






29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 195198位读者 |在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
数据示例 #
每个数据样本如下:
{
"table_id": "a1b2c3d4", # 相应表格的id
"question": "世茂茂悦府新盘容积率大于1,请问它的套均面积是多少?", # 自然语言问句
"sql":{ # 真实SQL
"sel": [7], # SQL选择的列
"agg": [0], # 选择的列相应的聚合函数, '0'代表无
"cond_conn_op": 0, # 条件之间的关系
"conds": [
[1, 2, "世茂茂悦府"], # 条件列, 条件类型, 条件值,col_1 == "世茂茂悦府"
[6, 0, "1"]
]
}
}
# 其中条件运算符、聚合符、连接符分别如下
op_sql_dict = {0:">", 1:"<", 2:"==", 3:"!="}
agg_sql_dict = {0:"", 1:"AVG", 2:"MAX", 3:"MIN", 4:"COUNT", 5:"SUM"}
conn_sql_dict = {0:"", 1:"and", 2:"or"}然后每个样本都对应着一个数据表,里边包含该表的所有列名,以及相应的数据记录,而原则上生成的SQL语句在对应的数据表上是可以执行的,并且都能返回有效的结果。
可以看到,虽然说是NL2SQL,但事实上主办方已经将SQL语句做了十分清晰的格式化,这样一来这个任务就可以相当大地简化了。比如sel这个字段,其实就是一个多标签分类模型,只不过类别可能会随时变化,因为这里的类别实际上对应着数据表的列,而每个样本的数据表及其含义都不尽相同,所以我们要根据表的列名来动态地编码一个类别向量;至于agg则跟sel一一对应,并且类别是固定的,cond_conn_op则是一个单标签分类问题。
最后的conds相对复杂一些,它需要结合字标注和分类,因为要同时决定哪一列是条件,条件的运算关系,以及条件对应的值,并且要注意的是,条件值并不总是question的一个片段,它有可能是格式化后的结果,比如question里边是“16年”,那么条件值可能是格式化之后的“2016”,不过,由于主办方保证生成的sql是能够在对应数据表中执行并且出有效结果的,所以如果条件运算符是“==”的时候,那么条件值肯定会出现在数据表对应列的值之中,比如上述示例样本中,数据表的第一列肯定会有“世茂茂悦府”这个值,而通过这个信息我们也可以去校正预测结果。
模型结构 #
正式看本模型之前,读者不妨自己思考一番,想一下自己会怎么做。只有经过思考之后,才会明白其中的困难所在,也就这样才能理解本模型的一些处理技巧的要点。
本文的模型示意图如下:
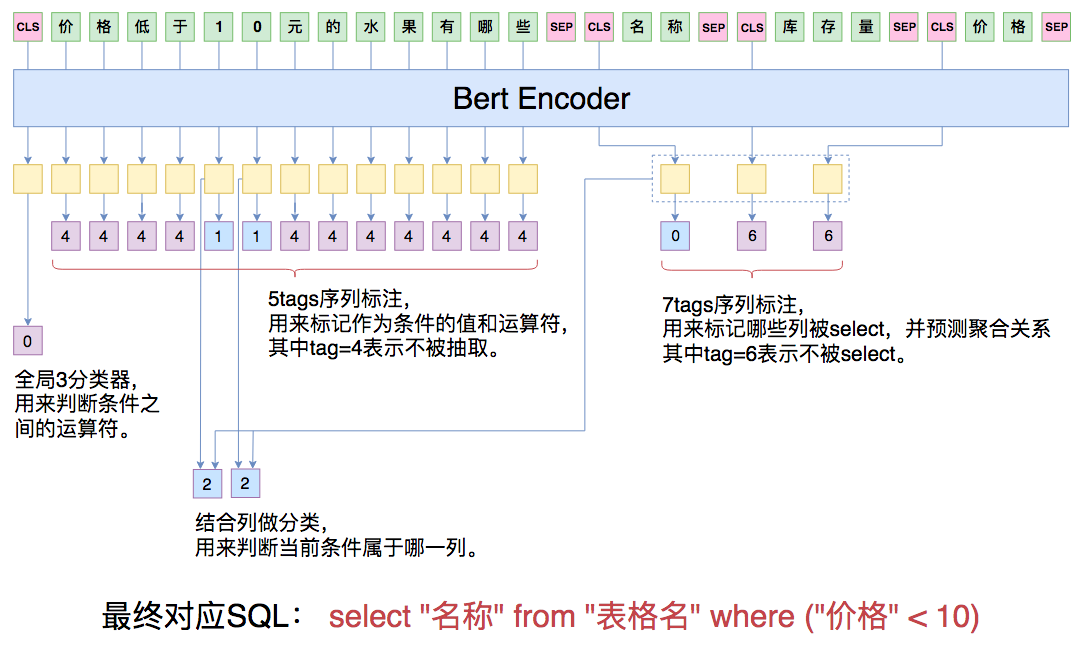
本文的NL2SQL模型示意图。主要包括4个不同的分类器:序列标注器
作为一个SQL,最基本的是要决定哪些列会被select,而每个表的列的含义均不一样,所以我们要将question句子连同数据表的所有表头拼起来,一同输入到Bert模型中进行实时编码,其中每一个表头也视为一个句子,用[CLS]***[SEP]括住。经过Bert之后,我们就得到了一系列编码向量,然后就看我们怎么去用这些向量了。
