






30
May
最小熵原理(三):“飞象过河”之句模版和语言结构
By 苏剑林 | 2018-05-30 | 78005位读者 |在前一文《最小熵原理(二):“当机立断”之词库构建》中,我们以最小熵原理为出发点进行了一系列的数学推导,最终得到$(2.15)$和$(2.17)$式,它告诉我们两个互信息比较大的元素我们应该将它们合并起来,这有利于降低“学习难度”。于是利用这一原理,我们通过邻字互信息来实现了词库的无监督生成。
由字到词、由词到词组,考察的是相邻的元素能不能合并成一个好“套路”。可是套路为什么非得要相邻的呢?当然不一定相邻,我们学习语言的时候,不仅仅会学习到词语、词组,还要学习到“固定搭配”,也就是说词语怎么运用才是合理的,这是语法的体现,是本文所要探究的,希望最终能达到一定的无监督句法分析的效果。
由于这次我们考虑的是跨邻词的语言关联,因此我给它起个名字为“飞象过河”,正是
“套路宝典”第二式——“飞象过河”
语言结构 #
对于大多数人来说,并不会真正知道什么是语法,他们脑海里就只有一些“固定搭配”、“定式”,或者更正式一点可以叫“模版”。大多数情况下,我们是根据模版来说出合理的话来。而不同的人的说话模版可能有所不同,这就是个人的说话风格,甚至是“口头禅”。
句模版 #
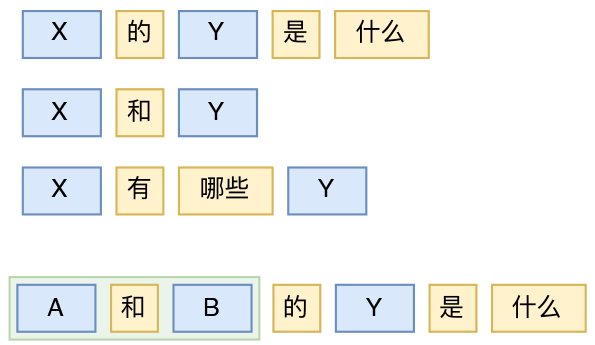
比如,“X的Y是什么”就是一个简单的模版,它有一些明确的词语“的”、“是”、“什么”,还有一些占位符X、Y,随便将X和Y用两个名词代进去,得到的就是合乎语法的句子(合不合事实,那是另外一回事了)。这类模版还可以举出很多,“X和Y”、“X的Y”、“X可以Y吗”、“X有哪些Y”、“X是Y还是Z”等等。
句模版及其相互嵌套示例
当然,虽然可以抽取尽可能多的模版,但有限的模版是无法覆盖千变万化的语言想象的,所以更重要的是基于模版的嵌套使用。比如“X的Y是什么”这个模版,X可以用模版“A和B”来代替,从而得到“(A和B)的Y是什么”。如此以来,模版相互嵌套,就可以得到相当多句子了。
等价类 #
接着,有了模版“X的Y是什么?”之后,我们怎么知道X和Y分别可以填些什么呢?
