






25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 180501位读者 |机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
先看效果 #
输入篇章:世界第二高山峰是乔戈里峰,位于中国境内。
生成问答:世界第二高山峰叫什么名字? 乔戈里峰
乔戈利峰是世界第几高峰 第二输入篇章:7月28日,泰国将迎来十世王玛哈·哇集拉隆功国王的68岁诞辰。
生成问答:泰国的十世王是谁 玛哈·哇集拉隆功国王
泰国的十世王玛哈·哇集拉隆多少岁? 68岁
泰国的玛哈·哇集拉隆功国王的生日是哪一天? 7月28日
玛哈·哇集拉隆功国王是哪个国家的 泰国输入篇章:泼水节,亦称宋干节,已有700年的历史,是傣族(中国)、德昂族最盛大的传统节日。
生成问答:泼水节又称为什么 宋干节
泼水节是我国哪一民族一年中最盛大的节日? 傣族
泼水节有多少年历史了? 700年
思路分析 #
本文的目标是完全端到端地实现“篇章 → 答案 + 问题”,包括答案的选取也是由模型自动完成,不需要人工规则。其实说起来也很简单,就是用“BERT + UniLM”的方式来构建一个Seq2Seq模型(UniLM的Attention Mask,加上BERT的预训练权重),如果读者还不了解UniLM,欢迎先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
笔者之前在文章《万能的seq2seq:基于seq2seq的阅读理解问答》中也给出过通过Seq2Seq模型来做阅读理解的实现,即直接用Seq2Seq模型来构建$p\big(\text{答案}\big|\text{篇章},\text{问题}\big)$,图示如下:
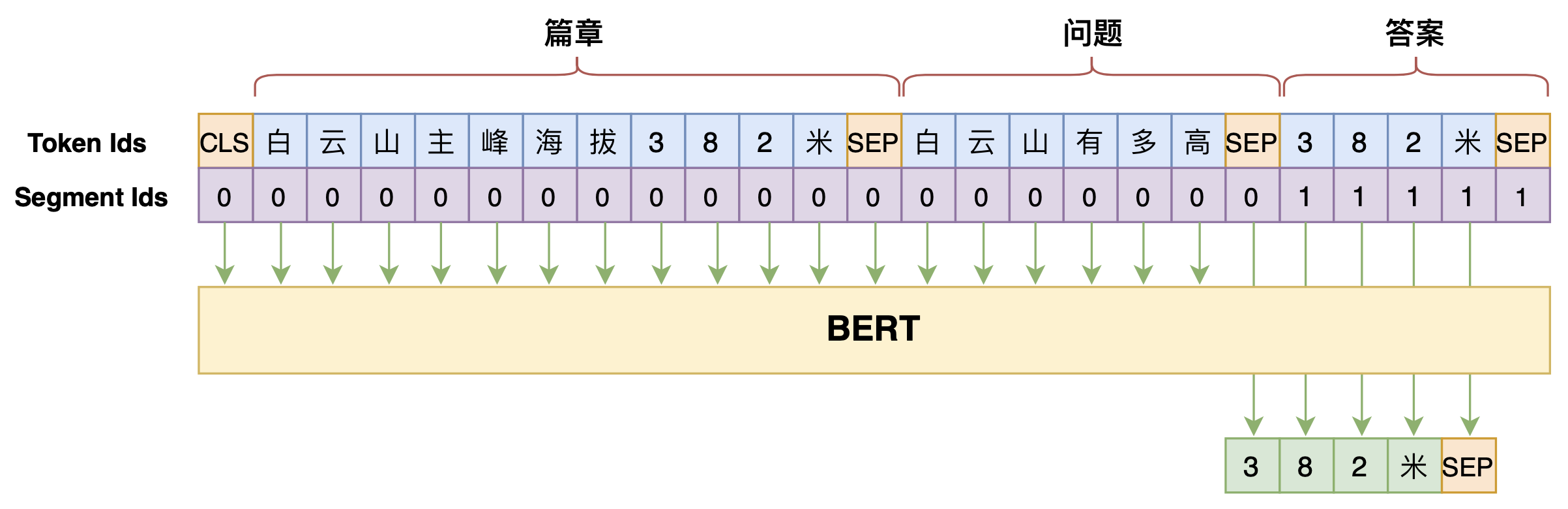
用Seq2Seq的思路做阅读理解
事实上,在上述模型的基础上稍微改动一下,将问题也列入生成的目标之中,就可以实现问答对生成了,即模型变为$p\big(\text{问题},\text{答案}\big|\text{篇章}\big)$,如下图:
