






31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 99484位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
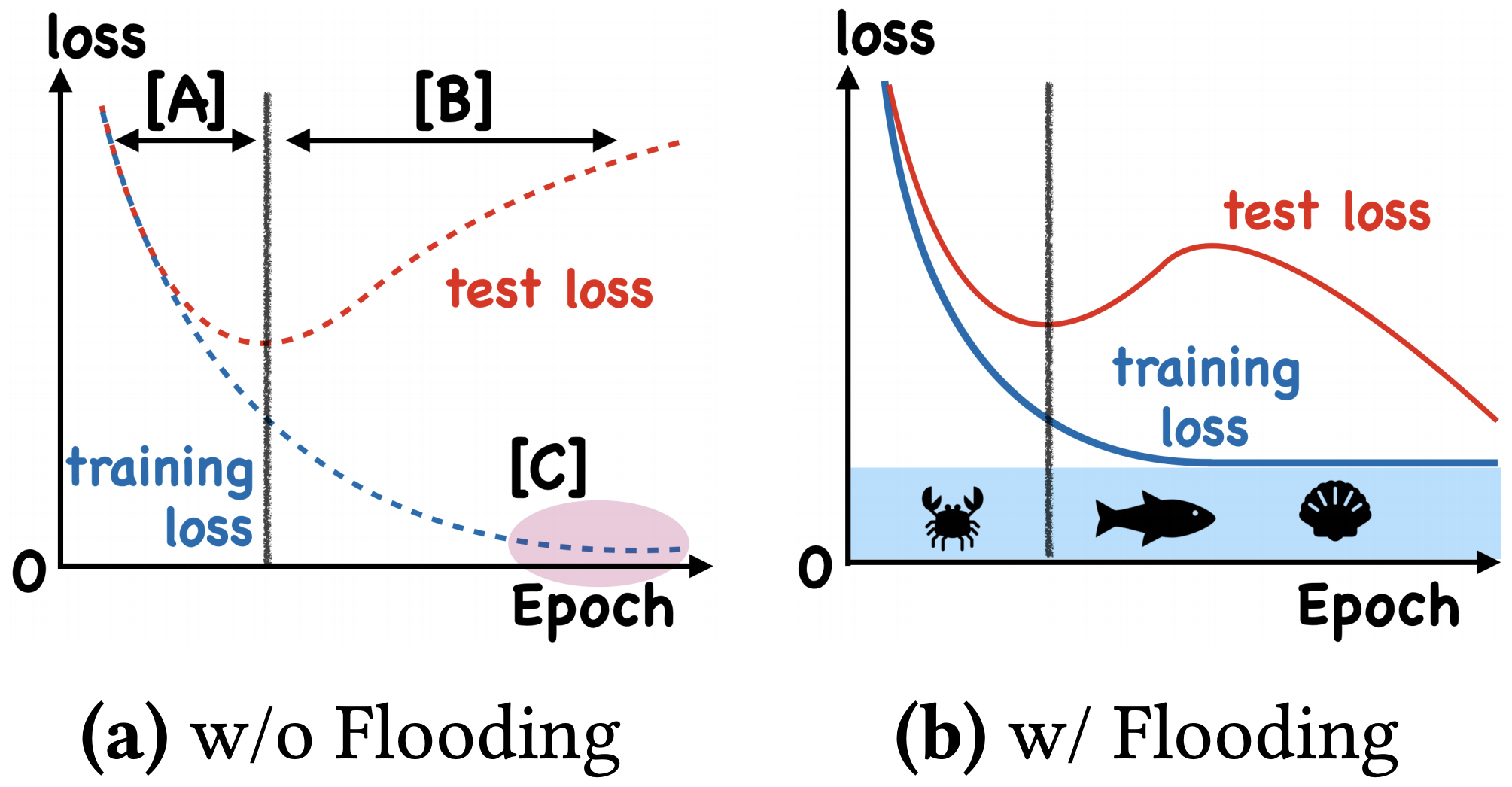
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图
1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 132791位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如$L_1, L_2$惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为$f(x)$,$\mathcal{D}$为训练数据集合,$l(f(x), y)$为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
$\theta$是$f(x)$里边的可训练参数。假如往模型输入添加噪声$\varepsilon$,其分布为$q(\varepsilon)$,那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重$\theta$,甚至可以是输出$y$(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,$q(\varepsilon)$的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布$U([0,1])$或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
1
Mar
对抗训练浅谈:意义、方法和思考(附Keras实现)
By 苏剑林 | 2020-03-01 | 323485位读者 | 引用当前,说到深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。本博客里以前所涉及的对抗话题,都是前一种含义,而今天,我们来聊聊后一种含义中的“对抗训练”。
本文包括如下内容:
1、对抗样本、对抗训练等基本概念的介绍;
2、介绍基于快速梯度上升的对抗训练及其在NLP中的应用;
3、给出了对抗训练的Keras实现(一行代码调用);
4、讨论了对抗训练与梯度惩罚的等价性;
5、基于梯度惩罚,给出了一种对抗训练的直观的几何理解。
7
Oct
深度学习中的Lipschitz约束:泛化与生成模型
By 苏剑林 | 2018-10-07 | 198213位读者 | 引用前言:去年写过一篇WGAN-GP的入门读物《互怼的艺术:从零直达WGAN-GP》,提到通过梯度惩罚来为WGAN的判别器增加Lipschitz约束(下面简称“L约束”)。前几天遐想时再次想到了WGAN,总觉得WGAN的梯度惩罚不够优雅,后来也听说WGAN在条件生成时很难搞(因为不同类的随机插值就开始乱了...),所以就想琢磨一下能不能搞出个新的方案来给判别器增加L约束。
闭门造车想了几天,然后发现想出来的东西别人都已经做了,果然是只有你想不到,没有别人做不到。主要包含在这两篇论文中:《Spectral Norm Regularization for Improving the Generalizability of Deep Learning》和《Spectral Normalization for Generative Adversarial Networks》。
所以这篇文章就按照自己的理解思路,对L约束相关的内容进行简单的介绍。注意本文的主题是L约束,并不只是WGAN。它可以用在生成模型中,也可以用在一般的监督学习中。
L约束与泛化
扰动敏感
记输入为$x$,输出为$y$,模型为$f$,模型参数为$w$,记为
$$\begin{equation}y = f_w(x)\end{equation}$$
很多时候,我们希望得到一个“稳健”的模型。何为稳健?一般来说有两种含义,一是对于参数扰动的稳定性,比如模型变成了$f_{w+\Delta w}(x)$后是否还能达到相近的效果?如果在动力学系统中,还要考虑模型最终是否能恢复到$f_w(x)$;二是对于输入扰动的稳定性,比如输入从$x$变成了$x+\Delta x$后,$f_w(x+\Delta x)$是否能给出相近的预测结果。读者或许已经听说过深度学习模型存在“对抗攻击样本”,比如图片只改变一个像素就给出完全不一样的分类结果,这就是模型对输入过于敏感的案例。

最近评论