刚才我们说“随便用两个名词”代进去,可是按照我们的思路,到现在为止我们也就只会构建词库,我们连什么是“名词”都不知道,更不知道应该把名词填进去。事实上,我们不需要预先知道什么,我们可以通过大料的语料来抽取每个候选位置的“等价类”,其中X的候选词组成一个词语等价类,Y的候选词也组成一个词语等价类,等等。
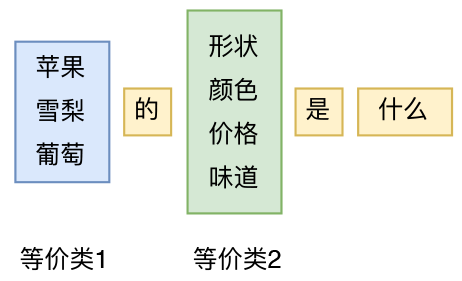
句模版及等价类的概念
当然,这样的设想是比较理想的,事实上目前我们能获取的生语料情况糟糕得多,但不管怎样,万丈高楼平地起,我们先解决理想情况,实际使用时再去考虑一般情况。
下面我们来逐一探究如何从大量的原始语料获取句模版,并考虑如何识别句子中所用到的句模版,甚至挖掘出句子的层次结构。
生成模版 #
事实上,有了前一文的构建词库的经验,事实上就不难构思生成句子模版的算法了。
在构建词库那里,我们的统计对象是字,现在我们的统计对象是词,此外,词语是由相邻的字组成的,但句子模版却未必是由相邻的词组成的(否则就退化为词或词组),所以我们还要考虑跨词共现,也就是Word2Vec中的Skip Gram模型。
有向无环图 #
有向无环图(Directed Acyclic Graph,DAG)其实是NLP中经常会遇到的一个图论模型。事实上,一元分词模型也可以直接抽象为有向无环图上的最短路径规划问题。而这里的候选模版集构建,也需要用到有向无环图。
因为考虑了Skip Gram模型,因此我们可以把句子内比较“紧凑”(互信息比较大)的“词对”连接起来,用图论的角度看,这就构成了一个“有向无环图”:

句子及Skip Gram关系构成的有向无环图
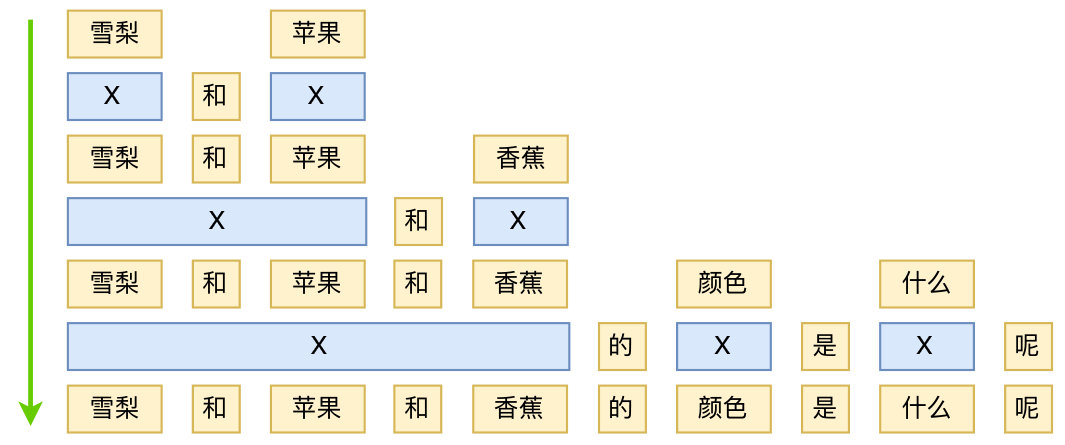
我们直接将图上的所有路径都取出来,如果跨过了相邻节点,那么就插入一个占位符(下面全部用X表示占位符),这样就可以得到候选模版集了。比如从上图中,抽取到的候选模版为:
计算机 X 鼠标 X
X 的 X 有 什么 X 的 X 呢
X 的 X 有 什么 X 呢
X 比较 X
算法步骤 #
我们可以把上述流程具体描述如下:
1、将语料按句子切分,并分词;
2、选定一个窗口大小window,从语料中统计每个词的频率($p_a,p_b$),以及在窗口大小内中任意两词的共现频率($p_{ab}$);
3、分别设定出现频率的阈值$min\_prob$和互信息的阈值$min\_pmi$;
4、遍历所有句子:
4.1、对每个句子构建一个图,句子中的词当作图上的点;
4.2、句子中窗口内的词对$(a,b)$,如果满足$p_{ab} > min\_prob$和$\ln\frac{p_{ab}}{p_a p_b} > min\_pmi$,那么就给图上添加一条“a-->b”的有向边;
4.3、找出图上所有的路径(孤立点也算路径),作为候选模版加入统计。5、统计各个“准模版”的频率,将“准模版”按频率降序排列,取前面部分即可。
这个算法既可以用来句模版的抽取,也可以简单地用来做词组(短语)的抽取,只需要将window设为1。因此它也就基本上包含了前一文所说的词库构建了,所以上述算法是一个一般化的抽取框架。
效果演示 #
下面是从百度知道的问题集中抽取出来的一些句模版(数字是统计出来的频数,可以忽略):
< Template: [X] 的 [X] > 20199
< Template: [X] 吗 > 9695
< Template: [X] 是 [X] > 5358
< Template: [X] 的 > 3979
< Template: [X] 和 [X] > 3919
< Template: 我 [X] > 3766
< Template: [X] 有 [X] > 3568
< Template: [X] 了 > 2910