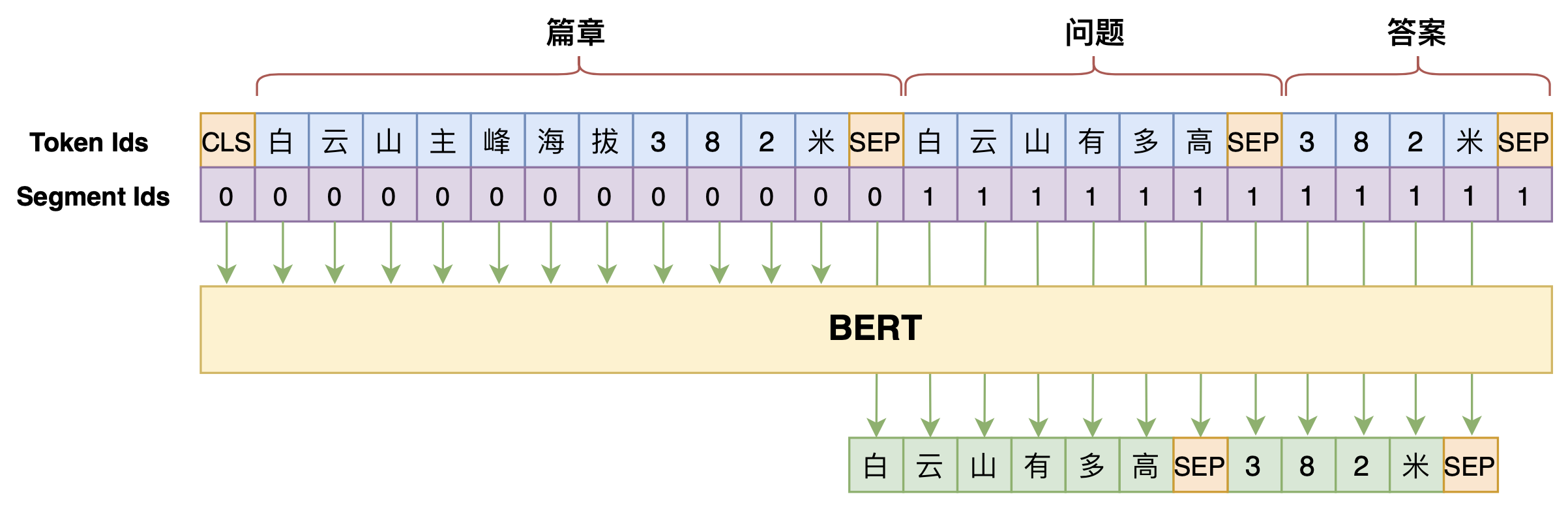
稍微修改一下,用来做问答对生成
但是,直觉上不难想到“篇章 → 答案”、“篇章 + 答案 → 问题”的难度应该是低于“篇章 + 问题 → 答案”的,所以我们将问题和答案的生成顺序调换一下,变为$p\big(\text{答案},\text{问题}\big|\text{篇章}\big)$,最终的效果会更好:
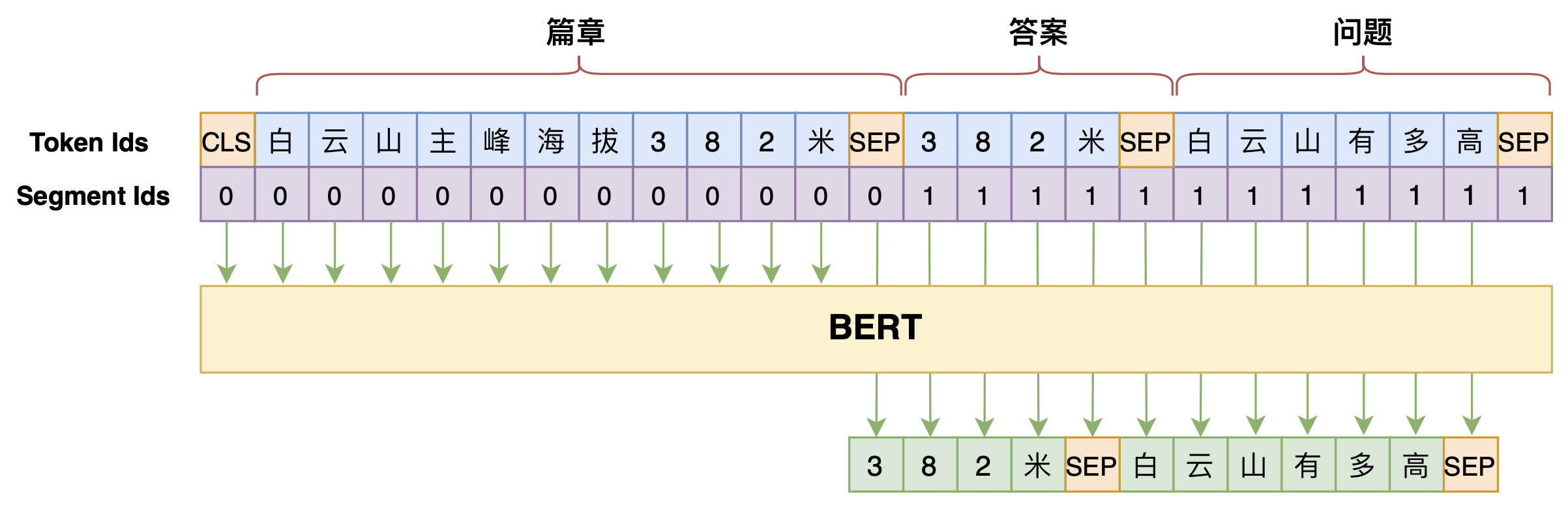
先生成答案,再生成问题,效果更好些
实现分析 #
模型就介绍到这里了,其实也没什么好说的,就是确定好哪些是输入、哪些是输出,然后“BERT + UniLM”套上去就行了。下面是笔者的参考实现:
这里值得讨论的是解码的思路。一般的Seq2Seq模型,解码到一个[SEP]就结束了,而本文的模型需要解码到两个[SEP]才能结束,截止到第一个[SEP]的是答案,而两个[SEP]之间的则是问题。理论上来说,从给定篇章中我们可以构建很多问答对,换句话说目标不是唯一的,所以我们不能用Beam Search之类的确定性解码算法,而是要用随机解码算法(相关概念可以参考《如何应对Seq2Seq中的“根本停不下来”问题?》中的“解码算法”一节)。
但问题是,如果完全使用随机解码算法,那么生成的问题会过于“天马行空”,也就是可能会出现一些跟篇章无关的内容,比如篇章是“我国火星探测器天问一号发射成功”,生成的问题可能是“我国第一颗人造卫星是什么”,虽然相关,但是过于发散了。所以,这里建议使用一个折中的策略:用随机解码来生成答案,然后用确定性解码来生成问题,这样能尽量保证问题的可靠性。当然,如果读者更关心生成问题的多样性,那么全部使用随机解码也行,反正就自己调试啦。
读者还需要注意的是,上述参考脚本中并没有对答案进行约束,那么生成的答案可能并不是篇章中的片段。毕竟这只是个参考实现,离实用还有一定距离,请有兴趣的读者根据自己的需求自行理解和修改代码。此外,由于问答对构建已经完全变成了一个Seq2Seq问题,所以用来提升Seq2Seq性能的技巧都可以用来提高问答对的生成质量,比如之前讨论过的《Seq2Seq中Exposure Bias现象的浅析与对策》,这些都交给读者自己尝试了。
