLUE知识库截图
然后它还提供了一批标注语料供训练,每个样本是简单的问题加答案的形式,其实问题本质上都可以抽象为“$S$的$P$是什么”,而答案则是对应的三原则$(S,P,O)$,如下图:
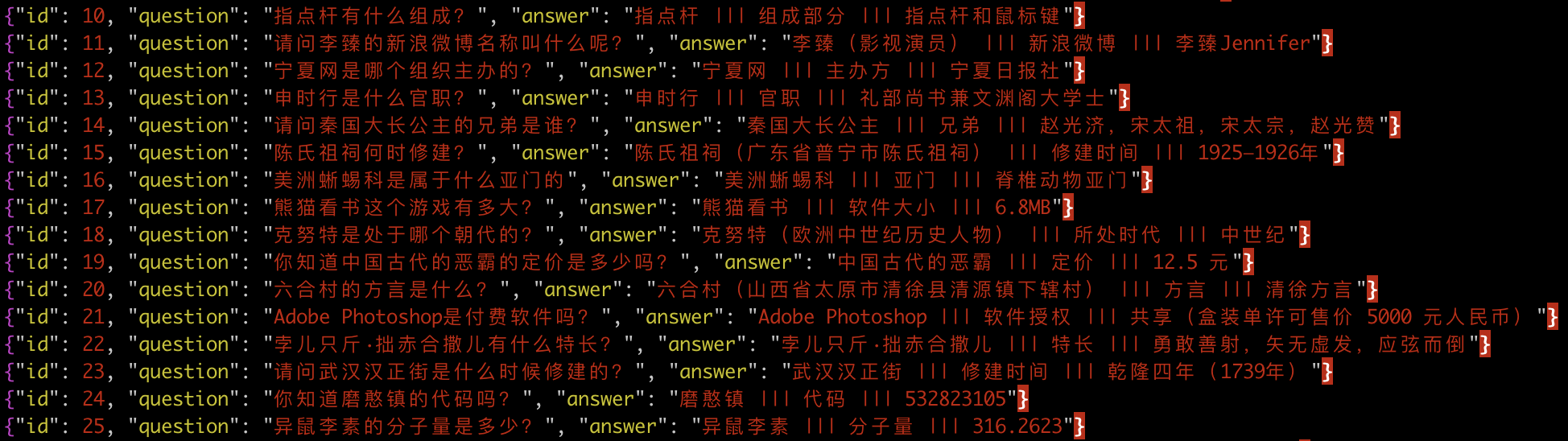
KgCLUE标注语料截图
原则上来说,只要确定了$(S,P)$,就可以从知识库里边抽取出对应的$O$,所以我们主要的任务,就是要从问题中解析出正确的$S$和$P$出来。
一般思路 #
完成这个任务比较朴素的方法是分两步进行:第一步训练一个标注模型负责从问题中抽取$S$,然后从知识库中找出该$S$对应的所有三元组,将$S$分别每一个$P$组合起来,逐一与问题算相似度,所以第二步也就是一个相似度模型。
但要注意的是,知识库里边可能存在很多同名实体,比如“牛郎织女”,可能指神话故事,也可能指一本书或者一首歌等,为了对它们进行区分,知识库里边还有一个“义项(Meaning)”的概念,用来注明该名词的具体指代,在KgCLUE的知识库中,义项是通过括号的方式补充在Subject后面,比如“牛郎织女(中国著名民间故事)”、“牛郎织女(2015年东方出版社出版的图书)”等,但如果直接从问题抽取的话,通常只能抽取到义项以外的部分,即“牛郎织女”,所以我们实际处理时,通常会将它们分隔开,即将每条知识视为一个四元组$(S, M, P, O)$而不是三元组。
根据给定问题来确定Subject究竟属于哪个Meaning,这就是“实体链接”问题,是知识图谱问答的必要步骤。但如果局限在当前的KgCLUE任务中,由于语料本身不大,对于分两步的模型来说,我们可以认为实体链接这一步整合到了相似度模型中,而不单独进行实体链接任务。
本文方案 #
如果用“Seq2Seq+前缀树”来做的话,那么模型训练方面将会变得非常简单。
具体来说,我们就只需要一个Seq2Seq模型,然后将问题当作Seq2Seq的输入,将$(S,P,M)$用[SEP]连接起来作为目标,进行正常的Seq2Seq训练就行了。这里的一个技巧是按照$(S,P,M)$的顺序进行拼接,要比按照$(S,M,P)$的顺序的最终效果要好很多(8~10个百分点),这是因为问题来预测$S,P$要比预测$M$都更容易,我们要先把容易预测的预测出来,以减少候选答案的数量。
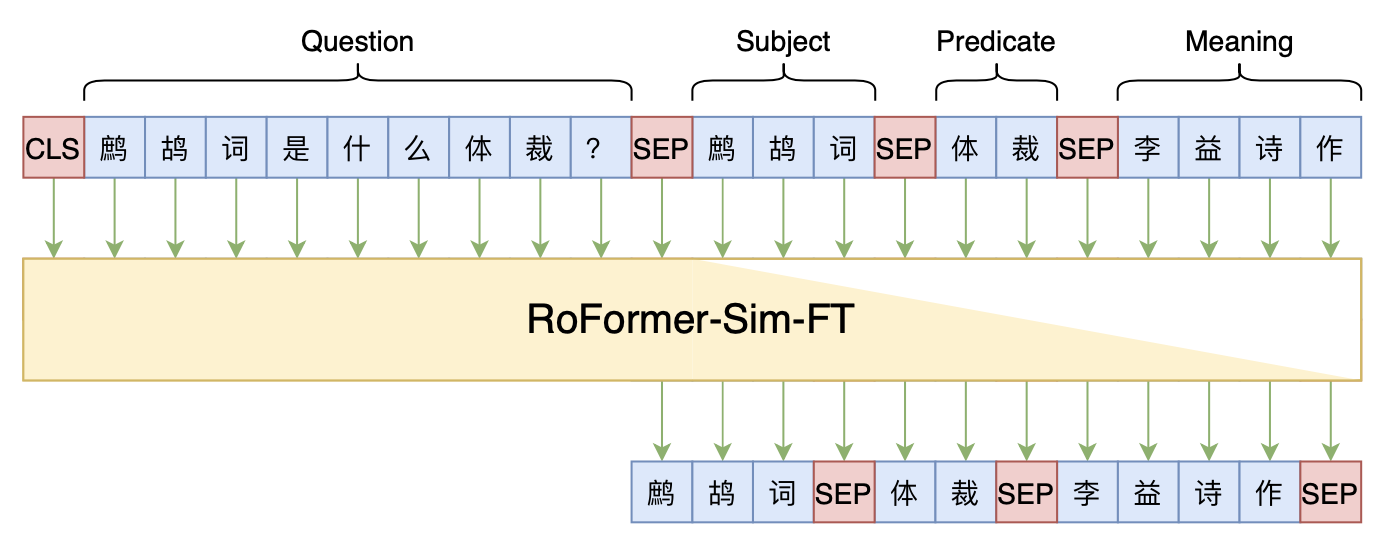
本文baseline模型示意图
在参考代码中,我们所用的Seq2Seq模型是《SimBERTv2来了!融合检索和生成的RoFormer-Sim模型》、《用开源的人工标注数据来增强RoFormer-Sim》中介绍的RoFormer-Sim-FT模型,它是利用UniLM模型预训练过的相似问生成模型,经过对比,用RoFormer-Sim-FT相比直接用RoFormer,效果至少提升2个百分点。这也说明相似问生成是该方案的一种有效的预训练方式。
错例分析 #
解码的时候,我们先把所有的$(S,P,M)$建立成前缀树,然后按照前缀树进行解码,就保证了解码结果必然落到知识库的某个三元组中,从而能够合理地输出结果。详细的前缀解码步骤前面已经介绍过了,这里就不再细说。