< Template: [X] 了 [X] > 2702
< Template: [X] 怎么 [X] > 2340
< Template: [X] 到 [X] > 2254
< Template: [X] 在 [X] > 2234
< Template: [X] 我 [X] > 2147
< Template: [X] 不 [X] > 1708
< Template: 求 [X] > 1547
< Template: [X] 怎么样 > 1371
注意,事实上“X 的 X”、“X 怎么 X”这种两个占位符夹住一个词的模版是平凡的,它只不过是告诉我们这个词可以插入到句子中使用。因此,为了看出效果,我们排除掉这一类模版,得到:
< Template: [X] 吗 > 9695
< Template: [X] 的 > 3979
< Template: 我 [X] > 3766
< Template: [X] 了 > 2910
< Template: 求 [X] > 1547
< Template: [X] 怎么样 > 1371
< Template: [X] 啊 > 1324
< Template: 有 [X] > 1319
< Template: [X] 怎么办 > 1232
< Template: 为什么 [X] > 1220
< Template: 请问 [X] > 1189
< Template: [X] 呢 > 1099
< Template: [X] 么 > 1003
< Template: 谢谢 > 997
< Template: 怎么 [X] > 903
< Template: 在 [X] > 894
< Template: 现在 [X] > 874
< Template: 如何 [X] > 867
< Template: [X] 好 > 798
< Template: [X] 是 [X] 意思 > 728
< Template: 是 [X] > 727
< Template: [X] 是什么意思 > 721
< Template: [X] 是什么 > 684
< Template: 怎么办 > 589
< Template: 有没有 [X] > 582
< Template: [X] 多少钱 > 550
< Template: 从 [X] > 526
< Template: 什么 [X] > 522
< Template: [X] 有哪些 > 490
< Template: [X] 是什么 [X] > 483
从结果来看,我们的句模版生成算是确实是有效的。因为这些句模版就有助于我们发现语言的使用规律了。比如:
1、“X吗”、“X了”、“X怎么样”这些模版的占位符出现在前面,说明这些词可以放在问句的末尾(我们用到的语料是问句);
2、“我X”、“求X”、“为什么X”、“请问X”等模版的占位符出现在后面,说明这些词可以放到问句的开头;
3、“谢谢”、“怎么办”这类模版并没有出现占位符,表明它可以单独成句;
4、“X是X意思”、“X是什么X”等模版则反映了语言的一些固定搭配。
用通用的观点看,这些模版所描述的都是句法级的语言现象。当然,为了不至于跟目前主流的句法分析混淆,我们不妨就称为语言结构规律,或者直接就称为“句模版”。
结构解析 #
跟分词一样,当构建好句子模版后,我们也需要有算法来识别句子中用到了哪些模版,也只有做到了这一步,才有可能从语料中识别出词语的等价类出来。
回顾分词算法,分词只是一个句子的切分问题,切分出来的词是没有“洞”(占位符)的,而如果要识别句子中用了哪些模版,这些模版是有“洞”的,并且还可能相互嵌套,这就造成了识别上的困难。然而,一旦我们能够完成这个事情,我们就得到了句子的一个层次结构分解,这是非常有吸引力的目标。
投射性假设 #