第一个[CLS]对应的向量,我们可以认为是整个问题的句向量,我们用它来预测conds的连接符。后面的每个[CLS]对应的向量,我们认为是每个表头的编码向量,我们把它拿出来,用来预测该表头表示的列是否应该被select。注意,此处预测有一个技巧,就是前面说了除了预测sel外,还要预测对应的agg,其中agg一共有6个类别,代表不同的距离运算,既然如此,我们干脆多增加一个类别,第7个类别代表着此列不被select,这样一来,每一列都对应着一个7分类问题,如果分到前6类,那么代表着此类被select而且同时预测到了agg,如果分到了第7类,那意味着此类不被select。
现在就剩下比较复杂的conds了,就是where col_1 == value_1这样子的,col_1、value_1以及运算符==都要找出来。conds的预测分两步,第一步预测条件值,第二步预测条件列,预测条件值其实就是一个序列标注问题,而条件值对应的运算符有4个,我们同样新增一类变成5类,第5类代表着当前字不被标注,否则就被标注,这样我们就能预测出条件值和运算符了。剩下的就是预测条件值对应的列,我们将标注出来的值的字向量跟每个表头的向量一一算相似度,然后softmax。我这里算相似度的方法是最简单的,直接将字向量和表头向量拼接起来,然后过一个全连接层后再接一个Dense(1),做得这么简单,一是因为本文主要目的是给出一个基本可行的demo而非一个完善的程序,需要留些改进空间给读者,二是因为做得复杂了,就很容易显存不足而OOM了。
顺便说一下,本文的模型是自己根据比赛任务“闭门造车”出来的,如果读者需要跟我讨论主流的NL2SQL模型,我可能就无能为力了,请见谅。
实验结果 #
本文的模型代码位于:
https://github.com/bojone/bert_in_keras/blob/master/nl2sql_baseline.py
注意,如果你执行此代码报错,那么你可能需要修改一下Keras的backend/tensorflow_backend.py,将sparse_categorical_crossentropy函数中原本是
logits = tf.reshape(output, [-1, int(output_shape[-1])])的那一行改为
logits = tf.reshape(output, [-1, tf.shape(output)[-1]])我已经向官方提了这个修正,并且已经通过了(请看这里),在未来的版本应该就自动包含这个特性了。
还是那句话,只要你认真地观察过比赛数据、独立思考过这个任务,上面本文介绍的模型其实很容易理解,而简单的模型能够有不错的效果,则得益于Bert强大的语义编码能力。在线下valid集上,本文的模型生成的SQL全匹配率大概为58%左右,而官方的评估指标是(全匹配率 + 执行匹配率) / 2,也就是说你有可能写出跟标注答案不同的SQL语句,但执行结果是一致的,这也算正确一半。
这样一来最终得分肯定会比58%要高,我估计是65%左右吧,我看了看当前榜单,如果65%的话还可以排在前几名(第一名的大佬现在是70%)。由于公司员工不允许打榜评测,所以我没参与过评测,也不知道线上提交会有多少,有兴趣试用的选手自行提交测试吧。