然而,观察bad case的时候,发现模型有可能会出现一些非常“简单”的bad case,比如“海浦东香格里拉大酒店离火车站有多远?”,正确的$(S,P)$应该是“(上海浦东香格里拉大酒店, 火车站距离)”,但模型却生成了“(上海浦东香格里拉大酒店, 酒店星级)”;有时候问“XXX讨厌什么”,结果模型却生成了“(XXX, 喜欢)”;有时候问“XXX主要讲什么课程”,正确的答案应该是“(XXX, 主讲课程)”,结果模型却生成了“(XXX, 主要成就)”。也就是说,模型似乎会在一些字面上看起来非常简单的问题上犯错(生成错误的$P$)。
经过思考,笔者认为这种bad case本质上是Seq2Seq本身的固有缺点所导致的,主要包含两方面:1、训练时的Exposure Bias问题;2、解码时Beam Search的贪心问题。首先,由于Seq2Seq在训练时是已知上一真实标签的,这会弱化训练难度,导致模型的“全局观”不够;其次,解码哪怕用了Beam Search,本质上也是贪心的,很难做到综合后几个token来预测当前token。比如刚才的“XXX主要讲什么课程”一例,模型生成$P$的时候,首先就很贪心地生成“主要”两个字,然后按照前缀树的约束,“主要”后面只能接“成就”了(因为“主讲课程”前两个字是“主讲”),所以就出来了“主要成就”。
理论上,应用一些缓解Seq2Seq的Exposure Bias问题的策略,比如《Seq2Seq中Exposure Bias现象的浅析与对策》、《TeaForN:让Teacher Forcing更有“远见”一些》等,应该是对此问题有帮助的。这些方法比较多,复杂度也有所不一样,就留给读者自行尝试了。
“前瞻”策略 #
这里笔者提出另一个能够缓解此问题的“前瞻”策略。
在“Seq2Seq+前缀树”方案中,我们的Seq2Seq不是真的要去生成任意文本,而是在前缀树的约束下做本质上是检索的操作,所以生成了$S$之后,我们可以知道后续容许的$P$,并且一般来说后续容许的$P$不会太多,所以我们可以直接逐一枚举容许的$P$,通过$P$对问题的覆盖程度,来调整当前token的预测结果。
具体的步骤是,假设当前问题$Q$已经解码出$S$,以及$P$的前$t-1$个字符$P_{< t}$,现在要预测$P$的第$t$个字$P_t$,那么我们根据$S,P_{< t}$检索出所有可能的$P^{(1)},P^{(2)},\cdots,P^{(n)}$,每个$P^{(k)}$可以表示为$[P_{< t},P_t^{(k)},P_{> t}^{(k)}]$的格式;然后我们用一个覆盖度函数,这里直接用最长公共子序列长度$\text{LCS}$,来算出每个候选的$P$所能带来的覆盖度增益:
\begin{equation}\Delta^{(k)} = \text{LCS}(P^{(k)},Q) - \text{LCS}(P_{< t},Q)\end{equation}
该增益视为将$P_t$预测为$P_t^{(k)}$的“潜在收益”,如果多个$P_t^{(k)}$对应同一个字,那么就取最大者。
这样,对于$P_t$的所有候选值$k$,我们都计算出来了一个“潜在收益”$\Delta^{(k)}$,我们可以调整Seq2Seq的预测概率,来强化一下$\Delta^{(k)}$的token。笔者用的强化规则为:
\begin{equation}p_k \leftarrow p_k^{1/(\Delta^{(k)} + 1)}\end{equation}
也就是如果潜在收益是$\Delta^{(k)}$,那么对应的概率就开$\Delta^{(k)}+1$次方,然后重新归一化,由于概率是小于1的,所以开方起到了放大的作用。该策略带来的收益,大概是4个百分点的提升。其他强化规则也可以尝试,这部分主观性比较强,就不一一列举了。
效果分析 #
本文的代码分享在:
最终效果是:
$$\begin{array}{c|ccc}
\hline
& \text{F1} & \text{EM} & \text{平均} \\
\hline
\text{valid} & 89.20 & 91.04 & 90.12\\
\text{test} & 90.25 & 92.48 & 91.37\\
\text{线上} & 86.03 & 88.45 & 87.24\\
\hline
\end{array}$$
目前排行榜上排名第二:
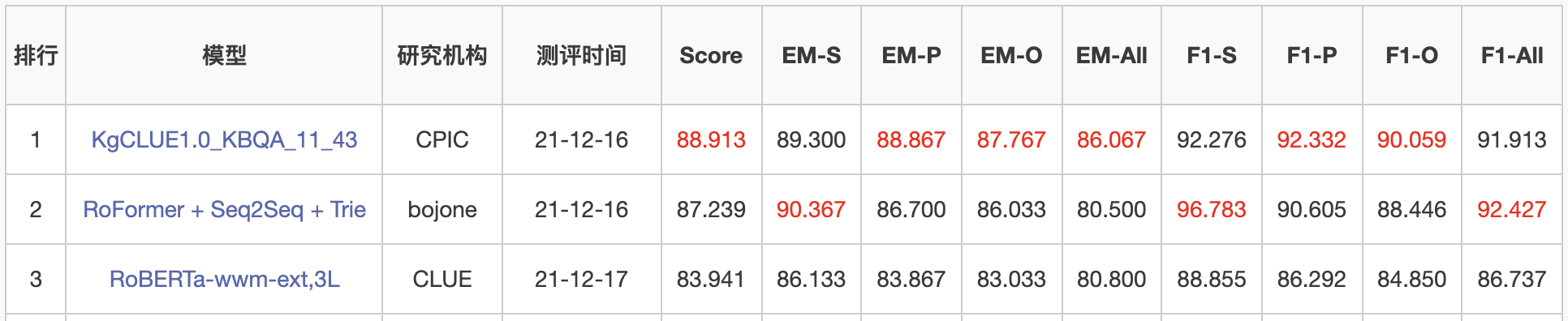
当前KgCLUE榜单截图
调试历程大概是:
1、开始用RoFormer+UniLM按照$(S,M,P)$顺序预测,验证集EM大约是70多;
2、然后改为$(S,P,M)$的顺序之后,验证集能做到82了;
3、接着预训练模型换用RoFormer-Sim-FT后,提升到84~85;
4、最后加上“前瞻”策略,就做到当前的89了。
一些缺点 #
至此,我们已经比较详细地介绍了“Seq2Seq+前缀树”方案,并且以KgCLUE为例分享了一个baseline给大家。总的来说,“Seq2Seq+前缀树”有它的明显优点,并且能在检索任务上取得有竞争力的效果,但其中依然有一些问题值得思考。
最典型的问题,就是Seq2Seq本身的固有问题,这我们在前面已经提过了。虽然“前瞻”策略已经能给我们带来不错的提升,但相应的问题依然没有完全解决,如何更自然地解决该问题,或者设计更自然的解码规则,依然是值得思考,没有标准答案。此外,前面提到的解决Exposure Bias问题的通用策略,笔者也还没有尝试,不确定具体效果如何。
还有一个问题,就是“Seq2Seq+前缀树”的方案,是靠模型把结果“生成”的,而一旦遇到生僻字被识别为[UNK],那么大概率就会失败了,尤其是如果S的第一个字就是[UNK],那么几乎都会失败,所以如何更好地解决[UNK]问题,是一个值得研究的问题。当然,也可以尝试传统的Copy机制,这就看个人的审美了。
最后,“Seq2Seq+前缀树”或许可以在评测指标上取得不错的效果,但它对于工程来说,有一个不大有好的特点,就是修正bad case会变得比较困难,因为传统方法修正bad case,你只需要不断加样本就行了,而“Seq2Seq+前缀树”则需要你修改解码过程,这通常困难得多。
文章总结 #
本文介绍了检索模型的一种新方案——“Seq2Seq+前缀树”,并以KgCLUE为例给出了一个具体的baseline。“Seq2Seq+前缀树”的方案有着训练简单、空间占用少等优点,也有一些不足之处,总的来说算得上是一种简明的有竞争力的方案。