为了实现对句子的层次分解,我们首先可以借鉴的是句法分析一般都会使用的“投射性(projective)假设”。
语言的投射性大概意思是指如果句子可以分为几个“语义块”,那么这些语义块是不交叉的。也就是说,假如第1、2、3个词组成一个语义块、第4、5个词组成一个语义块,这种情况是允许的,而第1、2、4个词组成一个语义块、第3、5个词组成一个语义块,这种情况是不可能的。大多数语言,包括汉语和英语,基本上都满足投射性。
结构假设 #
为了完成句子的层次结构分解,我们需要对句子的组成结构做更完整的假设。受到投射性假设的启发,笔者认为可以将句子的结构做如下假设:
1、每个语义块是句子的一个连续子字符串,句子本身也算是一个语义块;
2、每个语义块由一个主的句模版生成,其中句模版的占位符部分也是一个语义块;
3、每个单独的词可以看成是一个平凡的句模版,也可以看成是一个最小粒度的语义块。
说白了,这三点假设可以归纳为一句话:
每个句子是由句模版相互嵌套生成的。
咋看之下这个假设不够合理,但仔细思考就会发现,这个假设已经足够描述大多数句子的结构了。读者可能有疑虑的是“有没有可能并行地使用两个句模版,而不是嵌套”?答案是:应该不会。因为如果出现这种情况,只需要将“并行”本身视为一个模版就行了,比如将“X和X”也视为一个模版,那么“X和X”这个模版中的两个语义块就是并行的了,甚至它可以与自身嵌套得到“X和(X和X)”描述更多的并行现象。
也正因为我们对语言结构做了这种假设,所以一旦我们识别出某个句子的最优句模版组合,我们就得到了句子的层次结构——因为根据假设,模版是按照嵌套的方式组合的,嵌套意味着递归,递归就是一种层次树的结构了。
分解算法 #
有了对句子结构的假设,我们就可以描述句模版识别算法了。首先来重述一下分词算法,一元分词算法的思路为
对句子切分成词,使得这些词的概率对数之和最大(信息量之和最小)。
它还可以换一种表述如下:
找一系列的词来不重不漏地覆盖句子中的每个字,使得这些词的概率对数之和最大(信息量之和最小)。
以往我们会认为分词是对句子进行切分,这种等价的表述则是反过来,要对句子进行覆盖。有了这个逆向思维,就可以提出模版识别算法了:
找一系列的句模版来不重、不漏、不交叉地覆盖句子中的每个词,使得这些模版的概率对数之和最大(信息量之和最小)。
当然,这只是思路,在实现过程中,主要难点是对占位符的处理,也就是说,句子中的每个词既代表这个词本身,也可以代表占位符,这种二重性使得扫描和识别都有困难。而不幸中的万幸是,如果按照上面所假设的语言结构,我们可以转化为一个递归运算:
最优的结构分解方案中,主模版下的每个语义块的分解方案也是最优的。
句子的层次结构解析,包含了句模版的嵌套调用
因此我们可以得到算法:
1、扫描中句子中所有可能出现的模版(通过Trie树结构可以快速扫描);
2、每种分解方案的得分,等于句子的主模版得分,加上每个语料块的最优分解方案的得分。
结果展示 #
下面是一些简单例子的演示,是通过有限的几个模版进行的分析,可以看到,的确初步实现了句子的层次结构解析。
+---> (鸡蛋)可以(吃)吗
| +---> 鸡蛋
| | +---> 鸡蛋
| +---> 可以
| +---> 吃
| | +---> 吃
| +---> 吗
+---> (牛肉鸡蛋)可以(吃)吗
| +---> 牛肉鸡蛋
| | +---> 牛肉
| | +---> 鸡蛋
| +---> 可以
| +---> 吃
| | +---> 吃
| +---> 吗
+---> (苹果)的(颜色)是(什么)呢
| +---> 苹果
| | +---> 苹果
| +---> 的
| +---> 颜色
| | +---> 颜色
| +---> 是
| +---> 什么
| | +---> 什么
| +---> 呢