文章小结 #
本文是一次端到端的问答对生成实践,主要是基于“BERT + UniLM”的Seq2Seq模型来直接根据篇章生成答案和问题,并讨论了关于解码的策略。总的来讲,本文的模型没有什么特殊之处,但是因为借助了BERT的预训练权重,最终生成的问答对质量颇有可圈可点之处。
转载到请包括本文地址:https://kexue.fm/archives/7630
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jul. 25, 2020). 《学会提问的BERT:端到端地从篇章中构建问答对 》[Blog post]. Retrieved from https://kexue.fm/archives/7630
@online{kexuefm-7630,
title={学会提问的BERT:端到端地从篇章中构建问答对},
author={苏剑林},
year={2020},
month={Jul},
url={\url{https://kexue.fm/archives/7630}},
}

July 25th, 2020
苏神您好,UniLM和BERT是两个模型,这里混用是不是会让读者有疑惑?事实上用的就是UniLM吧?
不对,好像是用UniLM的训练方法来fine-tune BERT?感觉更加疑惑了。。
好快的回复~
BERT是一个特定的预训练模型,UniLM我的理解是一种做Seq2Seq的Attention Mask。
当然,英文中UniLM也指代一个特定的预训练模型,但是这个预训练模型并没有中文权重开源,因此我觉得上述称呼至少在中文界不至于引起歧义。
也就是说BERT虽然没有在生成任务上预训练,还能fine-tune出来生成能力?太神奇了!?
是的,可以明显提升生成质量。
嘿嘿,实时跟踪苏神动态,向苏神学习~~~~
July 25th, 2020
我想试一下,请问这个数据要去哪里可以下载到呀