转载到请包括本文地址:https://kexue.fm/archives/8802
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Dec. 17, 2021). 《Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例) 》[Blog post]. Retrieved from https://kexue.fm/archives/8802
@online{kexuefm-8802,
title={Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)},
author={苏剑林},
year={2021},
month={Dec},
url={\url{https://kexue.fm/archives/8802}},
}

December 17th, 2021
前排
December 17th, 2021
1
December 18th, 2021
牛逼就完事了
December 18th, 2021
苏神家里有几个gpu卡
我自己就只有一个1060,剩下的都是公司的卡。
December 20th, 2021
太有趣了
December 22nd, 2021
苏神,要是库中的句子(或三元组)非常大,数以亿计,比起传统的检索方式(倒排索引等),用本文所述的方法会不会导致效率低下?
首先你要搞清楚,我们这里说的检索任务,都是指用深度学习来说效果才比较好的检索任务,如果倒排索引够用了,Elasticsearch够用了,那还折腾这干嘛?所以,“Seq2Seq+前缀树”要对标的,是传统的稠密向量检索任务,不是像倒排索引这样的稀疏向量检索。
此外,理论上“Seq2Seq+前缀树”的检索时间是固定的,也就是说不管数据库中有多少句子,其预测时间都是常数级别。待检索句子的多少,影响的是前缀树的空间占用,基本不影响检索速度。
好的,学习到了。
December 23rd, 2021
感觉思路很像强化里的action mask操作,用专家知识或者是另一个有监督模型去除掉不合理的输出,在剩下的可选项里面找出置信度最高的作为输出。
December 27th, 2021
苏神,训练过程按照正常的seq2seq训练,预测过程使用前缀解码。是不是加大了Exposure Bias 的问题。
我觉得如果训练阶段也加入mask,才是加大了Exposure Bias问题吧。Exposure Bias是因为训练阶段为了训练上的方便,提前预知了(上一步的)标签信息,如果训练阶段加入mask,不是预知了更多的标签信息?
December 29th, 2021
我想问一个很蠢的问题。这个是不是不适合CV的检索,比如reid。文本是因为每个字是离散的且可以穷尽的,所以总会形成这个前缀树。如果同比image的patch的话应该就不能了吧。
图像目前的一个半主流的方向是通过VQ-VAE类似的方案,将图像转换为离散序列然后再做,所以如果是这个半主流的方向,还是可以用前缀树的。
January 1st, 2022
内存32G跑不了,加载trie树树不够
那可能是我估计少了~