对了,要跑这个脚本最好有个1080ti或者以上的显卡,如果你没有那么多显存,你可以试着降低maxlen和batch size。还有,现在Bert可用的中文预训练权重有两个,一个是官方版的,一个是哈工大版的,两个的最终效果差不多,但是哈工大版的收敛更快。
纵观整个模型,在实现上,最困难的应当是要精细地考虑各种mask,在上述脚本中,xm, hm, cm是三个mask变量,就是要去除训练过程中padding部分带来的效应。注意mask不是Keras独有,不管你用Tensorflow还是Pytorch,理论上你都要仔细地处理好mask。如果读者实在读不懂mask部分,欢迎留言提问讨论,但是在提问之前,请你回答以下问题:
mask之前的序列大概是怎样的?mask之后序列的哪些位置发生了变化?变成了怎么样?
回答这个问题是证明“你已经能明白程序做了什么运算了,只是不明白为什么这样运算”。而如果你连这个运算本身都看不明白,我想我们很难沟通下去了(哪部分发生了变化总能知道吧...),还是好好学学Keras或者Tensorflow再来玩吧,不能想着一蹴而就。
前后处理 #
对于模型来说,实现的困难部分在于mask。不过如果看整个脚本的话,其实代码占比最多的就是数据的读取和预处理、结果的后处理这两部分罢了,真正搭建模型也就只有二十行左右(再次惊叹Keras的简洁和Bert的强大吧)。
其中我们说过条件值不一定出现在question中,那如何用对question字标注的方法来抽取条件值呢?
我的方法是,如果条件值不出现在question,那么我就对question分词,然后找出question的所有1gram、2gram、3gram,然后根据条件值找出一个最相近的ngram作为标注片段。而在预测的时候,如果找到了一个ngram作为条件值、并且运算符为==时,我们会判断这个ngram有没有在数据库出现过,如果有直接保留,如果没有则在数据库中找一个最相近的值。
相应的过程在代码中都有体现,欢迎细读。
文章小结 #
欢迎大家来玩~

首届中文NL2SQL挑战赛
祝大家取得好成绩!
转载到请包括本文地址:https://kexue.fm/archives/6771
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 29, 2019). 《 基于Bert的NL2SQL模型:一个简明的Baseline 》[Blog post]. Retrieved from https://kexue.fm/archives/6771
@online{kexuefm-6771,
title={ 基于Bert的NL2SQL模型:一个简明的Baseline},
author={苏剑林},
year={2019},
month={Jun},
url={\url{https://kexue.fm/archives/6771}},
}

July 2nd, 2019
这个模型放到测试集 test上效果比较差。是不是过拟合了
这只能是你自己训练的问题,请自行反思。因为后面我请同事帮忙测了,test比valid还高。
July 2nd, 2019
苏神请问为什么hm是[1] * len(h)呢?