参考脚本已经注明了数据来源。
请教下bert4keras版本0.7.0的from bert4keras.layers import Loss,提示cannot import name 'Loss',是要升级吗?请问这个要对应哪个版本才行呀
升级到最新版本吧。examples下的例子只保证适配最新版本。
July 25th, 2020
在工作中试过标注了2000条webaq的数据,以 篇章+答案-> 问题的方式来实现业务的需求,效果已经很喜人了,不过数量不够,所以最终没上线; 没想到还能用随机解码的方式来生成答案,厉害了真是!
谢谢。直接利用现有的阅读理解语料不就可以构建了吗?为什么还要自己标?
July 27th, 2020
苏神好,看到实践效果里面一篇文章可以生成多个问答对,但是代码里面对答案的random_search的n设置的是1,请问是自行设置这个n值吗?还是从哪里能让它生成足够多的问答对?谢谢!
对同一个passage重复执行qag.generate(passage)
明白~
另外还有两个问题:
1. 苏神你看我理解得对不对哈:先把passage丢进模型生成答案,再把passage+生成的答案丢进模型生成问题,这样子可以理解成模型其实是进行了多任务学习吗?
2. 不是很理解为什么最开始的时候要把一个passage用seps split成多个?
谢谢!
1、就是一个seq2seq任务,哪来的多任务?
2、因为passage太长啊...
August 10th, 2020
我想把苏神您的模型用在英文文本上,请问有什么需要注意的吗
注意理解每一行,确保每一行都是按照英文的标准来的。
September 11th, 2020
苏神,为什么这份代码跑起来显存占用会越来越大呢?一开始正常跑,大概跑了几百个batch,就OOM了。
目测你用了tf 2.x + tf.keras
没有,我的tensorflow版本是tf 1.15.2,但是我的环境里也有keras 2.3.1,不知道程序跑起来默认是keras还是tf.keras?
默认是keras。那就不清楚了,batch_size取小一点试试?