+---> (雪梨和苹果和香蕉)的(颜色)是(什么)呢
| +---> (雪梨和苹果)和(香蕉)
| | +---> (雪梨)和(苹果)
| | | +---> 雪梨
| | | | +---> 雪梨
| | | +---> 和
| | | +---> 苹果
| | | | +---> 苹果
| | +---> 和
| | +---> 香蕉
| | | +---> 香蕉
| +---> 的
| +---> 颜色
| | +---> 颜色
| +---> 是
| +---> 什么
| | +---> 什么
| +---> 呢
当然,不能报喜不报忧,也有一些失败的例子:
+---> (我的美味)的(苹果的颜色)是(什么)呢
| +---> (我)的(美味)
| | +---> 我
| | | +---> 我
| | +---> 的
| | +---> 美味
| | | +---> 美味
| +---> 的
| +---> (苹果)的(颜色)
| | +---> 苹果
| | | +---> 苹果
| | +---> 的
| | +---> 颜色
| | | +---> 颜色
| +---> 是
| +---> 什么
| | +---> 什么
| +---> 呢
+---> (苹果)的(颜色)是(什么的意思是什么)呢
| +---> 苹果
| | +---> 苹果
| +---> 的
| +---> 颜色
| | +---> 颜色
| +---> 是
| +---> (什么)的(意思)是(什么)
| | +---> 什么
| | | +---> 什么
| | +---> 的
| | +---> 意思
| | | +---> 意思
| | +---> 是
| | +---> 什么
| | | +---> 什么
| +---> 呢
失败的例子我们后面再分析。
文章总结 #
看到一脸懵逼的,有各种话要吐槽的,还请先看到这一节哈~
拼图游戏 #
从词、词组都句模版,我们都像是在玩拼图:拼着拼着发现这两块合在一起效果还行,那么就将它合起来吧。因为将互信息大的项合起来,作为一个整体来看,就有助于降低整体的信息熵,也就能降低整体的学习难度。
对于句模版,如果在中文的世界里想不通,那么就回顾一下我们在小学、初中时学英语是怎么学过来的吧,那会我们应该学习了很多英语的句模版~
有什么用 #
“句模版”算是本文提出的新概念,用它来识别语言结果也算是一种新的尝试。读者不禁要问:这玩意有什么用?
我想,回答这个问题的最好方式,是引用牛顿的一段话:
我自己认为,我好像只是一个在海边玩耍的孩子,不时为捡到比通常更光滑的石子或更美丽的贝壳而欢欣,而展现在我面前的是完全未被探明的真理之海。
我引用这段话是想表明,做这个探究的最根本原因,并不是出于某种实用目的,而是为了纯粹地探究自然语言的奥秘。
当然,如果与此同时,研究出来的结果能具备一定的应用价值,那就更加完美了。从现在的结果来看,这种应用价值可能是存在的。因为我们在NLP中,面对的句子千变万化,但事实上“句式”却是有限的,这也意味着句模版也是有限的,如果有必要,我们可以对各个句模板的占位符含义进行人工标注,这就能将句模板的结构跟常规的句法描述对应起来了。通过有限的句模版来对句子进行(无限的)分解,能让NLP可面对的场景更加灵活多变一些。
也许以往的传统自然语言处理中,也出现过类似的东西,但本文所描述的内容纯粹是无监督的结果,并且也有自洽的理论描述,算是一个比较完整的框架,初步的结果也差强人意,因此值得进一步去思考它的应用价值。
艰难前进 #
浏览完这篇文章,读者最大的感觉也许是“一脸懵逼”:能再简化一点吗?
要回答这个问题,就不得不提到:距离这个系列的上一篇文章已经过了一个多月,这篇文章才正式发出,这似乎有点久了?从形式上看,本文只不过是前文的简单推广:不就是将相邻关联推广到非相邻关联吗?