pcsel = Lambda(lambda x: x[0][..., 0] - (1 - x[1]) * 1e10)([pcsel, hm])
这里pcsel[0][..., 0]的shape是(x_len, h_len),hm是(1,h_len),
通过广播最后的shape也是(x_len, h_len),但因为pcsel的列数本来就是h_len,这一步好像并没有效果,好像没有真的mask。
如果我上面的理解没错的话,我觉得hm应该是[1] * h[0] + [0] * (maxlen - h[0]),这样mask操作就会在:(x_len, h_len)的垂直方向发生(下半矩阵),mask掉那些不属于question的字。
请问是这样吗,还是我哪里理解错了qaq
理解到这个程度很不错。
你有这个误解,是因为你没看清楚h是什么,h变量就是当前样本的所有headers而已,自然就有hm=[1] * len(h),满了一个batch后,HM是一个不定长的list,通过seq_padding变为统一长度的,这时候才把多余的0补上,作为真正padding的标记。
July 3rd, 2019
这里已经Dense(1)然后跟x4h相加过了所以pcsel是(?, x_len, h_len, 1),(BTW代码好像是分别Dense(1)完相加,而不是上面说的拼接再Dense(1)是吗)
d = Dense(1)(a) + Dense(1)(b)
在数学上完全等价于
c = Concatenate()([a, b])
d = Dense(1)(c)
但是第一种写法会更省显存。
July 3rd, 2019
很奇怪楼主只是使用了train.tables.json 中的 header,而没有使用 rows;
我的想法:
1. 使用 question 和 rows 做分类,使用SEL 和 AGG 数据训练,得到判别问题答案和答案agg 属性的模型
2. 使用 question 和 header做分类, 使用cond_conn_op和 conds 数据训练,得到选择条件和条件属性以及问题实体抽取的模型
老粉了,请指教~
充分结合table里边的value本身是一件比较困难的事,也不好写,本文旨在提供一个比官方baseline更好更易用的keras baseline罢了,不做得太细致。
July 4th, 2019
苏神请问训练的时候超过maxlen的可以continue,evaluate的时候超过了应该怎么办呢
不超过512还是可以直接跑,超过直接截断,要不就分段传入。
July 8th, 2019
请问下苏神,如果不改后端有什么操作可以避免出错吗?谷歌colab改不了后端代码
自己在脚本中,重新定义一个sparse_categorical_crossentropy函数,把后端(按照本文提示更正后的)sparse_categorical_crossentropy的代码抄一遍,然后作为loss就行了。
好的,谢苏神!
July 8th, 2019
请问苏神的框架版本?
我是tf1.4
会报错 AttributeError: module 'tensorflow' has no attribute 'batch_gather'
这个模型的实验版本是tf 1.13
请问苏神如果不升级tf版本,有什么方式能自己实现这个方法吗?
那我不清楚~
July 9th, 2019
请问一个很简单的问题,
pcsel = Lambda(lambda x: x[0][..., 0] - (1 - x[1]) * 1e10)([pcsel, hm])
这行减去1e10,是因为后面接了个softmax ,这样exp{-1e10}就约等于0,我这样理解对吗
对
July 11th, 2019
感谢你的分享,我有一个疑问,在nl2sql(question, table)函数里变量v_str没有声明就被引用,但是因为这个条件永远不会进入,所以一直没有报错,但是不知道这个v_str有什么作用?谢谢
if j != num_op - 1:
if v_op != j:
if v_op != -1:
v_end = v_start + len(v_str)
csel = pcsel[0][v_start: v_end].mean(0).argmax()
conds.append((csel, v_op, v_str))
有引入,因为v_str = question[i - 1]这一句必然会先被执行,然后才可能是v_str += question[i - 1]或者v_end = v_start + len(v_str)那两句。
明白了,谢谢!
你好,冒昧再请教下,因为bert是基于word进行分词的,损失了很多上下文的关系,如果我在mask的时候,基于命名实体识别,把一些不要的词语mask掉(例如stop word),那么准确率是否可能会提升呢?
没看懂你说什么...
1、中文bert是基于字的;
2、“基于word进行分词”,跟“损失了很多上下文的关系”有什么关系?
July 12th, 2019
苏神,请问_x1, _x2 = tokenizer.encode(j)中_x2的作用是什么,我试了下这个x2以及代码中所有用到的x2都是零向量,不清楚起到什么作用。
事实上x2是用来分句的,但你也可以不用太关心,直接传入全零就是了。
对,这里相当于没有分句,我传入1试了下,反而在val上变差了,有点想不通