September 15th, 2020
我有一个数据,给了passage和answer,要预测question,然后,我想把你的这个代码改一下,就是,passage和answer对应的segment为0,question对应的segment为1,但是预测模型的时候,总是提示维度不匹配的错误,错误如下:
InvalidArgumentError: Incompatible shapes: [5,157,768] vs. [5,158,768]
[[{{node training_5/Adam/gradients/Embedding-Token-Segment_6/add_grad/BroadcastGradientArgs}}]]
我查了网上的信息,也都只是说维度的问题,我发现错误里提示的Embedding-Token-Segment_6,这个是bert中的某一层,为啥数据已经在训练模型了,bert的中间层会出现维度不匹配。
能帮忙给看下吗
不能。建议:先理解模型原理,然后跑通开源代码,跑通后通过print查看输入格式,然后对比你修改的结果。
我跑通了你给的这个开源代码,可以正常预测,然后,我就尝试修改segment的值,想预测question。
我是不太清楚,为啥bert模型中间层会出现维度问题,这个是要修改bert模型的结构吗,我除了换数据以外,就是修改生成器里的segment对应关系,其它参数都没有改变,tokens_ids和segment_ids的长度一致。
要是适应我的任务,需要修改你的源码吗
“为啥bert模型中间层会出现维度问题”,因为你修改得有误,至于误在哪,我也不知道。
可以肯定的是“只修改segment_ids的内容”是不会导致错误的,不信的话你试试可以在原代码82行【segment_ids += [1] * (len(token_ids) - len(p_token_ids))】后修改segment_ids里边的某些值。
你的理解没有问题,只生成问题的话,只需要修改data_generator的segment_ids以及QuestionAnswerGeneration类。当然也可以连data_generator都不修改,只修改QuestionAnswerGeneration类(相当于训练的时候把答案纳入了预测范围,但是测试的时候不用预测的答案,而是人工指定答案)。
好滴,我明白了,感谢
September 20th, 2020
苏神确认一下跟楼上类似的问题,也是根据文章和答案生成问题,根据博客的理解,在训练阶段是把篇章和答案的segment_id置成0,问题的segment_id置成1,在预测阶段也需要把篇章和答案的segment_id均置成0没错吧?这个看起来和bert置segement_id的方式不一样,有些不大习惯。
对的。
segement_id本身可以根据不同的需求调整的,比如对话模型( https://kexue.fm/archives/7718 )就可以用交错的segement_id。
感谢苏神的解答,苏神的博客内容就是这么硬
September 23rd, 2020
请问下 tensorflow 版本怎么实现 bert + unilm 呢?
苏神能指导下思路吗?
我先把我的思路说下。
我理解的是,把篇章 + Q + A,放在一起作为BERT的输入,中间用SEP隔开,就和上面的图一样,同时把 segment_id 也构造好一起输入。
然后BERT里面的attention层,需要针对A的位置做下三角矩阵的MASK ,把 A 的时序MASK一下。
那bert最后的输出取什么呢,然后怎么做loss?
是把 bert 最后的输出 [batch_size,seq_len,embed_size],直接加个全连接吗,转成[batch_size,seq_len,vocab_size] ? 然后把 篇章和Q 占的 seq_len 的位置输出去掉,保留成 [batch_size,seq_len_A,vocab_size] ,最后和真实的answer做loss?
bert的训练模型之一是mlm,它的最终输出就是[batch_size,seq_len,vocab_size],不需要改,只需要改一下mask就行了。
loss的话,可以保留 篇章和Q 的token,但是算loss的时候根据segment_id把这部分mask掉。
实现的思路跟keras版没有什么差别,请参考下面的class CrossEntropy(Loss)部分:
https://github.com/bojone/bert4keras/blob/master/examples/task_seq2seq_autotitle_csl.py
感谢指导,我试试。
October 11th, 2020
苏神你好,这种bert做seq2seq任务,和其他seq2seq模型相比有什么优势呢?谢谢!
你说相比从零用transformer或者lstm训练一个seq2seq?预训练过的收敛更快、效果更好、需要语料更少啊~