的确,形式上确实如此。但为了将这个想法推广至同时具备理论和实用价值,却并不是那么简单和顺畅的事情。比如,在句模版生成时,如何不遗漏地得到所有的候选模版,这便是一个难题;其次,在得到句模版(不管是自动生成还是人工录入)后,如何识别出句子中的句模版,这更加艰难了,不论在理论思考还是编程实现上,都具有相当多的障碍,需要对树结构、递归编程有清晰的把握。我也是陆陆续续调试了半个多月,才算是把整个流程调通了,但估计还不完备。
所以,你看得一脸懵逼是再正常不过了,我自己做完、写完这篇文章,还感觉很懵呢~
改进思路 #
在结果结果展示一节中,我们也呈现一些失败的例子。事实上,失败的例子可能还更多。
我们要从两个角度看待这个事情。一方面,我们有成功的例子,对应纯粹无监督挖掘的探索,我们哪怕只能得到一小部分成功的结果,也是值得高兴的;另外一方面,对于失败的例子,我们需要思考失败的原因,并且考虑解决方案。
笔者认为,整体的句模版思路是没有问题的,而问题在于我们没有达到真正的语义级别的理解。比如第一个失败的例子,结果是
(我的美味)的(苹果的颜色)是(什么)呢
我们能说这个分解完全错吗?显然不是,严格来讲,这种分解在语法上并没有任何错误,只是它不符合语义,不符合我们的常识。因此,并非是句模版的错,而是还不能充分地结合语义来构建句模版。
回顾目前主流的句法分析工作,不管是有监督的还是无监督的,它们基本上都要结合“词性”来完成句法分析。所以这给我们提供了一个方向:最小熵系列下一步的工作就是要探究词语的聚类问题,以便更好地捕捉词义和语言共性。
转载到请包括本文地址:https://kexue.fm/archives/5577
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (May. 30, 2018). 《最小熵原理(三):“飞象过河”之句模版和语言结构 》[Blog post]. Retrieved from https://kexue.fm/archives/5577
@online{kexuefm-5577,
title={最小熵原理(三):“飞象过河”之句模版和语言结构},
author={苏剑林},
year={2018},
month={May},
url={\url{https://kexue.fm/archives/5577}},
}

May 31st, 2018
不出所料,看完确实是懵的……
June 2nd, 2018
我只想说: 不明觉厉
June 11th, 2018
苏老师你好,我对NLP无监督方向颇感兴趣,目前在baidu从事相关算法研究与开发。我之前开发了一些无监督NLP算法已经实用,包括:半自动文本分类问题标注平台,自动分词训练数据标注算法,半自动机构名NER标注算法等等,最近一直拜读你写的文章,感觉有不少类似的思考和工作方向,期待和苏老师多多交流沟通。
幸会幸会,一定多交流~
June 24th, 2018
这不就是CKY依存语法的构建嘛?
December 13th, 2019
想问下博主,有没有这一块的代码和数据集,看完后很想自己实现一下。
https://kexue.fm/archives/5597
February 15th, 2022
感觉句式发现对一些舆情跟风会很有用,感谢分享,不过想要能落地的应用还比较难
November 17th, 2023
苏神,这一系列的分析其实就是为了探索自然语言的语义,从语义级别对自然语言建模。但是在通信发展中,Shannon认为通信是一个工程问题,不涉及语义,因此才有如此好的数学抽象,概率论才能描述信息。如果从语义级别考虑,问题就要复杂很多,单纯从概率统计的角度很难很好的描述语义,即知识图谱很难对自然语言建模。
目前大模型盛行之下,大家统一认为不要用知识图谱,即不要去做那些统计的工作,而要直接用Transformer对语言建模。当然也有一些工作是模型外接知识图谱来做,这种模型一般我们认为是没训练好。苏神认为,基于统计的语言模型和完全基于ANN的语言模型,到底该如何取舍折衷?
大模型有一种解释(或者说信仰)是“压缩就是智能”。
最小熵原理说的是文明的方向是最小熵的方向。熵是最小描述长度,最小熵就是最小化总描述长度,也就是最大化压缩率。所以最小熵原理实质也是“压缩就是智能”。
两者的目的是完全一样的,只是过程不一样,是统计还是神经网络都无所谓。比如最近写的bytepiece分词:https://kexue.fm/archives/9752 ,原理也是基于统计进行最大化压缩率,它也可以作为LLM的基础组件(即tokenizer)。
至于知识图谱,它并不是一个统计的结果,是完全由人主观抽象出来的知识,我并不看好,也觉得没必要。因为很多知识图谱也是规则提炼出来,也有错的风险,大模型也有错的风险,大家半斤八两,何必要熵知识图谱。当然,直觉上知识图谱的更正会方便很多,但这只是目前我们对大模型的编辑还了解的不够充分而已。